Object Oriented Technology - Introduzione
|
|
Dr. Carlo Pescio Object Oriented Technology - Introduzione |
Pubblicato su Computer Programming No. 34
Il ciclo di vita del software
Il software nasce normalmente da un'idea informale di una o piu'
funzionalita', ed evolve sino alla creazione di un prodotto finito
che realizza tali funzionalita'; il ciclo di vita del software
comprende quindi tutte le fasi dalla concezione iniziale dell'idea
alla realizzazione del prodotto ed alle successive modifiche,
cui ogni sistema realmente utilizzato e' naturalmente sottoposto.
Per piccoli progetti, spesso l'intero ciclo di vita e' centrato
sulla codifica, ed in seguito sulla manutenzione, mentre il progetto
dell'architettura, o l'analisi dei requisiti del prodotto, passano
in secondo piano o vengono indissolubilmente legati al lavoro
di implementazione. Per progetti medio-grandi, tuttavia, un simile
approccio non e' in genere applicabile, in quanto in mancanza
di un modello del ciclo di vita stesso, all'interno del quale
vengano definite le diverse fasi dello sviluppo, la pianificazione
del processo risulta sostanzialmente impossibile, e non e' quindi
prevedibile il costo o una realistica data di consegna del prodotto.
Per tale ragione sono stati proposti diversi modelli dell'intero
ciclo di vita del software, utilizzabili sia come guide per la
pianificazione, attraverso modelli di previsione, sia come guide
per la gestione e la verifica dell'avanzamento del progetto.
Sistemi informatici
Chi sviluppa in ambiente personal e' normalmente portato a considerare
il software come un'entita' a se' stante, non inserita all'interno
di un sistema piu' grande: cio' e' vero ad esempio per prodotti
di produttivita' individuale o applicativi orizzontali. Tuttavia,
gran parte del software esistente non implementa funzionalita'
generali, ma risolve problemi particolari, dalla gestione del
distributore di bevande alla prenotazione dei posti sugli aerei,
dalla gestione del magazzino al controllo dei parametri fisiologici
in sale di terapia intensiva.
E' quindi in genere necessario considerare il software come componente
di un sistema piu' grande, comprendente oltre ad esso anche hardware,
periferiche di vario tipo, nonche' le procedure di utilizzo del
sistema stesso. La suddivisione puo' essere operata a molti livelli,
in quanto un componente, specificato come hardware in una vista
ad alto livello del sistema, puo' a sua volta contenere, se analizzato
nel dettaglio, una parte software memorizzata su ROM o come microcodice.
Un modello per lo sviluppo del software dovrebbe quindi considerare
anche le fasi preliminari di suddivisione dei compiti dell'intero
sistema informatico tra hardware, software, procedure umane, operando
la distinzione ai diversi livelli di astrazione possibili.
Il modello a cascata
In figura 1 e' rappresentato schematicamente il primo e piu' diffuso
modello dell'attivita' di sviluppo del software, intesa come attivita'
ingegneristica anziche' come attivita' artigianale. Ogni box individua
una fase ben distinta, caratterizzata da un insieme di elementi
di ingresso e da un prodotto che rappresenta il risultato della
singola fase.
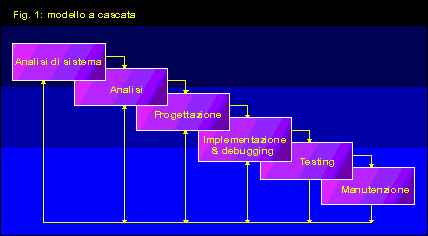
Il primo passo (analisi di sistema) individua i componenti software
del sistema; in funzione del sistema stesso, tale suddivisione
puo' essere banale o molto complessa: un sistema di videoscrittura
e' facilmente suddiviso nelle sue componenti hardware e software,
mentre nel caso di un sistema di controllo l'allocazione dei compiti
all'hardware o al software e' in genere complessa e non puo' prescindere
da una analisi accurata del sistema stesso nella sua completezza.
