Debugging: Tecniche e Tool
|
|
Dr. Carlo Pescio Debugging: Tecniche e Tool |
Pubblicato su Computer Programming No. 43
In questo articolo ci occuperemo degli erroriche vengono introdotti in fase di codifica; in particolare, vedremo quali tecniche e quali strumenti sono disponibili per coadiuvare il programmatore nel compito di scrivere programmi privi di errori, e di individuare ed eliminare gli errori esistenti
Introduzione
Lo sviluppo del software è una attività molto complessa, e come tale inevitabilmente soggetta ad errori; in particolare, possiamo evidenziare due grandi classi di problemi all’interno del processo di sviluppo: quelli derivanti da una specifica dei requisiti inesatta, ed i difetti nell’implementare una corretta specifica dei requisiti. I primi vengono introdotti sin dall’inizio dello sviluppo (fase di analisi) e come tali sono estremamente dannosi, in quanto si ripercuotono su tutte le successive fasi (design, implementazione) sino a quando non emergono dall’inadeguatezza del sistema a realizzare alcuni compiti. I secondi vengono introdotti in fasi più avanzate, quindi di design o codifica, in seguito a fenomeni diversi, che vanno dalla scarsa conoscenza del linguaggio, ad assunzioni non verificate, alla schiacciante complessità del progetto, sino alla semplice distrazione.
In questo articolo ci occuperemo degli errori, comunemente chiamati bug, che vengono introdotti in fase di codifica; in particolare, vedremo quali tecniche e quali strumenti sono disponibili per coadiuvare il programmatore nel compito di scrivere programmi privi di errori, e di individuare ed eliminare gli errori esistenti. Queste attività vengono normalmente indicate con il termine debugging; talvolta, anche la fase di testing viene considerata come parte dell’eliminazione degli errori. Più correttamente, la fase di testing corrispone alla ricerca degli errori, mentre con debugging si indica l’insieme di tecniche per l’eliminazione degli errori stessi; tecniche che, nella migliore tradizione, includongo anche metodi di prevenzione e controlli di tipo statico. È infatti superfluo ricordare che una buona tecnica di programmazione deve ridurre il tempo passato a ricercare bug: programmare rapidamente solo per passare il restante tempo di sviluppo all’interno del debugger è raramente una tecnica vincente.
Controlli statici del codice
Proprio dal concetto di prevenzione nascono una serie di tool dedicati all’analisi statica (ovvero prima della compilazione, e comunque operata sul sorgente e non sugli eseguibili), alla ricerca di potenziali errori o di costrutti pericolosi. Uno degli strumenti più diffusi è certamente lint [1] [2], disponibile sia in ambiente Unix che sulla maggior parte dei personal, che contiene al suo interno una vasta conoscenza dei più comuni errori di programmazione in linguaggio C. D’altra parte, molti dei compilatori moderni contengono al loro interno efficaci metodi di analisi, che consentono di emettere dei warning in molte occasioni, seppure senza la completezza di un verificatore come lint.
In realtà, un errore molto comune è quello di ignorare o di disabilitare i warning del compilatore: chi desidera scrivere programmi in modo professionale dovrebbe sempre guardarsi bene dal farlo. A meno che il vostro compilatore non sia di qualità realmente infima, un warning è sempre motivato dall’uso di un costrutto pericoloso, o di una tecnica di programmazione poco chiara, che "inganna" il compilatore. In entrambi i casi, il tempo speso per eliminare la ragione del warning dal codice sarà più che ricompensato in fase di testing, manutenzione, e futura comprensione del codice.
Esistono naturalmente altri tool per la verifica statica del codice: alcuni (come CodeCheck di Abraxis Software) sono anche in grado di verificare l’aderenza del codice stesso con "norme stilistiche" imposte dall’organizzazione; altri sono specializzati per identificare un tipo particolare di errori, ad esempio quelli nelle macro del linguaggio C [3]. Strumenti per la verifica statica esistono ovviamente anche per altri linguaggi: va comunque notato che il linguaggio C, per la sua diffusione, è forse quello più fornito di strumenti di debugging.
Ispezioni
Per contro, alcuni linguaggi non dispongono di efficaci strumenti di verifica statica; ed in ogni caso, se usate uno strumento tipo lint dovete essere preparati a gestire numerosi segnali di potenziali errori anche in codice perfettamente funzionante: a differenza di un compilatore, lint tende spesso ad eccedere nella segnalazione di costrutti "pericolosi".
Inoltre, uno strumento di analisi statica si affida semplicemente alla conoscenza di alcuni pattern "a rischio", ma non può in alcun modo cercare di comprendere la logica di un programma, verificare la conformità del codice con i commenti, e così via. Questo è invece possibile per un essere umano: si tratta però di una tecnica poco praticata, per quanto esistano diversi test che ne confermano l’efficacia.
Il meccanismo delle ispezioni del codice, formalizzato all’interno dei laboratori IBM [4], consiste nel sottoporre all’analisi di altri sviluppatori delle porzioni di codice, normalmente circa duemila righe alla volta, dopo aver brevemente spiegato le funzionalità e le tecniche utilizzate. Ogni sviluppatore verifica poi il codice alla ricerca di errori o di costrutti pericolosi; ad esempio, errori di off-by-one nell’accesso agli array, casi limite non gestiti, dereferenziazione di puntatori non validi, memory leaks, e così via; se usata in parallelo a verifiche statiche e dinamiche, l’ispezione può spesso essere limitata alla ricerca di errori a livello logico. Questa tecnica, che ha spesso risultati eccellenti in termini di errori trovati, ha il grande problema di richiedere un ambiente umano cooperativo, privo di attriti e di programmatori facili ad offendersi; non è quindi sorprendente che, nonostante i riconosciuti meriti, faccia fatica ad affermarsi. È anche difficile da utilizzare in piccole organizzazioni, o dove il management non comprenda che il tempo speso per eliminare gli errori immediatamente verrà poi recuperato in fase di testing e debugging. Cionondimeno, se operate in una organizzaziona abbastanza matura da non vedere l’ispezione del codice come un affronto di un programmatore verso un altro, si tratta di una delle tecniche più potenti per la rimozione degli errori; un buon riferimento per chi desideri applicarlo, ricco di conoscenza acquisita sul campo, può essere trovato in [5].
