Ereditarietà nei progetti reali
|
|
Dr. Carlo Pescio Ereditarietà nei progetti reali |
Pubblicato su Computer Programming No. 71
Vi hanno mai spiegato l'ereditarietà usando Rettangoli e Quadrati? Oppure l'ereditarietà multipla usando lo Studente-Lavoratore? Ebbene, questi sono esempi classici che si comportano bene in teoria e molto, molto male in pratica. In questo articolo vedremo alcuni principi e tecniche per l'uso corretto dell'ereditarietà nei progetti reali.
Tempo fa ho notato su Usenet una firma molto carina, che tradotta suona più o meno così: "La differenza tra teoria e pratica è, in pratica, un po' più grande che in teoria". In informatica, potremmo applicare questo motto un po' ovunque: passare dal mondo accademico alla realtà del lavoro significa in molti casi fare una bella doccia fredda, dimenticare Dijkstra e le weakest preconditions e passare invece a lottare con i bug del sistema operativo.
Questo non significa che il "mondo reale" sia arretrato rispetto a quello accademico. La verità è che i due mondi hanno schemi di valori diversi e spesso incompatibili. Chi ha letto la mia intervista a Niklaus Wirth [Pes97a] ricorderà la sua disillusa opinione sulla separazione tra problemi accademicamente interessanti e problemi reali di "programming in the large".
Purtroppo il risultato di questa separazione è talvolta assolutamente deleterio: può succedere infatti che vengano utilizzati in modo diffuso e ripetuto degli esempi "giusti" secondo lo schema di valori accademico (eleganza, neutralità, minimalismo, capacità evocativa, immediatezza) e totalmente sbagliati secondo lo schema di valori professionale (realizzabilità, testabilità, manutenibilità, estendibilità, riusabilità, ecc). Con il risultato di instillare negli studenti il germe di soluzioni errate, che si manifestano al momento dell'applicazione nei progetti reali.
L'ereditarietà è forse uno dei casi più emblematici: vi è mai stato citato l'esempio dello studente-lavoratore come situazione tipica di utilizzo dell'ereditarietà multipla? Oppure il caso ancora più semplice di derivazione rettangolo-quadrato o ellisse-cerchio come classico utilizzo dell'ereditarietà singola? Molti di noi sono colpevoli di aver usato esempi simili per il loro minimalismo e potere evocativo, che li
rende ottimi candidati sotto il profilo accademico. Purtroppo, sono anche esempi irrimediabilmente sbagliati di utilizzo dell'ereditarietà, vista sotto il profilo professionale.
In questo articolo riprenderò alcuni degli esempi classici di ereditarietà, utilizzati fin troppo spesso per insegnare la programmazione ad oggetti, provando a valutarli dal punto di vista della progettazione professionale. Vedremo che in molti casi il risultato è alquanto scadente, e che per ottenere i famosi benefici degli oggetti occorre modificare il modello adottato. Nel fare questo, cercherò come sempre di evidenziare alcune linee guida nell'uso dell'ereditarietà nei progetti reali.
L'ereditarietà è per sempre
Iniziamo proprio con l'esempio più classico e onnipresente di ereditarietà: uno Studente è-una Persona; un Lavoratore è-una Persona; uno Studente-Lavoratore è-uno Studente ed è-un Lavoratore, da cui si evince il semplice schemino di figura 1, destinato ad apparire su tutti i libri di testo come giustificazione dell'ereditarietà multipla.
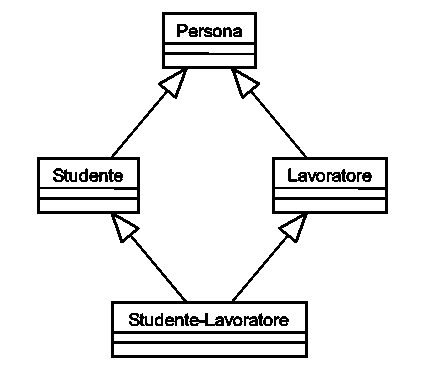
Raramente ci si ferma a pensare a cosa potrebbe servire un modello simile, ovvero in quale programma reale si debbano conoscere i dettagli degli studenti, dei lavoratori, e degli studenti-lavoratori. La risposta ovvia è (guarda caso) "nel database degli studenti universitari". La risposta è ovvia ma è altrettanto ovviamente sbagliata, perché al limite in un simile database avremo la classe Studente e la sottoclasse Studente-Lavoratore, ma non certo la classe Lavoratore: chi lavora e non studia non finisce sicuramente nel database degli studenti universitari.