In questa serie di articoli, non considereremo questo pur importante
passo: chi fosse interessato ad un approfondimento delle tecniche
di co-design di hardware e software, puo' trovare un buon punto
di partenza in [4]. Dal secondo passo in avanti, vengono presi
in considerazione solo i componenti software.
Il secondo passo (analisi) definisce gli obiettivi da raggiungere,
descrivendo il dominio del problema, le funzionalita' richieste,
le prestazioni, ed ogni altro eventuale vincolo. In funzione del
sistema, anche l'interazione con l'utente rientra nelle funzionalita'
o nei vincoli. L'analisi si concentra su cosa deve essere
realizzato, non su come esso debba essere realizzato; durante
questa fase, l'analista deve raggiungere una sufficiente comprensione
del dominio del problema, in modo da semplificare le eventali
discussioni con gli esperti del campo ed evitare grossolani errori
nella descrizione del problema stesso. Cio' non significa che
l'analista debba necessariamente diventare un esperto del campo:
cosi' come un ingegnere che progetti sistemi di condizionamento
dell'aria non deve essere un architetto, ma deve avere familiarita'
con le condizioni ambientali, le conseguenze della posizione di
porte e finestre e dell'esposizione, e cosi' via, un analista
software che si occupi di sistemi biomedicali dovra' avere alcune
conoscenze di base di fisiologia, delle problematiche ambulatoriali,
eccetera. Il risultato dell'analisi e' spesso totalmente informale
o al piu' semi-formale, ovvero espresso in linguaggio naturale,
talvolta con l'ausilio di formalismi grafici standard; l'informalita'
dell'analisi e' ovvia conseguenza del fatto che i requisiti stessi
sono normalmente noti o comunque espressi solo in modo vago, impreciso,
approssimato, e che spesso il committente non sarebbe in grado
di valutare la corrispondenza di una specifica formale ai propri
desideri.
Il terzo passo (progettazione) e' stato volutamente semplificato
nel diagramma, tuttavia puo' essere distinto in due fasi separate:
progettazione dell'archiettura software e progettazione dettagliata.
La prima individua soluzioni opportune a livello dell'intero sistema:
ad esempio, la scelta di una architettura client-server, l'allocazione
di alcuni compiti ai client ed alcuni altri ai server, o la scelta
di una soluzione distribuita per un database piuttosto che una
architettura basata su una base dati centralizzata. La progettazione
dettagliata definisce e raffina i diversi componenti individuati
dall'analisi, partiziona i compiti in procedure o oggetti, stabilisce
la rappresentazione dei dati, sempre senza entrare nel dettaglio
implementativo. Il risultato del design, essendo inteso per una
udienza tecnica, e' normalmente almeno semi-formale, ed utilizza
comunemente formalismi grafici e/o un linguaggio ad alto livello
per la definizione dei compiti, per quanto sia molto diffuso il
ricorso al linguaggio naturale anche a livello di design dettagliato.
Il quarto passo (implementazione e debugging) consiste ovviamente
nel tradurre la specifica data dai documenti di design in qualche
linguaggio di programmazione; da notare che nel diagramma non
e' riportata una fase importante nello sviluppo di grandi sistemi,
ovvero l'integrazione dei vari componenti in un unico sistema.
L'eliminazione dei difetti di codifica (attivita' ben distinta
dal testing, discusso sotto) e' in genere considerata come parte
dello stesso passo, in quanto entrambi operano allo stesso livello
di astrazione (manipolazione del codice).
Il quinto passo (testing) e' inteso a trovare difetti ed a valutare
l'aderenza del prodotto finale alle specifiche del cliente. Non
entreremo ora nel dettaglio delle tecniche di testing e dei metodi
utilizzati per garantire la qualita' del prodotto: osserviamo
tuttavia che nuovamente nel diagramma e' riportato solo il "testing"
generico, mentre normalmente vengono eseguiti alcuni test specifici
sui singoli componenti e poi un testing dell'intero sistema.