Asserzioni
Durante lo sviluppo, il programmatore esegue continuamente assunzioni sullo stato dell’esecuzione: parametri che "sicuramente" saranno validi, precondizioni che devono essere verificate prima di svolgere una azione, condizioni invarianti all’interno di un loop, post-condizioni che devono verificarsi dopo l’esecuzione di un processo di calcolo.
Purtroppo, queste assunzioni spesso non vengono documentate, neppure in un commento; quando lo sono, talvolta diventano false dopo una manutenzione del codice, che raramente si estende alla correzione dei commenti circostanti. L’ideale sarebbe che queste assunzioni fossero documentate come parte integrante del codice, e verificate a run-time durante la fase di testing del programma, ma che fosse anche possibile eliminarle dalla versione finale per non incorrere nel relativo overhead computazionale.
In alcuni linguaggi, ad esempio Eiffel, il concetto di precondizione, invariante, ecc., fa parte del linguaggio stesso ed è quindi possibile farne direttamente uso. In altri casi, come il C o il C++, non esiste un meccanismo interno ma è facilmente simulabile con l’uso del preprocessore, definendo una macro ASSERT che esegue il test della condizione solo se è definito un simbolo di debugging. Esiste anche una macro standard "assert", per quanto sia spesso necessario personalizzarla nei diversi ambienti.
L’uso delle asserzioni (sotto questo termine ricadono sia le pre/post-condizioni, le proprietà invarianti, eccetera) è uno dei cardini della programmazione professionale; consente infatti di scrivere codice che si auto-verifica e che verifica la correttezza delle chiamate di funzione. Possiamo vedere un semplice esempio, tratto da [6]: supponiamo di voler implementare una classe Stack, molto semplificata, e di scegliere l’approccio seguente:
class Stack
{
public :
Stack() ;
void Push( int x ) ;
void Pop() ;
int Top() ;
private :
int stack[ 100 ] ;
int top ;
} ;
Stack :: Stack()
{
top = 0 ;
}
void Stack :: Push( int x )
{
stack[ top++ ] = x ;
}
void Stack :: Pop()
{
top-- ;
}
int Stack :: Top()
{
return( stack[ top - 1 ] ) ;
}
Ogni metodo della classe opera correttamente, ma abbiamo implicitamente assunto che non verranno mai inseriti più di 100 elementi, e che Top() e Pop() non verranno mai richiamati sullo stack vuoto. Se questa assunzioni non sono verificate, il comportamento della classe è indefinito; una possibile variante, più sicura ma molto discutibile, è la seguente (riportando solo i metodi modificati):
void Stack :: Push( int x )
{
if( top < 100 )
stack[ top++ ] = x ;
}
void Stack :: Pop()
{
if( top > 0 )
top-- ;
}
int Stack :: Top()
{
if( top > 0 )
return( stack[ top - 1 ] ) ;
else
return( 0 ) ;
}
Questa tecnica viene spesso chiamata difensiva in quanto il programmatore si è cautelato da eventuali errori nella chiamata alle sue funzioni. In realtà, questo codice ha due problemi: un overhead inutile se le chiamate sono corrette, ed una "correzione" silenziosa e discutibile delle chiamate errate: sarebbe molto meglio se chi utilizza in modo errato la classe venisse opportunamente avvisato.
La soluzione migliore è quindi di introdurre all’interno del codice, ovunque sia necessaria la verifica di una assunzione, una apposita asserzione che generi un messaggio di errore se la condizione non è verificata; l’asserzione stessa deve essere poi rimovibile tramite compilazione condizionale: in tal modo, possiamo utilizzare la versione "con controlli" durante lo sviluppo, e la versione "senza controlli" e quindi senza overhead, per la release finale. Un esempio è dato nel listato seguente:
void Stack :: Push( int x )
{
ASSERT( top < 100 ) ;
stack[ top++ ] = x ;
}
void Stack :: Pop()
{
ASSERT( top > 0 ) ;
top-- ;
}
int Stack :: Top()
{
ASSERT( top > 0 ) ;
return( stack[ top - 1 ] ) ;
}
Altri esempi di uso delle asserzioni, nonché le diverse modalità per definire una macro di ASSERT, oltre che sul testo succitato sono anche discusse in [7], mentre una discussione più organica e formale è data in [8]; esiste anche un progetto, che purtroppo non sembra fare molti progressi, per aggiungere costrutti per le asserzioni accoppiati ad un theorem-prover al linguaggio C++ [9], ed analoghe esperienze esistono per il linguaggio Ada [10]. La tecnica è comunque totalmente indipendente dal linguaggio, in quanto è sufficiente che esista la possibilità di emettere un messaggio di errore ed eventualmente terminare l’esecuzione; naturalmente, il supporto per la compilazione condizionale, o la possibilità di emettere automaticamente il nome del file ed il numero di linea incriminata (entrambe esistenti ad esempio in C), sono di grande aiuto ma non indispensabili. Si tratta quindi di una questione di metodo e stile di programmazione, non di un supporto esterno per il programmatore; cionondimeno, può essere di estrema efficacia nella riduzione del numero di errori.
Tracing
Le asserzioni sono un caso particolare, che per la sua importanza ha comunque dignità a parte, di una tecnica di più ampio spettro, molto utilizzata prima dell’avvento dei debugger simbolici, ma ancora in uso e con interessanti evoluzioni in atto.
Si tratta, in effetti, della tecnica più elementare a disposizione del programmatore: aggiungere opportuni statement al codice che emettano messaggi, eseguano il dump di strutture dati, e così via, in modo da verificare in diversi punti lo stato del programma. La differenza rispetto alle asserzioni sta nell’impossibilità (o nell’eccessiva difficoltà) di racchiudere tutta la conoscenza a livello dichiarativo: attraverso i messaggi ed i dump, il programmatore verifica manualmente la correttezza o meno del codice sui singoli casi, anziché cercare condizioni generali ed inserirle come asserzioni. Le due tecniche possono ovviamente operare di concerto.
Osserviamo che queste tecniche sono spesso le uniche utilizzabili in ambienti poco forniti di strumenti di debugging (ad esempio, nel campo della programmazione embedded) o quando vi siano problemi di temporizzazioni o interferenze da parte di un debugger interattivo; in questi casi, è spesso utile avere a disposizione un monitor separato per il debugging, che ci consenta di accedere direttamente alla memoria video per avere la massima velocità e la minima interferenza con il programma sotto analisi. In ambiente PC, è spesso possibile far convivere una scheda monocromatica (magari recuperata da un vecchio computer) con schede grafiche più avanzate, ed utilizzare la prima per il tracing: tra l’altro, molti debugger simbolici sono in grado di usare tale monitor anche per il normale debugging interattivo.