Con un po' di fatica possiamo identificare un problema reale che coinvolga sia gli studenti che i lavoratori: ad esempio, il database del servizio sanitario nazionale o il database del ministero della difesa, ufficio leva militare. Pensiamo ad esempio a quest'ultimo: come in molti casi reali, per svolgere correttamente i propri compiti il sistema avrà bisogno non solo dello stato corrente/istantaneo di ogni Persona, ma anche della sua storia. Lo stesso avviene per i database adatti al campo medico, dove è necessario tenere traccia della storia del paziente, ma anche per i database che mantengono la storia contributiva o penale delle persone, eccetera.
In generale, anche se questo esula dal semplice schemino di figura 1, nel mondo reale quando si parla di Persone si tende a parlare dell'intera storia della persona, ovviamente entro i limiti di interesse del sistema. Questo dettaglio, apparentemente secondario, rende il diagramma di figura 1 completamente inadatto all'utilizzo nel mondo reale.
Ricordiamo infatti che nella maggior parte dei linguaggi ad oggetti, ad ogni oggetto viene assegnata una classe al momento della creazione, e l'oggetto rimane di tale classe per la sua intera esistenza. In C++, o in Java, o in Delphi, o in Ada95, eccetera, noi scriveremo qualcosa del genere:
Studente* nick = new Studente( ... ) ;
e l'oggetto puntato da nick rimarrà uno Studente sino a che non verrà distrutto. Altri linguaggi (tipicamente quelli senza type-checking statico) sono più liberali e permettono agli oggetti di cambiare classe in modo più o meno complicato. Ma nel mondo reale, è più probabile che si utilizzi un linguaggio con type-checking statico, per tante buone ragioni che non starò a ripetere.
Torniamo al nostro oggetto nick: possiamo pensare che sia un oggetto persistente, mantenuto su un database che tiene traccia del suo stato e della sua storia. L'oggetto nick è di classe Studente, quindi conterrà i dati di ogni Persona (ad esempio la data di nascita) più i dati di ogni Studente: ad esempio il numero di esami superati, unico baluardo contro la chiamata alle armi.
Un giorno, però, il nostro nick terminerà gli studi e con un po' di fortuna diventerà un Lavoratore. Boom. Nick non può diventare un Lavoratore, perché è uno Studente e tale deve rimanere per la sua intera esistenza di oggetto: l'ereditarietà è per sempre, non possiamo cambiare classe a nick dinamicamente. Possiamo sempre tentare qualche escamotage (l'informatica è la terra dei trucchi): ad esempio, distruggere Nick e ricrearlo come Lavoratore, conservando il suo sotto-oggetto Persona e perdendo la sua storia di Studente.
Anche questo può essere più semplice a dirsi che a farsi: se usiamo un database ad oggetti, ogni oggetto ha un proprio identificatore, e quando ricreiamo il nick-Lavoratore, il suo sotto-oggetto Persona avrà gli stessi dati ma identificatore diverso. Ogni relazione tra altri oggetti e nick-Studente (o il "vecchio" nick-Persona) si sarà persa nel nulla, a meno che non ci si preoccupi di ricostruirle manualmente. In un sistema che non può permettersi di "dimenticare" i dati, il modello di figura 1 porta ad un numero di complicazioni tali
da sconsigliarne decisamente l'utilizzo nel mondo reale.
Una nota importante: siccome sento già gli adepti di Stepanov sogghignare in coro "te l'avevo detto che l'OOP non funziona", è importante sottolineare che non si tratta di un problema della programmazione ad oggetti. Si tratti di un problema legato all'uso errato dell'ereditarietà: di fatto, il modello "corretto" (nel senso di "utilizzabile nel mondo reale") continua a fare uso dell'ereditarietà, ma con qualche importante modifica al diagramma.