Il sesto passo (manutenzione) coinvolge tutte le fasi di rimozione
di bug, modifiche, e miglioramenti, che vengono eseguiti dopo
l'installazione del sistema.
Osserviamo che il modello a cascata mostra due direzioni di avanzamento:
una dall'alto verso il basso, e da sinistra a destra, ed una dal
basso verso l'alto, da destra a sinistra. La prima corrisponde
ad un reale progresso del progetto: dopo l'analisi, si completa
il design, poi l'implementazione, e cosi' via. In pratica, e'
abbastanza inverosimile che ogni passo sia sufficientemente completo
ed esente da errori, per cui non e' insolito che, arrivati all'implementazione,
si trovino problemi a livello di design o di analisi; cio' comporta
degli inevitabili cicli, ed e' facilmente comprensibile come un
errore compiuto in fase di analisi e scoperto in fase di codifica
o testing abbia un costo molto elevato, in quanto incidera' su
tutte le fasi successive. In tal senso, gli errori di codifica
sono considerati "a basso costo".
Pur essendo piuttosto datato, il modello a cascata ha alcuni evidenti
pregi: ogni passo e' ben definito, i progressi sono evidenti e
ben quantificabili, esistono milestones importanti come il rilascio
dei documenti di analisi, di design architetturale, di design
dettagliato, e sono stati definiti molti modelli di previsione
dei costi implicitamente basati sul modello a cascata. D'altra
parte, sono nel tempo emersi diversi difetti del modello a cascata:
in particolare, e' spesso arduo definire in modo preciso i requisiti
sin dalla fase di analisi iniziale, ed ogni modifica dovuta ad
inesattezze o incertezze nella fase di analisi si propaga sino
al livello di codifica. Inoltre, l'utente deve necessariamente
attendere fino al quarto, meglio ancora fino al quinto passo,
prima di avere un prodotto funzionante, magari per scoprire che
il risultato non e' soddisfacente. La conseguenza in entrambi
i casi e' un certo numero di cicli, ovvero di percorsi dal basso/destra
verso l'alto/sinistra, spesso imprevedibili a priori e quindi
con effetti negativi su budget di sviluppo e tempi di consegna.
In realta', una corretta gestione del progetto puo' evitare entrambi
i problemi: un buon design deve essere sufficientemente flessibile
da consentire modifiche anche non marginali dei documenti di analisi,
senza impatti eccessivi sul risultato del design stesso e sull'implementazione;
questo e' vero a maggior ragione per il design architetturale.
Inoltre, un buon design puo' permettere l'implementazione e la
valutazione di "semilavorati", prodotti ove solo funzionalita'
di alto livello sono accessibili, mentre le parti basse sono sostituite
da stubs non operativi. Cio' consente, entro certi limiti, di
presentare all'utente dei prodotti intermedi.
L'evoluzione di una simile metodologia "dei semilavorati"
ha portato ad un diverso paradigma, che pone l'accento nell'interazione
tra programma e utente anche durante la fase di sviluppo.
Il modello a prototipi
In alcuni progetti, i pregi del modello a cascata non compensano
i relativi difetti: quando l'utente non riesce a chiarire le funzionalita'
desiderate, o quando non ha la pazienza o la possibilita' di attendere
a lungo, valutando specifiche di analisi e di progetto, il modello
a cascata si rivela inadeguato.
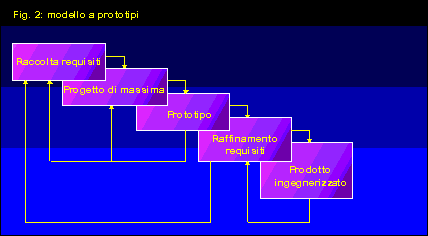
Il modello a prototipi, sintetizzato in figura 2, nasce proprio
pensando al ruolo centrale dell'utente nella definizione dell'applicazione.