Come accennato, pur se elementare questa tecnica ha ancora dei promettenti sviluppi, attraverso strumenti che consentono di avere una rappresentazione grafica e dinamica dei valori assunti dalle strutture dati; questi strumenti richiedono spesso l’aggiunta di statement di tracing (per questo sono considerati in questo paragrafo) ma forniscono invece una rappresentazione molto più versatile dei valori; un esempio piuttosto semplice (in quanto non consente la visualizzazione di strutture multidimensionali, come vettori e matrici) è TrackDeck, prodotto da DashBoard Software. Esiste una fervida attività di ricerca in questo settore, orientata specialmente alla visualizzazione della dinamica dei programmi paralleli o multithreaded, dove raggiungere il giusto grado di confidenza con il comportamento a run-time può essere obiettivamente più complesso; è pertanto auspicabile che vi sia una ricaduta a medio termine, sotto forma di strumenti disponibili per gli sviluppatori, anche se al momento si rimane a livello di prototipi. Interessanti riferimenti per chi fosse interessato a maggiori dettagli sono disponibili ad esempio in [11].
Librerie di debugging
Programmando in linguaggi ad alto livello si fa grande uso delle funzioni di libreria, o di librerie acquistate da terze parti; purtroppo, la maggior parte di esse non viene fornita nelle due versioni, con e senza verifica dei parametri, e ciò significa che in molti casi, un qualunque errore sul valore di uno dei parametri darà risultato indefinito.
Ciò vale anche per le operazioni primitive del linguaggio: ad esempio, sia in C che in Pascal o in C++, deallocare due volte consecutivamente lo stesso puntatore ha risultato indefinito; lo stesso dicasi del tentativo di dereferenziare un puntatore non più valido. In molti casi, "comportamento indefinito" significa blocco della macchina o, su sistemi protetti, la terminazione del programma; in alcuni casi, tuttavia, il comportamento sarà piuttosto casuale, ed in questo caso il bug può essere anche molto difficile da rintracciare.
Per prevenire simili problemi, esiste per molti linguaggi la possibilità di utilizzare una libreria di debugging, che non solo provvede funzionalità analoghe alle librerie di sistema (o ad una loro sottoparte, ad esempio la gestione della memoria dinamica) ma fornisce anche una serie di verifiche a run-time sulla validità dei parametri, o la possibilità di simulare eventi run-time come la ricompattazione della memoria, o il suo esaurimento, eccetera, in modo da poter testare l’applicazione in condizioni di stress ambientale.
Un esempio di libreria per la gestione della memoria dinamica, che oltre a diversi metodi di allocazione fornisce anche funzionalità di debugging, è SmartHeap prodotta da MicroQuill per diversi sistemi operativi, e che supporta il C ed il C++; chi fosse interessato ai dettagli implementativi di una analoga libreria, può consultare il già citato [7], che ne presenta anche i sorgenti, o [12] che illustra i meccanismi di verifica run-time utilizzati all’interno di Microsoft Foundation Classes.
Infine, in alcuni casi è possibile utilizzare una versione di debug del sistema operativo, in sostituzione o complemento di una libreria di debugging. In effetti, poiché il sistema operativo prevede una serie di entry points, sotto forma di una API o di chiamate di interrupt, dal punto di vista di un linguaggio ad alto livello le funzionalità di sistema operativo sono equiparabili a quelle fornite da altre funzioni di libreria. In questo caso, il sistema operativo in versione di debug può verificare che i file handle siano validi, che la memoria rilasciata (a basso livello) sia stata precedentemente allocata, che le risorse del sistema siano allocate e deallocate correttamente, e così via. Ovviamente, ciò comporta un overhead addizionale, per cui è consigliabile utilizzare la versione di debug solo per controllare l’eventuale presenza di errori; si tratta comunque di uno strumento molto utile, che dovrebbe sempre essere usato quando disponibile (ad esempio, esistono versioni di debug dell’ambiente Microsoft Windows).
Verifiche a run-time
Neppure una libreria è in grado di verificare alcuni tipi di errori a run-time: ad esempio, in C ed in C++ non esiste alcuna verifica sugli indici utilizzati nell’accesso agli array, e se non si utilizza una apposita classe "array" (che può al suo interno contenere codice di debugging) non vi è alcuna possibilità di intercettare eventuali errori tramite una libreria.
Ciò non significa che non sia possibile utilizzare altri tipi di strumento, come Bounds Checker in ambiente Windows o Purify in ambiente Unix; questi tool fanno uso delle informazioni di debugging (le stesse utilizzate dai debugger interattivi per associare linee di codice al codice macchina, o mostrare i valori delle variabili) per eseguire una serie di verifiche a run-time, alcune delle quali molto generali (es. accesso agli array, memoria dinamica, eccetera) ed alcune legate al sistema in uso (ad esempio, l’uso di un handle invalido per una finestra in ambiente Windows). Pur con alcune limitazioni, tra cui problemi di interoperabilità con altri strumenti come il citato SmartHeap, tool di questo tipo sono forse i più utili in assoluto per la verifica dinamica del codice (il che non esclude l’utilità ed anzi la necessità di tecniche preventive, come ispezioni ed asserzioni); gli unici problemi possono derivare dall’overhead computazionale conseguente al loro utilizzo, che può rendere problematica la verifica di applicazioni time-dependent. In tutti gli altri casi, chi sviluppa in modo professionale farebbe bene a dotarsi di uno di questi strumenti, che probabilmente si ripagherà da solo la prima volta che troverà uno dei bug insidiosi che richiederebbero ore per essere identificati con tecniche più tradizionali.
Sniffers
Il termine sniffer viene dal nome utilizzato per gli analizzatori di protocollo per le reti, ma in campo software indica un settore piuttosto ampio di strumenti che "osservano", possibilimente in modo non-intrusivo, il funzionamento di una applicazione, e compilano un report o emettono dei messaggi in tempo reale.