Prima di vedere una soluzione alternativa, tuttavia, vorrei fermarmi un momento a riflettere sulla causa dell'errore, e possibilmente su come evitare trappole analoghe durante lo sviluppo. La lezione di fondo è la seguente: non utilizzare l'ereditarietà per modellare un ruolo temporaneo di un oggetto. L'ereditarietà è per sempre, almeno in molti linguaggi. Usarla per modellare una situazione in evoluzione significa cercare guai.
In realtà, la lezione ci suggerisce anche una soluzione alternativa. Una Persona, durante la sua vita, svolge un certo numero di Attività. Ovviamente può svolgere più Attività contemporaneamente, ad esempio lo Studio ed il Lavoro. Ogni Attività ha una data di inizio ed una data di fine: quest'ultima è opzionale, poiché le Attività in corso non avranno una data di fine specificata. Questo ci porta in modo naturale al modello di figura 2: la Persona svolge (o ha svolto) un certo numero di Attività, strutturate in una gerarchia di ereditarietà.
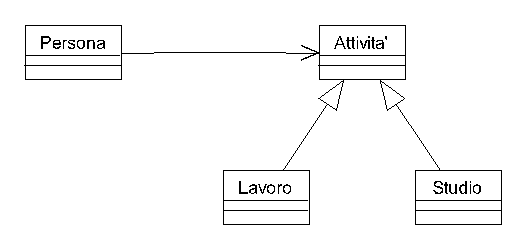
Il nuovo modello ha un numero sorprendentemente alto di buone proprietà. Innanzitutto iniziare e terminare una Attività è banale, perché non abbiamo problemi di "cambio di classe". Diventa facile risalire alla storia di una Persona e diventa altresì facile tenere traccia solo gli ultimi "n" anni di attività di una persona. Diventa anche relativamente facile fondere due database diversi basati sullo stesso modello, un argomento interessante che merita qualche parola in più.
Da anni si sente parlare dei grandi benefici ottenibili dalla fusione dei vari database appartenenti ai diversi settori delle organizzazioni, siano esse pubbliche o private. Spesso, una difficoltà non trascurabile sta proprio nella rigidità dei modelli utilizzati per i database. Pensiamo ad una ipotetica fusione di un database dell'ufficio leva con il database del servizio sanitario nazionale. Se abbiamo utilizzato il primo modello, nel database dell'ufficio leva esisteranno altre sottoclassi di Persona, che modellano la gerarchia militare.
In ognuno dei due database, esisteranno anche dei meccanismi più o meno complicati per permettere ad ogni oggetto di "cambiare classe", conservando quanti più dati e relazioni sia possibile. La fusione dei due database non richiede soltanto la creazione di una classe Persona che contenga l'unione dei dati (e così via per altre eventuali classi in comune), ma anche una pesante e potenzialmente complicata revisione di tutto il codice di "cambio classe".
D'altra parte, nel secondo modello si tratterebbe di modificare come prima la struttura di Persona, eventualmente rivedere alcune Attività in comune, e probabilmente di rivedere l'interfaccia della classe Attività. Non dimentichiamo infatti che il nostro scopo è di usare Attività in modo polimorfo quando possibile, e la fusione di due gerarchie richiede spesso una revisione delle interfacce comuni. Un
lavoro comunque più maneggevole della fusione dei database basati sul primo schema, anche perché spostiamo l'attenzione dal livello procedurale a quello strutturale.
Nonostante tutte queste interessanti proprietà, la soluzione di figura 2 è poco frequentata dal mondo accademico. In effetti non è minimale, nel senso che usa sia aggregazione che ereditarietà. Non è neanche evocativa, e non possiamo usarla per spiegare l'ereditarietà multipla. Non è neppure immediata, perché le ragioni di fondo che la supportano richiedono una conoscenza più approfondita delle problematiche reali.
In compenso funziona, e si basa su un uso corretto dell'ereditarietà, che in figura 2 è utilizzata per modellare relazioni immutabili: lo Studio sarà sempre una Attività, il Lavoro Autonomo sarà sempre un Lavoro. Viceversa, utilizziamo l'aggregazione ed il polimorfismo per modellare relazioni mutevoli, come le attività correnti di ogni Persona. Tenetelo sempre presente nei vostri progetti reali.
I rettangoli non sono oggetti?