Esaminiamo ora nel dettaglio le varie fasi:
Il primo passo (raccolta requisiti) e' analogo al passo di analisi
del modello a cascata; in genere, quando si utilizza il modello
a prototipi si raccolgono i requisiti in modo incrementale, in
quanto si assume normalmente che l'utente non sappia enucleare
i requisiti stessi in modo sufficientemente organico. Il risultato
e' abitualmente un documento informale, spesso centrato su un
prototipo cartaceo dell'interfaccia utente del prodotto.
Il secondo passo (progetto di massima) e' analogo al passo di
progetto del modello a cascata; in questo caso, tuttavia, per
la mancanza di precisione della fase precedente si puo' normalmente
completare in modo adeguato il solo progetto strutturale, ma non
il progetto dettagliato. La progettazione di dettaglio e' di norma
centrata sull'interfaccia utente, ovvero a partire dalle funzionalita'
dell'interfaccia si scende sino a completare i dettagli di base.
Il risultato e' solitamente un documento informale.
Il terzo passo (realizzazione di un prototipo) e' analogo al passo
di implementazione del modello a cascata. Nel modello a prototipi,
tuttavia, alcune caratteristiche fondamentali della fase di implementazione
non vengono rispettate. In particolare, le prestazioni, la qualita'
del codice, l'attenzione alla riusabilita' o alla mantenibilita'
del codice stesso, non vengono tenute in considerazione; e' altresi'
possibile utilizzare per la prototipazione una macchina diversa
dalla macchina target del progetto ingegnerizzato. Lo scopo del
prototipo e' esclusivamente quello di permettere all'utente di
valutare l'aderenza del prodotto alle proprie necessita' (mentre
nel modello a cascata il prodotto veniva confrontato con le specifiche
del sistema). Il feedback dell'utente genera uno o piu' cicli
all'interno dei primi tre passi, terminati i quali (ovvero quando
l'utente si dichiara soddisfatto), si puo' proseguire verso un
prodotto di qualita'.
Il quarto passo (raffinamento dei requisiti) e' in genere indispensabile
in quanto i passi precedenti tendono a generare un prodotto non
molto consistente ed organico. Funzionalita' spurie vanno rimosse
o ricondotte ad operazioni piu' generali, l'interfaccia utente
deve essere "ripulita", dettagli lasciati incompleti
vanno specificati. Sarebbe buona norma anche rivedere il design
architetturale alla luce del risultato finale.
Il quinto passo (ingegnerizzazione del prodotto) consiste innanzitutto
nel buttare via il prototipo. Questo e' uno dei grandi
scogli del modello a prototipi: spesso si tende a considerare
il prototipo come un prodotto (sia l'utente che lo sviluppatore
o il project manager sono particolarmente inclini a far cio'),
quando dovrebbe essere evidente, dalla definizione di prototipo
data sopra, che non e' assolutamente possibile usare il prototipo
come base di sviluppo. Talvolta e' possibile recuperare alcune
parti di codice, ma in genere una percentuale elevata del design
e del codice del prototipo va semplicemente eliminata.
Possiamo dire che le prime quattro fasi del modello a prototipi
generano un risultato equivalente alle prime due fasi del modello
a cascata (sino all'analisi), e spesso buona parte del risultato
della terza fase (progetto). Tuttavia, per giungere ad un buon
prodotto, e' ora indispensabile rivedere il progetto di dettaglio
e iniziare le fasi di sviluppo, integrazione, testing e manutenzione.