Esempi di sniffer sono i programmi che creano un log di tutti i messaggi ricevuti da una finestra, o che analizzano l’uso delle risorse fatto da una applicazione, o mostrano in tempo reale l’uso dello stack da parte dell’applicazione stessa. Altri tipi di sniffer possono creare un log delle comunicazioni tramite DDE (dynamic data exchange) o delle chiamate tra due server OLE2 in ambiente Windows.
Si tratta, molto spesso, di utility distribuite insieme con il compilatore o l’ambiente di sviluppo (ad esempio, Borland WinSight per i messaggi tra finestre, Microsoft OLE2 Debug Handler per server OLE 2, eccetera) oppure di tool shareware e public domain. In molti casi, sono anche semplici da creare nel caso non fossero disponibili: tempo fa, ho realizzato uno Stack Watcher dinamico per Windows in poche ore di tempo libero.
Uno sniffer è tanto più utile quanto meno è intrusivo, ovvero quanto meno modifica l’ambiente che sta osservando; da notare la differenza tra uno sniffer ed un programma di tracing, in quanto lo sniffer non richiede alcuna modifica al programma per essere utilizzato, ed in principio non richiede neppure i sorgenti del programma sotto esame, ed è pertanto totalmente indipendente dal linguaggio di programmazione usato. Ciò si rivela molto utile quando il linguaggio utilizzato sia poco diffuso, e quindi scarsamente dotato di utility specializzate. Per contro, gli sniffer non sono normalmente in grado di segnalare in quale riga di codice si annidi un potenziale bug: la tecnica di utilizzo è quindi profondamente diversa rispetto ai tool precedentemente visti: si tratta infatti di analizzare un responso black-box, una visione "esterna" del nostro programma, e da essa dedurre i malfunzionamenti interni. Spesso è utile poter inserire dei commenti in tempo reale all’interno del log, in modo da sapere esattamente quali azioni (e quindi ragionevolmente quali porzioni di codice) hanno portato ad una determinata successione di eventi.
Test Bed
Uno degli approcci moderni alla programmazione è quello cosiddetto "per parti"; in realtà, si tratta di un’idea molto vecchia, che solo recentemente ha trovato sufficiente supporto tecnologico per essere utilizzata in applicazioni reali, al di fuori dell’accademia.
Tuttavia, sviluppare un "componente" solleva una serie di problematiche non trascurabili dal punto di vista del testing e del debugging: un componente si impegna a rispettare un certo protocollo (interfaccia) con i potenziali clienti; talvolta, il protocollo può essere estremamente complesso, come nel caso di alcuni componenti OLE2.
Come possiamo trovare eventuali bug all’interno del componente? L’idea classica di creare dei "driver", ovvero dei mini-programmi che pilotano il componente, è difficilmente attuabile in questo caso, poiché un contenitore OLE2 ha complessità paragonabile a quella di un componente, e potenzialmente anche oltre se il nostro contenitore intende realmente sollecitare tutte le funzioni del server.
In casi simili, occorre un vero e proprio "tavolo di prova" (test bed) per il nostro componente, o meglio per la famiglia di componenti che implementa un determinato protocollo; il tavolo di prova deve essere strutturato in modo da essere estendibile e per sollecitare il componente attraverso chiamate valide ed invalide, e verificare l’aderenza della risposta con la specifica del protocollo (o fornire a chi testa il programma elementi sufficienti per valutare l’aderenza stessa). Un esempio di test bed interattivo per server OLE2 è stato presentato su questa rivista, purtroppo con alcuni errori di formattazione del testo, all’interno di [13].
In generale, i test bed sono spesso il risultato di uno sviluppo in-house piuttosto che tool commerciali; se sviluppate una applicazione complessa, basata su componenti interscambiabili, driver, ed altri moduli che devono rispettare protocolli ad alto livello, una delle scelte migliori dal punto di vista del testing e del debugging è di sviluppare un vostro test bed: è spesso l’unica scelta conveniente per poter testare i moduli "in isolamento" e non solo all’interno dell’applicazione destinata ad ospitarli.
Debugging interattivo
Questo è lo strumento di debugging oggi più diffuso: molto probabilmente, ogni lettore conosce ed utilizza strumenti per il debugging interattivo, modellati in gran parte intorno allo stesso schema.
È di norma possibile seguire il flusso del codice, visualizzato in formato sorgente o in assembler, osservare il valore assunto dalle variabili, porre breakpoint (talvolta anche condizionali) su certi statement, e così via.
Gli strumenti più sofisticati permettono anche di posizionare breakpoints sull’accesso a particolari locazioni, o l’uso di una porta di I/O, o la chiamata ad un interrupt: un esempio è il SoftICE, una cui recensione appare in questo stesso numero.
È interessante osservare che alcuni strumenti di debugging (ad esempio quello fornito con il compilatore C++ Symantec) permettono una "vista" di strutture dati complesse estremamente chiara ed immediata, in pratica analoga a quella che si avrebbe "disegnando" a mano una struttura: ad esempio i puntatori vengono correttamente inseguiti, ed una linked list apparirà in effetti come una sequenza di record concatenati. Per contro, strumenti di debugging che fanno un uso intenso della grafica rischiano di interferire maggiormente con i programmi in fase di debug (basti pensare a bug connessi con la gestione del repaint del video, o dipendenti dalle temporizzazioni); proprio per questo, in pratica ogni buon debugger interattivo consente anche di utilizzare un secondo monitor per il debugging (senza offrire quindi prestazioni grafiche) e/o un terminale connesso ad una porta seriale. In altri casi, è possibile lanciare il programma su un computer ed il debugger su un altro (debugging remoto), anche se è una possibilità che ho visto raramente sfruttata.
Uno dei problemi più grandi dei debugger interattivi è l’incapacità di operare adeguatamente in presenza di ottimizzazioni del codice da parte del compilatore. Anche semplici ottimizzazioni, come la rimozione del codice invariante dall’interno di un loop, o l’eliminazione di variabili ausiliarie, nonché ottimizzazioni più spinte come la strenght reduction, possono portare ad anomalie in fase di debugging: impossibilità di osservare i valori di una variabile (eliminata), variabili che apparentemente assumono valori "errati" rispetto al codice (code motion, strenght reduction), impossibilità di settare breakpoint alla locazione voluta (code motion), eccetera. Non a caso, molti produttori di compilatori suggeriscono di disabilitare totalmente le ottimizzazioni durante la fase di debug; si tratta in effetti di un buon consiglio, che può salvare parecchie ore di lavoro all’interno del debugger. Tuttavia, il codice ottimizzato non ha necessariamente lo stesso comportamento del codice non-ottimizzato, soprattutto in presenza di bug (proprio quando è più importante ricorrere al debugger!); inoltre, diventa in questo modo molto difficile rintracciare eventuali bug del compilatore, che spesso si annidano proprio nella fase di ottimizzazione.