Poco fa ho citato scherzosamente Stepanov e la sua avversione per l'OOP. Ebbene, almeno una delle affermazioni di Stepanov [Lor97] è sacrosanta, e dovrebbe essere incorniciata: "dire che tutto è un oggetto è come non dire niente". Questo non significa, a mio avviso, che l'OOP sia "filosoficamente scorretta" (per usare sempre le parole di Stepanov). Significa soltanto che all'interno di ogni disciplina ci sarà sempre qualcuno che fa un passo un po' troppo lungo e si trova a camminare sull'aria, senza il sostegno di fondamenta solide su cui poggiarsi.
Fortunatamente, la frase "tutto è un oggetto" è ormai passata di moda come i pantaloni a zampa d'elefante, anche perché è decisamente falsa. Gli "oggetti" dell'OOP non sono gli oggetti del mondo reale e non sono neanche gli oggetti astratti di altre discipline: ad esempio, non sono gli oggetti astratti della matematica e della geometria. Questa affermazione può causare un'extrasistole a qualcuno già scosso dalla triste fine dello Studente-Lavoratore, quindi cercheremo di avvicinarci alla dura realtà per gradi.
Da un punto di vista geometrico, ogni Quadrato è-un Rettangolo. In effetti, ogni quadrato è un rettangolo, ovvero un poligono con quattro lati e quattro angoli retti; il quadrato ha una proprietà addizionale, quella di avere tutti i lati di uguale lunghezza (nota per il futuro: dire "proprietà addizionale" significa dire che Quadrato è una restrizione di Rettangolo). Possiamo quindi ipotizzare una relazione di ereditarietà tra Quadrato e Rettangolo, ed usarla per spiegare concetti anche interessanti come la ridefinizione di un metodo (es. Diagonale) per fornire un algoritmo alternativo più efficiente nelle classi derivate.
In effetti, la gerarchia Rettangolo-Quadrato, o la sua alternativa Ellisse-Cerchio, si ritrova con una certa frequenza nei testi e nei
corsi di introduzione alla programmazione ad oggetti. Nel mondo reale, però, si comporta decisamente male. Prendiamo l'esempio di figura 3: una finestra ha una sua area, modellata come Rettangolo.
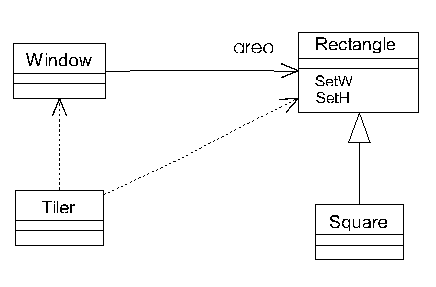
Siccome un Quadrato è-un Rettangolo, possiamo pensare di ottenere delle finestre quadrate semplicemente derivando la classe Quadrato, e ridefinendo i metodi SetW e SetH di Rettangolo, in modo tale da mantenere i quadrati consistenti: entrambe modificheranno sia l'altezza che la larghezza nel caso di un Quadrato.
C'é solo un piccolo particolare: quando aggiungiamo la classe Quadrato (e quindi le finestre quadrate), probabilmente il nostro algoritmo pre-esistente per il tiling delle finestre smetterà di funzionare correttamente. Gli algoritmi di tiling ("disponi tutto" per chi usa Windows in versione italiana), nella loro implementazione più semplice, assumono innocentemente che cambiando l'altezza di una finestra la larghezza risulti inalterata, e viceversa. La nostra classe Quadrato, introdotta successivamente, rompe questo contratto.
Rivediamo meglio il problema (che è più complicato di quanto sembri, ed al quale dedicherò anche il prossimo paragrafo): la classe Rettangolo mette a disposizione due metodi SetW e SetH. Quando (e se) deriviamo la classe Quadrato, abbiamo tre scelte a disposizione per SetW e SetH.
La prima è gestire SetW/SetH cambiando classe: in fondo, "stiracchiando" un quadrato otteniamo un rettangolo. Questo non è facilmente ottenibile in un linguaggio di programmazione con type checking statico.
La seconda è gestire SetW/SetH generando un'eccezione: un Quadrato si modifica solo con l'apposita funzione SetSide. Questo non risolve il nostro problema, nel senso che il Tiler è scritto usando l'interfaccia di Rettangolo, e quindi anziché un malfunzionamento otterremo un'eccezione (non un grande miglioramento!).