I pregi del modello a prototipi dovrebbero essere evidenti: e'
raro arrivare ad un prodotto finale che non soddisfa l'utente,
proprio perche' e' possibile, per il committente e lo sviluppatore,
seguire l'evoluzione su un prodotto piu' o meno operativo durante
l'intero ciclo di vita del progetto. Come abbiamo visto vi sono
tuttavia alcuni rischi nascosti che sono frequentemente causa
di problemi: arrivati ad un prototipo funzionante, spesso il cliente
pensa che sia possibile renderlo operativo con una semplice rifinitura;
per evitare (ingiustificati) imbarazzi, lo sviluppatore o il project
manager tende naturalmente ad acconsentire. Spesso accade inoltre
che alcune scelte, come algoritmi inefficienti o linguaggi semplici
ma limitativi, vengano poi involontariamente propagate nel prodotto
ingegnerizzato. Inoltre il design di un sistema complesso sviluppato
interamente con il paradigma dei prototipi tende ad essere meno
generale, mancando la necessaria astrazione dalle esigenze del
singolo. Nuovamente, una buona gestione del progetto puo' superare
entrambe le difficolta', che riguardano piu' il lato umano dello
sviluppo che il lato tecnologico.
Il modello a spirale
Per molti sviluppatori e project manager, nonche' per molti committenti,
l'idea di buttare via il prototipo, che su progetti non banali
puo' corrispondere a moltissime ore di lavoro, e' troppo radicale
e pertanto inaccettabile. Purtroppo cio' porta spesso a riutilizzare
il prototipo cercando di ripulirne il codice a posteriori, senza
rendersi conto delle fragili basi, sia a livello di progetto che
di implementazione, sulle quali si sta costruendo l'applicazione.
Da un punto di vista psicologico, e' piu' rassicurante l'idea
di sostituire i vari componenti del prototipo con componenti ingegnerizzati
durante l'evoluzione del prototipo stesso. Inoltre, in teoria
un simile modello di sviluppo permette un maggiore parallelismo
e quindi tempi di consegna piu' brevi.
Il modello a spirale nasce dall'idea, di per se' molto semplice,
di avere un continuum di analisi / progetto / implementazione,
raffinando sempre di piu' il modello ma conservando una qualita'
elevata, e mantenendo un prototipo funzionante ad ogni stadio.
In realta' l'applicazione reale di un simile modello non puo'
prescindere da linguaggi ed ambienti di sviluppo mirati.
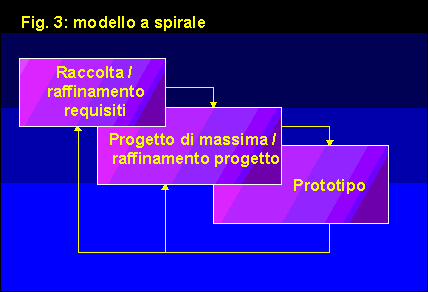
Come e' possibile vedere in figura 3, il modello a spirale e'
sostanzialmente identico alle prime tre fasi del modello a prototipi;
quello che cambia, tuttavia, e' la natura stessa del prototipo,
che in questo caso dovra' soddisfare ogni requisito di prestazioni,
di qualita', di mantenibilita' del prodotto finale.
Veniamo nuovamente ai pregi e difetti del modello. Per avere un
risultato soddisfacente, e' necessario un ambiente di sviluppo
adeguato, che consenta modifiche e verifiche rapide. Molto spesso
il modello a spirale e' usato congiuntamente a linguaggi di quarta
generazione, generatori di applicazioni, o applicativi programmabili.
I problemi del modello sono in parte condivisi con il modello
a prototipi: in particolare, il design tende ad essere un po'
troppo custom, troppo ritagliato sulle esigenze dell'utente. Vi
e' poi il notevole rischio di lasciare troppo codice del
prototipo nel prodotto finale. Nuovamente, una buona gestione
del progetto puo' evitare le complicazioni: come sempre, la chiave
del successo nei progetti sono le persone, prima delle metodologie
e dei tools.