In realtà, la limitazione dei debugger interattivi non è invalicabile: esistono diversi studi e proposte che permettono di superare in gran parte gli ostacoli al debugging di codice ottimizzato (vedere ad esempio [14], [15]); si tratta, come sempre, di attendere che alcuni risultati passino dal livello di ricerca a quello di produzione industriale, con la conseguente evoluzione degli strumenti di programmazione e debugging.
Il debugger interattivo, per la sua grande flessibilità, si presta anche ad un uso non strettamente legato all’eliminazione di bug trovati in fase di testing; ad esempio, uno dei metodi di sviluppo "imposti" ai programmatori Microsoft è proprio di seguire l’evoluzione del codice all’interno del debugger non per eliminare bug noti, ma per cercare eventuali bug. Si tratta di un approccio per certi versi piuttosto assolutista, tanto che in [7] l’autore (project manager per Microsoft) afferma che l’unico metodo per trovare i bug è tracciare il codice nel debugger, e che a poco o nulla serve "pensare" al funzionamento del codice. Pur non condividendo affatto questa posizione, va riconosciuto che alcuni tipi di bug possono essere scoperti immediatamente eseguendo passo passo il codice nel debugger (una sorta di testing white-box) ben prima delle normali fasi di testing; in molti casi, uno sviluppatore coscienzioso e competente è in grado di capire quando sia opportuno adottare questo tipo di metodologia, e quando invece sia più opportuno adottare una tecnica black-box.
Usa lo stack, Luke!
Vi sono situazioni, nell’uso di un debugger interattivo, in cui ci si ritrova in una determinata linea di un programma senza conoscere l’esatto percorso che ci ha portato ad eseguire quella linea.
Esempi di tale situazione sono:
- l’uso di un debugger che si auto-attiva in seguito ad errori di protezione; ad esempio, quando si tenti di scrivere in una zona di memoria non valida. In questo caso, un programma che generi uno di questi errori farà passare il controllo al debugger, che visualizzerà la linea "incriminata".
- l’uso di debugger con supporto "avanzato" per i breakpoint; in questo caso, si può ad esempio richiedere che, non appena una il contenuto di una locazione viene alterato, o si esegue I/O su una porta, il debugger si attivi e mostri la linea di codice responsabile.
In questi casi, sarebbe spesso utile conoscere il contesto di chiamata: una funzione in sé può sembrare perfettamente legale, e potrebbero essere i suoi parametri a creare problemi; conseguentemente, vi è spesso la necessità di conoscere la funzione chiamante.
Consideriamo ad esempio il seguente, semplice listato:
void f( int* p )
{
*p = 0 ; // errore in questa linea
}
void g()
{
int x[2] ;
f( x ) ;
int* y = NULL ;
// tramite lo stack,
// risaliamo alla vera causa
f( y ) ;
}
Vi sono due chiamate ad f(), e solo la seconda genera un’eccezione su sistemi protetti; l’eccezione attiverà il debugger, posizionandolo però su una linea apparentemente innocente. In un piccolo programma, risalire alla chiamata errata è questione di secondi, ma in un programma complesso, magari event-driven, di migliaia o decine di migliaia di righe, sarebbe estremamente più complesso identificare la chiamata che causa l’errore.
Fortunatamente, pressoché tutti i debugger interattivi consentono di osservare lo stack delle chiamate, ed anche di "navigarlo", posizionandosi nelle varie linee di codice corrispondenti alle attivazioni di funzione; in questo modo, localizzare le chiamate che hanno portato ad una situazione di errore è estremamente semplice.
Un buon debugger interattivo deve consentire, una volta posizionatisi in una diversa parte del codice tramite la navigazione dello stack, di osservare il valore delle variabili locali alla zona attualmente visualizzata: viceversa, si perderebbe molta dell’immediatezza nella ricerca degli errori.
Ricercare la chiamata errata navigando lo stack evita al programmatore di considerare tutte le possibili chiamate alla funzione che genera l’errore, o di cercare tutte le possibili righe in cui una variabile viene modificata, eccetera. Questo processo, molto complesso per gli esseri umani, è però più facilmente gestibile da uno strumento automatico; di fatto, esistono strumenti che possono compiere questa operazione, detta di "slicing", e che possono essere utili in molte occasioni. Si tratta di strumenti relativamente nuovi e poco diffusi, di cui parleremo più avanti in questo articolo.
Ripetibilità e regression testing
Molti bug sono ripetibili: ciò è estremamente utile, in quanto sappiamo che eseguendo una certa sequenza di operazioni otteniamo sicuramente un errore. Ciò non solo consente di cercare più facilmente la causa del problema, ma anche di verficare con facilità la presenza o l’assenza del bug; perché questa possibilità è così interessante? Poiché consente di automatizzare il cosiddetto regression testing. Quando si elimina un bug, vi è una probabilità non nulla di introdurne uno nuovo (questo punto verrà ripreso più avanti); analogamente, quando si introducono delle modifiche a fini migliorativi, è possibile introdurre dei bug, spesso a causa di una errata compresione del codice precedente. Per tale ragione, in progetti medio-grandi, o dovunque vi sia una forte volontà di produrre codice di qualità, è buona norma eseguire i vecchi test su ogni versione del programma, per verificare che le modifiche abbiano lasciato inalterate le feature non direttamente coinvolte (fenomeno chiamato regressione, da cui il termine usato per questo tipo di testing).
Naturalmente, eseguire manualmente decine, centinaia o migliaia di test è assolutamente improponibile, anche se il regression testing venisse eseguito solo in vicinanza di una release; in ogni caso, esistono degli ottimi strumenti per automatizzare un test, in gran parte simili ai registratori di macro presenti in molti ambienti (es. Windows), ma con costrutti specifici per definire delle procedure di test anche molto sofisticate. Un esempio di tali strumenti è Microsoft Test, che oltre ad un registratore dei movimenti del mouse e dei tasti premuti, consente di simulare loop, di fare riferimento al contenuto di finestre o ad entry dei menu, e così via. Strumenti simili sono assolutamente fondamentali nello sviluppo di applicazioni medio-grandi, e possono ripagare il proprio costo (di norma piuttosto contenuto) molto rapidamente, attraverso il risparmio di tempo dedicato al testing manuale.