La terza è gestire SetW/SetH come accennato sopra, ovvero adattando anche l'altro lato per mantenere il quadrato un Quadrato. Questo può andare bene o meno: dipende cosa ha promesso la classe Rettangolo ai suoi utilizzatori.
Le prime due soluzi
oni non sono praticabili in un programma reale. In realtà, esse vanno contro un corollario della regola vista prima, che possiamo enunciare come segue: ogni classe deve essere chiusa rispetto alle operazioni della classe stessa e delle sue classi base. Ovvero, nessuna delle operazioni definite su una classe C o su una delle sue classi base B deve causare un "cambio di classe" per gli oggetti di classe C. Questo va sempre ricordato quando si progetta l'interfaccia di una classe base e quando si deriva una nuova classe. In particolare, se vogliamo che la nostra classe base sia realmente riusabile per derivazione, dobbiamo prestare grande attenzione ai metodi che definiamo, pensando a quanto essi siano realmente sensati per ipotetiche classi derivate. Introdurre SetW e SetH nell'interfaccia di Rettangolo potrebbe impedirci di derivare Quadrato da Rettangolo.
La terza soluzione è comunque insoddisfacente, perché può o meno violare il "contratto" tra Rettangolo ed i suoi utilizzatori (sicuramente lo fai nei confronti di Tiler). Se avete letto il mio articolo "Oggetti ed Interfacce" [Pes97b], ricorderete come molti linguaggi non consentano di specificare chiaramente il contratto di ogni classe. Questo è un esempio lampante di quanto ciò sia grave: chi deriva Quadrato non ha idea di cosa gli sia consentito cambiare nel comportamento della classe, perché nessuno ha specificato chiaramente cosa ogni metodo deve garantire. La modifica può andare a buon fine o meno, dipende da come Rettangolo è stato utilizzato.
In mancanza di una specifica, dobbiamo essere noi ad immaginare cosa richiede e cosa garantisce la classe base ai propri clienti. In questi casi la soluzione più sicura è seguire la regola forte dell'ereditarietà, ovvero: usare l'ereditarietà pubblica solo per estendere gli attributi e le funzionalità e mai per restringere. In molti casi, la regola invita ad essere prude
nti e ad adottare un riuso di implementazione ma non di interfaccia, usando ad esempio l'ereditarietà privata (largamente ignorata dai programmatori). Sicuramente, essendo il Quadrato una restrizione del Rettangolo, ci impedisce di derivare Quadrato da Rettangolo.
Cosa succede invece in presenza di una specifica, anche informale, del comportamento di una classe? In questo caso possiamo essere più precisi e dare una regola più fine riguardo l'uso dell'ereditarietà. Mi occuperò di questo nel paragrafo che segue; prima, tuttavia, vorrei risolvere l'apparente contraddizione tra la matematica (dove un Quadrato è-un Rettangolo) e l'OOP, dove la relazione (apparentemente) non vale più.
In realtà la questione è più sottile: in matematica, gli "oggetti" non cambiano. In matematica non si può prendere un quadrato e "trasformarlo" in un rettangolo. Il quadrato della matematica è un insieme di punti, il rettangolo anche, e gli insiemi non hanno identità: sono definiti solo dagli elementi che contengono. Se "modifico" un quadrato in senso matematico ottengo un altro insieme, ovvero un altro oggetto: di fatto, non ho modificato alcunché, ho solo preso in considerazione un altro insieme di punti. Il quadrato da cui ero partito resta com'era, sono io come osservatore a prendere in considerazione un altro insieme.
Ma nell'OOP, gli oggetti hanno un'identità, e noi vogliamo che applicando i vari metodi l'identità resti inalterata. In questo senso, gli "oggetti" dell'OOP e della matematica sono profondamente diversi. Più semplicemente, potremmo pensare ai rettangoli "della matematica" come ad oggetti con il solo costruttore, nessuna funzione di modifica, ed un operatore di confronto che non sia basato sull'identità degli oggetti ma sul contenuto. In effetti, se togliamo SetW/SetH dall'interfaccia di Rettangolo possiamo riconciliare l
e due visioni del mondo, anche se il risultato non è molto utile per affrontare i problemi reali, dove gli oggetti cambiano pur rimanendo se stessi.