La scelta del modello
Esistono ovviamente altri paradigmi per il processo di sviluppo
del software, tuttavia quelli qui descritti sono indiscutibilmente
i piu' diffusi; in genere, e' possibile attuare anche strategie
miste, come la prototipazione per alcuni componenti del sistema
ed il modello a cascata o a spirale per altri componenti. E' quindi
evidente come si debba essere in grado di operare una selezione
del modello di sviluppo: osserviamo come la scelta della corretta
metodologia ad ogni livello dello sviluppo (del modello iniziale
al framework per l'analisi, fino al design ed al paradigma e linguaggio
di programmazione) siano fasi critiche ma fondamentali nello sviluppo
di un sistema. Chi e' in grado di prendere tali decisioni con
criterio, basandosi su dati oggettivi, esperienze analoghe, modelli
di stima, conducendo il progetto senza tentennamenti tecnici o
soluzioni improvvisate, ha raggiunto la maturita' sufficiente
a partecipare a progetti di grande dimensione; chi si muove a
caso, affidandosi alla fortuna e confidando che tutto andra' per
il meglio, di solito non cresce professionalmente oltre i piccoli
progetti o rimane confinato a ruoli minori di codifica.
Come scegliere, dunque, il modello di sviluppo per i diversi progetti?
Occorre inizialmente riconoscere come lo sviluppo del software
sia in gran parte un'attivita' umana, ovvero gestita da uomini
e portata avanti attraverso l'interazione fra uomini. Il rapporto
uomo-macchina si ha sostanzialmente solo nella fase di codifica,
che su grandi progetti e' di gran lunga inferiore a quanto l'esperienza
su piccoli progetti lasci presumere. Nella scelta del modello
dovremo quindi tenere conto non solo del lato tecnologico o scientifico
del progetto stesso, ma anche dell'organizzazione responsabile
dello sviluppo e della tipologia del committente.
Se l'organizzazione e' ben strutturata, con personale qualificato
in grado di prendere decisioni autonome ma anche di interagire
nelle diverse fasi, se il committente e' disposto a valutare un
prodotto funzionante solo verso la fine del progetto, esaminando
nel frattempo documenti cartacei piu' o meno formali, la scelta
del modello a cascata e' in genere vincente.
Se l'organizzazione e' troppo disorganizzata, con personale non
molto preparato o poco incline a rispettare regole e modelli,
paradossalmente il modello a cascata puo' risultare sempre vantaggioso
rispetto al modello a prototipi o a spirale. In un tale scenario,
infatti, il rischio di ottenere un prodotto di qualita' scarsa
e' elevatissimo, se non si riconducono i progettisti e gli sviluppatori
all'interno di metodologie ben definite.
Il modello a prototipi e' in genere applicabile quando vi sia
una grande maturita' nell'organizzazione di sviluppo (tale da
accettare, e da rendere ben visibile al cliente, la necessita'
di buttare il prototipo), e qualora le caratteristiche del sistema
o le aspettative del cliente siano tali da richiedere l'esistenza
di prodotti intermedi semifunzionanti. Quando il cliente non e'
in grado di specificare chiaramente il risultato atteso, ma richiede
tuttavia clausole contrattuali molto strette, ad esempio, il modello
a prototipi puo' essere molto vantaggioso.
Il modello a spirale e' forse quello piu' adatto ad organizzazioni
miste, con alcuni elementi piu' preparati, che dovranno curare
il progetto dell'architettura e verificare e garantire la qualita'
all'interno dei vari cicli di raffinamento, ed alcuni elementi
meno preparati o autonomi, ai quali verra' demandata la fase di
codifica delle parti che verranno poi ingegnerizzate in un successivo
"ciclo" della spirale. Normalmente i progettisti devono
comunque avere la necessaria competenza ed esperienza.
Il modello a spirale e' piu' che adeguato nel caso di progetti
di piccole dimensioni, nell'ordine di qualche decina di migliaia
di righe, ove spesso il singolo sviluppatore ricopre le funzioni
di analista, progettista e programmatore.