Post-mortem debugging
Capita talvolta che un bug particolarmente insidioso non sia replicabile che su alcune macchine, o non si verifichi mai all’interno del debugger, o si presenti solo in configurazioni (memoria, schede grafiche, programmi funzionanti concorrentemente) che non permettono l’esecuzione del debugger. In questi, ed in altri casi analoghi, in determinati ambienti è possibile ricorrere al post-mortem debugging: si tratta di una tecnica molto comune sotto unix (i famosi "core dump" vengono usati a tal fine) ma disponibile anche in altri ambienti, ad esempio in Windows.
Il post-mortem debugging richiede che via sia un supporto, all’interno del sistema operativo o come programma separato, che permetta di ottenere un’immagine (dump) della memoria e dello stato del processore quando si verifica una eccezione. Il dump può essere poi esaminato, anche su altre macchine, dopo che l’applicazione è stata terminata (da cui il nome di post-mortem debugging).
Possiamo vedere un semplice esempio in ambiente Windows, dove esiste un tool piuttosto elementare fornito con il software di sistema, e presente quindi in ogni installazione completa, ovvero DrWatson (diversi compilatori forniscono comunque strumenti più completi, ad esempio il Borland WinSpector). Consideriamo il seguente programma C, che tenta di dereferenziare un puntatore NULL:
#include <windows.h>
int PASCAL WinMain(
HINSTANCE hInstance,
HINSTANCE hPrevInstance,
LPSTR lpszCmdLine ,
int nCmdShow )
{
char far* p = NULL ;
char ch = *p ;
return( 0 ) ;
}
L’esecuzione del programma genererà un’eccezione; se avete lanciato il programma DrWatson prima del programma in questione, questo genererà un file DRWATSON.LOG, di cui riporto una porzione in figura 1.
Dr. Watson 0.80 Failure Report - Tue Oct 24 18:22:05 1995 TEST had a 'Null Selector (Read)' fault at TEST 2:0018 [...] Stack Dump (stack) Stack Frame 0 is TEST 2:0018 ss:bp 4ea7:1d78 4ebf:0008 8e d8 mov ds, ax 4ebf:000a 83 ec 06 sub sp, 06 4ebf:000d 66 c7 46 fa 00000000 mov dword ptr [bp+fa], 0 4ebf:0015 c4 5e fa les bx, [bp+fa] [...]Per il nostro, semplice caso è sufficiente leggere l’indirizzo che ha generato l’eccezione e cercare, nel file .MAP generato al momento della compilazione, la riga che corrisponde a tale indirizzo (che può ovviamente iniziare diversi byte prima); in casi più complessi, è necessario fare riferimento ad altri indirizzi che potremo trovare sullo stack, ad esempio nel caso il nostro codice generi un’eccezione all’interno del kernel di Windows.
Line numbers for test.obj(TEST.CPP) segment TEST_TEXT
2 0002:0000
8 0002:000D
9 0002:0015
10 0002:001E
11 0002:0020
Vale la pena di rimarcare che il file di log può essere generato su una macchina e analizzato su un’altra, ad esempio su quella utilizzata per lo sviluppo; si rivela quindi un ausilio prezioso ogni volta che non sia possibile replicare un problema o intervenire direttamente sulla macchina che presenta i sintomi del bug.
Just-in-time debugging
Il just-in-time debugging è una caratteristica piuttosto recente, più che altro per raggiunta maturità degli strumenti di sviluppo, in quanto si tratta concettualmente di una operazione molto semplice.
Sostanzialmente, se viene abilitato il just-in-time debugging ogni errore run-time all’interno dell’applicazione invocherà automaticamente il debugger interattivo, posizionandosi nel punto in cui è avvenuto l’errore, anziché terminare semplicemente l’applicazione. In alcuni casi, ad esempio durante il testing di stress ambientale per una applicazione, può essere molto comodo; principalmente, è adatto agli ambienti in cui il testing ed il debugging sono eseguiti dalla stessa persona (quindi tipicamente lo sviluppatore stesso), mentre è meno adatto alle situazioni in cui il testing è eseguito da personale diverso. Nel secondo caso, anche se può essere comodo comunicare un numero di riga anziché fornire un dump da usare con il debugger post-mortem, è allora necessario fornire anche un dump dello stack, o avere la possibilità di chiamare immediatamente lo sviluppatore, viceversa si perdono gran parte dei vantaggi di questo strumento.
Il just-in-time debugging può essere molto utile nei casi in cui un problema sia difficile da replicare, in quanto consente di "sfruttare l’occasione" in cui il bug si presenta per investigare sulle sue cause, anche se non avevamo preventivamente lanciato il debugger.
Debugger hardware
Vi sono casi particolari in cui neppure un debugger a basso livello è sufficiente: ad esempio, quando si verificano problemi legati a temporizzazioni di eventi. In questi (ed in altri) casi, si desidera un ambiente totalmente non-invasivo, e che sia in grado di registrare e reagire ad ogni evento senza l’intervento del microprocessore stesso.
In tal caso, si ricorre spesso a debugger hardware, o agli ICE (In-Circuit-Emulator), in grado di emulare a livello hardware il microprocessore pur garantendo funzionalità aggiuntive a livello di debugging.
Si tratta normalmente di equipaggiamento piuttosto costoso, soprattutto per i microprossori più potenti, che deve essere realmente giustificato; in alcuni casi, è possibile ovviare alla mancanza di un simile strumento usando un pò di inventiva: in questo stesso numero, nella prova del debugger SoftICE, accenno all’uso di un oscilloscopio per verificare problemi di temporizzazione senza l’utilizzo di un debugger hardware.
Lo stesso SoftICE, il cui stesso nome spiega la volontà di creare un ICE software, può essere efficacemente utilizzato in moltissimi casi, sostituendo alle funzionalità di un ICE l’uso delle funzionalità di debugging proprie dei processori Intel; rimangono comunque al di fuori delle sue possibilità tutte le problematiche di temporizzazioni molto strette, dove anche il minimo overhead causato dal debugger possa falsare i risultati.