Il principio di sostituibilità
Già in passato ho accennato al cosiddetto Principio di Sostituibilità di Liskov. Si tratta di una regola semplice, che richiede tuttavia un approccio allo sviluppo un po' più rigoroso di quanto si tenda a fare in pratica. Il Principio in questione [Lis88], [LW94] si può esprimere come segue: Sia P(x) una proprietà dimostrabile per ogni oggetto x di tipo T. Allora, affinché S sia un sotto-tipo di T, P(y) deve essere vera per ogni oggetto y di tipo S. Notate la differenza terminologica: Liskov usa il termine tipo/sotto-tipo, non classe/sotto-classe. Possiamo ragionevolmente assumere (anche se formalmente è una questione più spinosa) che i termini siano equivalenti quando parliamo di ereditarietà pubblica, ovvero ereditarietà di interfaccia e non di sola implementazione.
Bertrand Meyer ha dato una formulazione sostanzialmente equivalente in termini di Design by Contract: data una classe T, ogni classe derivata S deve garantire che le pre-condizioni di ogni metodo siano uguali o più deboli, e le post-condizioni siano uguali o più forti. Ovvero, ogni classe derivata può solo "chiedere meno e garantire di più" ai clienti della classe base. Non può chiedere di più o garantire di meno.
Torniamo al nostro Rettangolo. Se avessimo dato una specifica anche informale, del tipo "SetW modifica la larghezza del rettangolo, lasciandone gli altri attributi invariati", allora la terza soluzione (ridefinire SetW in modo che anche l'altezza venga aggiornata) andrebbe contro il principio di sostituibilità, il nostro codice sarebbe errato e il codice della classe Tiler corretto. Viceversa, se la nostra specifica fosse stata "SetW modifica la larghezza del rettangolo, ed ha effetti non precisati sugli altri attributi", la sottoclasse Quadrato sarebbe stata assolutamente lecita, ed il Tiler avrebbe avuto torto, assumendo qualcosa che non faceva parte del contratto.
Il pri
ncipio di sostituibilità permette di raffinare i risultati ottenibili con la regola forte data in precedenza: in effetti, potremmo pensare di lasciare SetW e SetH nell'interfaccia di Rettangolo e continuare a derivare Quadrato da Rettangolo, ma solo se possiamo dare una specifica molto blanda di tali metodi (quella con "effetti imprecisati"). In un progetto reale, per quanto riguarda Quadrato e Rettangolo, questa strada è difficilmente percorribile, il che ci porta a concludere che è meglio evitare del tutto la derivazione in simili occasioni.
In generale, ogni volta che deriviamo una classe pubblicamente, dobbiamo chiederci se stiamo violando il contratto garantito dalla classe base: nei progetti reali, non dobbiamo mai concentrarci sulla classe come elemento in sé, ma vederla sempre all'interno di uno scenario che include i suoi clienti.
Un'ultima riflessione: chi vuole, non faticherà a scorgere dietro questo semplice esempio un'ottima giustificazione della mancanza di apprezzamento del Design by Contract, o di altri sistemi più o meno formali di specifica. Molti di noi sarebbero ben felici di poter dire "la chiamata API tal dei tali non rispetta il suo contratto, questo mi impedisce di sviluppare un programma corretto, quindi come fornitore dovrai metterla a posto o pagare una penale". Qualcuno non sarebbe così contento, ad esempio alcune case produttrici il cui nome comincia per M e finisce per T. Magari non saremmo contenti neppure noi, se il nostro ruolo fosse (anche solo occasionalmente) di fornire elementi riusabili, framework applicativi o programmi estendibili via plug-in di terze parti. Sicuramente il mercato del software sarebbe molto, molto diverso da quello attuale: forse meno dinamico, ma anche meno confuso, instabile e ciarlatanesco.
La mia personale opinione è che la soluzione ai problemi del software non stia nell'imitare i circuiti integrati con i componenti software, ma nel perseguire la
stessa professionalità degli altri settori tecnologici, anziché rifugiarsi nella faciloneria dei wizard, nella comoda ambiguità del linguaggio, e nel continuo cambio di strumenti e paradigmi per nascondere la fragilità dei sistemi sottostanti.