Pianificazione e distribuzione degli sforzi
Associati ad ogni paradigma di sviluppo esistono criteri, tecniche
e modelli per la previsione dei tempi richiesti da ogni fase,
la valutazione del grado di parallelismo nello sviluppo, e cosi'
via. L'approfondimento di tale argomento, che e' rilevante soprattutto
per i progetti medio-grandi, esula tuttavia dagli scopi di questa
serie di articoli; chi fosse interessato, puo' trovare in [5]
e [6] una trattazione approfondita delle diverse tecniche. E'
comunque importante sottolineare che a tuttoggi non esiste nessun
modello affidabile di previsione che sia stato studiato, applicato
e verificato in progetti interamente sviluppati secondo i criteri
dell'analisi, design e implementazione object oriented. I modelli
esistenti assumono normalmente l'impiego delle tecniche di analisi,
design e programmazione strutturata; in effetti, da un punto di
vista ingegneristico le metodologie object-oriented sono relativamente
nuove, e non esistono sufficienti dati di tipo statistico per
la costruzione di un buon modello di previsione.
In ogni caso, mentre nei progetti di piccole dimensioni lo sforzo
di codifica e testing risulta dominante, nei progetti medio-grandi
si ha un pattern ricorrente, detto anche regola del 40-20-40:
analisi e design richiedono circa il 40% dello sforzo complessivo,
l'implementazione il 20%, il testing il 40%. E' interessante
osservare come la codifica richieda lo sforzo minore, a fronte
di un impegno maggiore nell'analisi e nel design; tuttavia, tali
dati assumono l'impiego di figure professionali qualificate, in
grado di risolvere effettivamente una gran parte dei problemi
dello sviluppo gia' a livello di analisi e design. Un design errato
o superficiale, che lasci alla fase di codifica uno spazio di
decisione troppo ampio, non potra' che alterare la distribuzione
dello sforzo.
Osserviamo che il testing richiede una notevole percentuale dell'impegno
complessivo; ovviamente, in queste cifre si presume una metodologia
di testing corretta, con un piano di test steso durante le fasi
di design ed implementazione, l'uso di tools appropriati (ad esempio
per i test di regressione), e non la banale verifica "sul
campo" dell'operativita' del prodotto. In tal senso, il tempo
destinato alla pianificazione del testing rientra nella percentuale
su considerata.
Continua...
Dopo questa breve ma doverosa introduzione, dal prossimo articolo
inizieremo a concentrare la nostra attenzione sulla fase di analisi,
dapprima evidenziando i criteri generali per modellare i problemi,
per passare in seguito all'impiego delle metodologie object oriented;
vedremo come le tecniche object oriented presentino una grande
coerenza tra le fasi di analisi, design e programmazione, sempre
riferite ad uno stesso paradigma e facenti uso degli stessi metodi
di astrazione. In seguito passeremo al design, ai criteri per
una buona progettazione architetturale e di dettaglio, e analizzeremo
i metodi per fornire, attraverso il design, le necessarie informazioni
alla fase di codifica.
Bibliografia:
[1] P. DeGrace, L, Stahl, "Wicked Problems, Righteous Solutions",
Yourdon Press, 1990.
[2] W. Humphrey, "Managing the Software Process", Addison-Wesley,
1989.
[3] F. Brooks, "No Silver Bullets: Essence and Accidents
of Software Engineering", IEEE Computer, Aprile 1987.
[4] R.K. Gupta, G. de Micheli, "Hardware-Software Cosynthesis
for Digital Systems", IEEE Design & Test of Computers,
Settembre 1993.
[5] B. Boehm, "Software Engineering Economics", Prentice
Hall, 1981.
[6] C. Jones, "Applied Software Measurements", McGraw
Hill, 1991.
Biografia
Carlo Pescio (pescio@acm.org) svolge attivitŕ di consulenza in ambito internazionale nel campo
delle tecnologie Object Oriented. Ha svolto la funzione di Software Architect in grandi progetti per
importanti aziende europee e statunitensi. Č incaricato della valutazione dei progetti dal
Direttorato Generale della Comunitŕ Europea come Esperto nei settori di Telematica e Biomedicina.
Č laureato in Scienze dell'Informazione ed č membro dell'ACM, dell'IEEE e della New York Academy
of Sciences.