Due regole d’oro
Qualunque metodo o tool di debugging utilizziate, vi sono due regole che dovreste sempre rispettare:
1) trovate la causa del problema e ponetevi rimedio. NON accontentatevi di eliminare i sintomi del problema.
2) cercate un possibile metodo sistematico per proteggervi da errori analoghi nel futuro.
La prima regola, la cui applicazione è meno scontata di quanto non sembri, impone di capire la reale sorgente del problema, non di cominciare a modificare il codice a caso, o applicare soluzioni locali in modo da eliminare un malfunzionamento. Se una funzione vi restituisce valori doppi rispetto alla specifica, non divideteli per due prima di visualizzarli, ma eliminate il problema all’interno della funzione. Per quanto possa sembrare ovvio, il desiderio di avere "un programma che funziona" spinge spesso ad utilizzare scorciatoie di ogni tipo per eliminare un malfunzionamento: è evidente che queste modifiche avranno un impatto negativo sulla manutenzione e sul riuso del codice, in quanto un errore viene rimediato introducendo un altro errore che lo controbilancia.
La seconda regola è molto più difficile da applicare, ed in effetti solo gli sviluppatori e le organizzazioni più mature sono (di norma) in grado di farne uso continuo. Ciò non impedisce comunque di utilizzarla nei casi più immediati: se vi accorgete che un bug sarebbe stato segnalato dal compilatore abilitando i warning, rinunciate ad eventuali pretesti di "libertà" ed abilitate i warning. Se notate che un bug sarebbe emerso facilmente con un testing white-box, o tracciando passo passo il codice in un debugger prima di integrarlo nell’applicazione, prendete l’abitudine di farlo. Ricordate sempre che la differenza tra gli sviluppatori professionisti e gli hobbisti non è necessariamente nella conoscenza del linguaggio e delle tecniche di programmazione, ma anche e soprattutto nell’approccio allo sviluppo; una buona organizzazione, ed i singoli sviluppatori all’interno di essa, dovrebbero sempre cercare di trasformare gli eventi negativi (come i bug) in possibilità di miglioramento per l’intero processo di sviluppo.
In questo senso, anche norme di codifica come quelle riportate nel già citato [6] possono essere di grande aiuto; più in generale, però, è opportuno ricercare le cause anche in altre fasi dello sviluppo: ad esempio, una insufficiente attenzione all’analisi dei requisiti, o una pressione troppo forte per lo sviluppo "rapido", o l’uso errato della prototipazione. Per una visione più ampia su come rimuovere i bug dal processo di sviluppo del software (non dal software stesso), potete far riferimento a [16], con una nota di cautela: si tratta di una visione centrata sul programmatore, e quindi con pochissima enfasi su fasi molto importanti come la pianificazione, l’analisi dei requisiti, il design; può comunque essere interessante avere una visione dei processi utilizzati, nel bene e nel male, all’interno di Microsoft.
Modelli di evoluzione
Esistono molti studi sulla distribuzione dei bug all’interno dei programmi (es. [17]), attraverso i quali è possibile ottenere una notevole quantità di previsioni; una delle considerazioni più immediate è che i bug tendono di norma a concentrarsi in pochi moduli: non è raro che l’80% dei bug sia localizzato nel 20% dei moduli, quelli più complessi o semplicemente più "contorti". Questo suggerisce di verificare con attenzione ogni modulo che mostri di contenere troppi bug, poiché probabilmente ve ne sono altri: secondo diversi studi statistici, la probabilità che vi siano altri bug "latenti" cresce con il numero di bug già riscontrati, secondo una curva del tipo mostrato in figura 3.
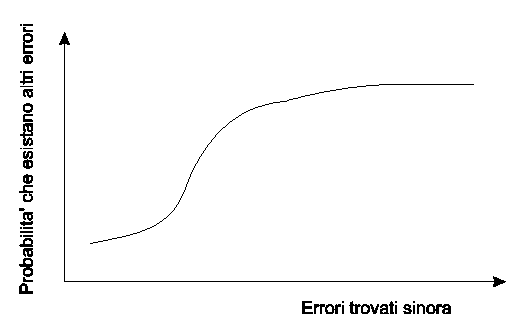
Un’altra proprietà molto interessante del software è l’evoluzione del numero di bug attraverso la manutenzione: anche in questo caso, esistono studi statistici che si dimostrano validi in moltissimi casi; la manutenzione, per quanto sia tesa ad eliminare dei bug (o ad introdurre nuove feature) ha comunque una probabilità non nulla di introdurre nuovi errori. Questo non deve sorprendere, in quanto moltissime delle assunzioni fatte inizialmente dal programmatore non vengono documentate, non sono evidenti dal codice, e tendono ad essere dimenticate da chi le ha fatte, oltre ad essere sconosciute agli altri; pertanto, modificare una parte di codice altrui (o semplicemente vecchio) al fine di eliminare un bug può facilmente introdurne dei nuovi.
La curva tipica dei bug in funzione del tempo ricalca spesso il modello dato in figura 4:
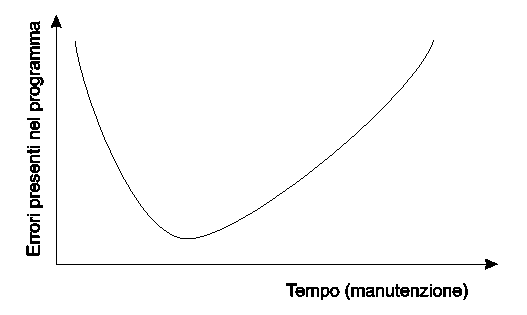
inizialmente si ha una riduzione del numero di bug, ma a lungo termine la continua manutenzione tende ad introdurne di nuovi, sino ad una situazione degenere; per questo, quando un modulo è troppo soggetto a manutenzione, sarebbe bene riconsiderarne il design, ed eventualmente ottimizzare il codice per manutenibilità ed estendibilità più che per velocità o compattezza, sempreché le prestazioni dell’intero sistema non ne abbiano a soffrire. Ottimizzare tutte le parti del codice solo per velocità è una pessima idea, spesso frutto di inesperienza nello sviluppo professionale.
Le frontiere del debugging: program slicers, debugging oracles
Ho ritenuto interessante completare questa panoramica sulle tecniche ed i tool di debugging con una breve descrizione di alcune attività di ricerca che promettono interessanti risultati nel campo del debugging.