Follie di Sostituibilità
Una delle raccomandazioni viste al paragrafo precedente è particolarmente pericolosa se usata senza riflettere: "Una classe derivata dovrebbe estendere, non restringere, la classe base". In effetti manca un pezzo alla raccomandazione, che tendiamo a dare per scontato: "A meno che questo non vada contro il buon senso", nel qual caso forse è meglio usare l'ereditarietà privata e restringere nella sottoclasse.
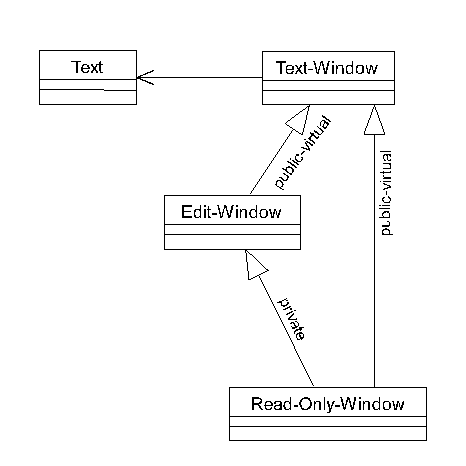
Tanto per non restare nel vago, vorrei proporvi un esempio preso dal pur ottimo JOOP [Ruc96]. L'autore dell'articolo in questione utilizza come esempio una finestra di testo, disponibile in due versioni, read-only ed editabile: il diagramma, convertito in UML, è quello della figura 4.
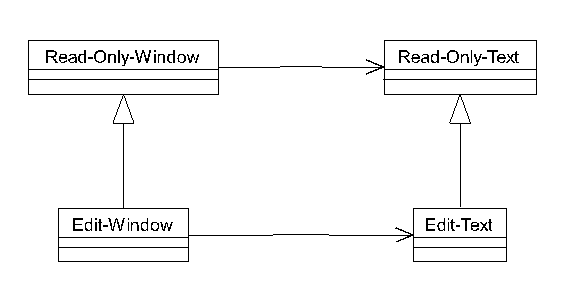
Contrariamente a quanto avrebbero fatto molti lettori, l'autore deriva la classe Edit-Window da Read-Only-Window. Questo sembra un controsenso: se proviamo a leggere il diagramma, viene fuori "una finestra editabile è-una finestra a sola lettura", che suona decisamente male, mentre con il diagramma rovesciato otterremmo un "una finestra a sola lettura è-una finestra editabile" che suona forse un pochino meglio, ma sempre male.
D'altro canto, è innegabile che la soluzione di figura 4 rispetta la raccomandazione di cui sopra: una finestra editabile è una ragionevole "estensione" di una finestra read-only, mentre la soluzione opposta (e forse più naturale) porta al tentativo di restringere la classe base (editabile) in una derivata (read-only), andando quindi contro la stessa raccomandazione.
La verità è che entrambe le soluzioni sono sbagliate. Derivare Edit-Window da Read-Only-Window potrebbe facilmente portare ad una violazione di contratto: un client della classe base che mantenga una cache interna del testo (che è read-only) si troverebbe in difficoltà a lavorare con oggetti di classe derivata (che non garantisce più tale proprietà).
D'altra parte, la soluzione anti-intuitiva proposta dall'autore ha tutte le buone ragioni per esserlo: una finestra Read-Only avrà una buona parte della sua implementazione pensata per problematiche Read-Only. Quando deriviamo la nostra classe editabile, tutte le assunzioni nascoste in tale implementazione torneranno indietro a tormentarci per l'intero sviluppo. Viceversa, dal punto di vista implementativo derivare una finestra Read-Only da una editabile porterà forse a qualche spreco di risorse, ma difficilmente ci creerà problemi realizzativi (per questo ci sembra "migliore", l'istinto del programmatore non mente).
Una soluzione migliore è in buona parte presente nelle frasi precedenti: possiamo facilmente ricic
lare l'implementazione di Edit-Window in Read-Only-Window, ma in modo privato e non pubblico: in questo modo non dobbiamo preoccuparci di possibili violazioni contrattuali. Personalmente, avrei probabilmente adottato una soluzione come quella di figura 5, dove esiste un'interfaccia base (Text-Window) per le funzioni realmente comuni, e due classi separate, una delle quali deriva in modo privato anche dall'altra per riusarne in parte l'implementazione.
Per concludere il festival della citazione, casi come quello di figura 4 mi ricordano una frase di Voltaire, ripresa proprio da Wirth nel suo "Algoritmi + Strutture Dati = Programmi": "Egli chiede perdono in ginocchio per aver un tempo postulato, in vista di un risultato paradossale: Anche se pare contraddire la realtà, dobbiamo credere ai nostri calcoli più che alle nostre percezioni". La migliore delle raccomandazioni è sempre: usate il buon senso. Se la teoria contraddice il buon senso, è possibile che la teoria sia sbagliata, o sia stata capita male, o sia stata applicata nel modo sbagliato (si veda la frase di apertura). Questo è ancora più vero in informatica, dove le teorie vengono raramente sottoposte a verifiche sperimentali degne di questo nome.
Compiti per le vacanze
Come sempre, vi sarebbe ancora molto da dire sull'ereditarietà. Vista la stagione, anziché dilungarmi ulteriormente ne approfitto per lasciare qualche riflessione per le vacanze estive.
La prima riguarda la distinzione tra sottoclasse ed attributi. Perché sembra naturale avere una classe base Shape con sottoclassi Circle e Rectangle, ma non sembra naturale avere una classe base Color con sottoclassi Red, Blue, ecc (che tenderemmo invece a modellare come attributi?).
La seconda è più che altro un invito agli approfondimenti: un argomento del quale non vi ho parlato, sia per limiti di spazio che per evitare troppe divagazioni filosofiche, è la possibilità di vedere una classe definita in modo intensionale o estensionale, e le implicazioni che queste visioni hanno sull'ereditarietà, l'estensione e la restrizione. Chi vuole approfondire il tema, e trovare degli ottimi spunti su cui riflettere, può fare riferimento ad un ottimo testo di James Rumbaugh [Rum96].
Conclusioni
L'ereditarietà, come tutte le tecniche molto potenti, non è facile da usare bene. Occorre quindi stare attenti nel proporre e nel seguire esempi che si comportano molto bene in teoria e molto male in pratica.
La mia personale opinione, sia come ex-studente (che ancora "studia" molto) sia come formatore, è che gli insegnanti dovrebbero fare uno sforzo per avvicinarsi allo schema di valori del mondo reale, anche se questo significa rompere una lunga tradizione nella scelta degli esempi da utilizzare. Le mie prime esperienze di insegnamento erano fondamentalmente basate sullo stile "appreso" per osmosi dai miei insegnanti. Nel tempo, ho cercato sempre più di abbandonare gli esempi accademici a favore di quelli reali, anche se l'esempio reale è più complesso da spiegare e da inquadrare nel giusto contesto. A mio parere (ed in larga misura anche di chi partecipa ai miei corsi) questo porta non solo ad una migliore comprensione della reale utilità degli argomenti trattati, ma anche ad una più diretta applicabilità delle tecniche presentate e dei principi esposti.
Biografia
Carlo Pescio svolge attivitŕ di consulenza e formazione in ambito internazionale nel
campo delle tecnologie Object Oriented. Ha svolto la funzione di Software Architect in
grandi progetti per importanti aziende europee e statunitensi. Č l'ideatore del metodo
di design ad oggetti SysOOD (Systematic Object Oriented Design), ed autore di numerosi
articoli su temi di ingegneria del software, programmazione C++ e tecnologia ad oggetti,
apparsi sui principali periodici statunitensi. Laureato in Scienze dell'Informazione,
č membro dell'ACM e dell'IEEE.
Bibliografia
[Lis88] Barbara Liskov, "Data Abstraction and Hierarchy", ACM SIGPLAN Notices, May 1988.
[LW94] Liskov, Wing, "A Behavioral Notion of Subtyping", ACM TOPLAS, November 1994.
[Lor97] Graziano Lo Russo, "Intervista a Alexander Stepanov", Computer Programming No. 60, Luglio/Agosto 1997.
[Pes97a] Carlo Pescio, "Intervista a Niklaus Wirth", Computer Programming No. 58, Maggio 1997.
[Pes97b] Carlo Pescio, "Oggetti ed Interfacce", Computer Programming No. 63, Novembre 1997.
[Ruc96] Martin Ruckert, "Extensible subobjects in C++", JOOP, July-August 1996.
[Rum96] James Rumbaugh, "A matter of intent: How to define subclasses", JOOP, September 1996.