Un primo settore è quello dei program slicers, in grado di presentare al programmatore solo delle "fette" di codice interessanti dal punto di vista del debug. Queste "fette" (slice) vengono ottenute attraverso una analisi data-flow, in modo da comprendere, ad esempio, tutti gli statement che possono influenzare il valore di una variabile ed escludere quelli che non possono in alcun modo influenzarlo.
In questo modo, all’interno del debugger avremo una quantità di codice molto minore da considerare; peraltro, come molti di voi potranno constatare (e come è stato anche osservato in molti studi, es [18]), questa operazione è spesso realizzata manualmente (o mentalmente) dai programmatori durante la ricerca delle cause di un bug.
Naturalmente, esistono casi in cui l’analisi data-flow è complessa (a causa ad esempio degli aliasing) o infruttuosa (a causa ad esempio di un cattivo stile di programmazione, con grande uso di variabili globali), ma in molti casi si può pervenire non solo ad uno slice piuttosto ridotto, ma anche ad una diagnosi semi-automatica della causa dell’errore [19].
Una naturale evoluzione di questa tecnica sono i cosiddetti oracoli (debugging oracles), in grado di fornire assistenza dipendente dal contesto durante la ricerca dei bug; per quanto la ricerca al momento verta più sull’analisi dell’efficacia degli oracoli stessi [20], [21] più che sulle tecniche per implementare in modo efficace l’oracolo, il settore costituisce un pò l’ombrello sotto il quale altre tecniche, come i program slicers, tenderanno in futuro a riunirsi. Non aspettatevi, comunque, di trovarli inclusi nella prossima release del vostro debugger: si tratta in gran parte di risultati piuttosto lontani dall’applicabilità in situazioni reali.
Conclusioni
Come abbiamo visto, esistono molti strumenti di debugging e molte tecniche per la ricerca e l’eliminazione dei bug; come in ogni altro settore, l’uso dello strumento adatto nelle diverse situazioni può far risparmiare tempo e portare ad un risultato migliore. Ha ben poco senso perdere ore nel debugger quando una libreria di debugger o un bounds-checker possono trovare l’errore in pochi secondi.
In ogni caso, la migliore tecnica per avere meno bug nei propri programmi resta la prevenzione, attraverso l’uso intensivo delle asserzioni e di una buona pratica di programmazione; nellla programmazione professionale la verificabilità del codice, ovvero la facilità con cui un bug può essere esposto [22], diverrà sempre più importante come criterio di discriminazione tra codice di bassa o alta qualità. Tutto sommato, nonostante i vari tool a disposizione, che devono comunque far parte del bagaglio di un professionista, nella programmazione come nella medicina prevenire è meglio che curare.
Bibliografia
[1] S. C. Johnson: "Lint: a C Program Checker", Technical Report N. 65, Bell Laboratories, 1978.
[2] Ian Darwin: "Checking C Programs With Lint", O’Reily & Associates, 1988.
[3] Spuler, Sajeev: "Static Detection of Preprocessors Macro Errors in C", Technical Report, James Cook University, Tonswille, Australia, 1992.
[4] Michael Fagan: "Design and Code Inspection to Reduce Errors in Program Development", IBM Systems Journal Vol. 15 No. 3, 1976.
[5] Grady, VanSlack: "Key Lessons in Achieving Widespread Inspection Use", IEEE Software, Vol. 11 No. 4, 1994.
[6] Carlo Pescio: "C++ Manuale di Stile", Edizioni Infomedia, 1995.
[7] Steve Maguire: "Writing Solid Code", Microsoft Press, 1993. Tradotto da Mondadori Informatica come "Tecniche e trucchi per programmare senza errori".
[8] D. S. Rosenblum: "A practical approach to programming with assertions", IEEE Transactions on Software Engineering, Vol. 21 No. 1, 1994.
[9] Marshall P. Cline, Doug Lea: "Using Annotated C++", Technical Report, Clarkson University, 1990.
[10] Sankar, Rosenblum, Neff: "An implementation of Anna", Proceedings Ada International Conference, 1985, Cambridge University Press.
[11] Kraemer, Stasko: "Issues in Visualization for the Comprehension of Parallel Programs", in Proceedings of the 3rd Workshop in Program Comprehension, IEEE Press, 1994.
[12] Brian Meyers: "Built-in Diagnostic Facilities in the Microsoft Foundation Classes Simplify Debugging", Microsoft System Journal, Febbraio 1993.
[13] Carlo Pescio: "Evoluzione della Programmazione in Ambiente Windows", Computer Programming No 33, Febbraio 1995.
[14] Zurawsky, Johnson: "Debugging Optimized Code With Expected Behavior", Technical Report, University of Illinois at Urbana-Champaign, 1991.
[15] Max Copperman: "Debugging Optimized Code Without Being Misled", Technical Report, University of California at Santa Cruz, 1992.
[16] Steve Maguire: "Debugging the Development Process", Microsoft Press, 1994.
[17] G. Myers: "The Art of Software Testing", John Wiley & Sons, 1979.
[18] R. A. Jeffries: "Comparison of Debugging Behaviour of Novice and Expert Programmers", Technical Report, Department of Psychology, Carnegie-Mellon University, 1982.
[19] Lyle, Weiser: "Automatic Program Bug Location by Program Slicing", 2nd International Conference on Computers and Applications, 1987.
[20] Spafford, Viravan: "Experimental Design: Testing a Debugging Oracle Assistant", Technical Report, Purdue University, 1992.
[21] Spafford, Viravan: "Pilot Studies on Debugging Oracle Assistants", Technical Report, Purdue University, 1993.
[22] Voas, Miller: "Software Testability: The New Verification", IEEE Software, Maggio 1995.
Biografia
Carlo Pescio svolge attivitŕ di consulenza e formazione in ambito internazionale nel
campo delle tecnologie Object Oriented. Ha svolto la funzione di Software Architect in
grandi progetti per importanti aziende europee e statunitensi. Č l'ideatore del metodo
di design ad oggetti SysOOD (Systematic Object Oriented Design), ed autore di numerosi
articoli su temi di ingegneria del software, programmazione C++ e tecnologia ad oggetti,
apparsi sui principali periodici statunitensi. Laureato in Scienze dell'Informazione,
č membro dell'ACM e dell'IEEE.