Oggetti e Componenti COM
|
|
Dr. Carlo Pescio Oggetti e Componenti COM |
Pubblicato su Computer Programming No. 67
Quali sono le differenze tra gli oggetti dell’OOP ed i componenti del COM? Quali le conseguenze per il riuso? Quale ruolo può avere il COM nell’infrastruttura delle applicazioni? Se vi siete mai posti una di queste domande, qui troverete la mia risposta.
Chi scrive molti articoli ha l’indubbio privilegio di ricevere un consistente feedback dai lettori, le cui lettere costituiscono un utile osservatorio su una realtà molto ampia. Negli ultimi due mesi, ad esempio, il numero di domande riguardo il COM (e più in generale riguardo i componenti) ha avuto un picco inaspettato. In teoria, questo potrebbe essere una conseguenza del crescente utilizzo del Visual Basic, e del suo supporto per gli "oggetti" COM. Stranamente, però, le domande provenivano in gran parte da programmatori che conoscevano l’OOP e si trovavano a disagio con i componenti COM. Segno che qualcosa sta cambiando, e che molti gruppi di lavoro stanno passando ad una infrastruttura component-based. A volte a ragione, a volte no; non di rado, la pressione esercitata dal marketing dei produttori porta a decisioni non molto corrette dal punto di vista tecnico.
In questo articolo vorrei mettere a confronto gli oggetti "tradizionali" dell’OOP ed i componenti COM. Inizierò riprendendo il modello dei componenti COM e la loro proposta per il riuso, l’aggregation. Passerò poi ad analizzare le differenze principali tra oggetti e componenti nell’ottica della progettazione. Vedremo anche come simulare, usando i componenti, alcune caratteristiche degli oggetti come l’ereditarietà di implementazione. E come sempre, nello spirito di questa rubrica, non mancherà qualche riflessione sul ruolo di oggetti e componenti nello sviluppo del software.
Il COM originale
Il COM, come spesso avviene nell’informatica applicata, nasce come soluzione ad un problema concreto e solo in un secondo momento diventa una tecnologia di impiego generale. In particolare, il COM è emerso dalle necessità del team di sviluppo di Office, che non era soddisfatto dal grado di interoperabilità permesso dal DDE e da OLE1. L’obiettivo iniziale del COM era di fornire uno standard di packaging, indipendente dal linguaggio usato per l’implementazione, che consentisse un riuso di macro-componenti senza necessità di accedere al codice sorgente. Per ottenere questi obiettivi, Microsoft ha puntato su una tecnologia object-based, non object-oriented, rinunciando in particolare all’ereditarietà di implementazione ed introducendo invece un nuovo concetto, chiamato (con una pessima scelta terminologica, fonte di non poche incomprensioni) aggregation.
Vediamo rapidamente cosa si intente per "componente" all’interno del COM. Un componente è un package binario (un EXE o una DLL) che espone una o più interfacce. Un’interfaccia è un insieme di funzioni, correlate logicamente: nulla di diverso da un’interfaccia di Java o da una classe astratta in C++. A differenza di Java o del C++, tuttavia, i componenti COM possono esporre solo interfacce; non possono esporre dati in modo diretto. Non esiste neppure una distinzione tra funzioni protette e pubbliche: tutte le funzioni esposte dalle interfacce sono pubbliche.
Quando istanziamo un componente COM, dobbiamo dire esplicitamente a quale interfaccia siamo inizialmente interessati. Come risultato della creazione, otteniamo un puntatore all’interfaccia richiesta, che possiamo utilizzare per chiamare tutte le funzioni che la compongono. Naturalmente, se un componente espone più interfacce, possiamo voler chiamare funzioni appartenenti ad interfacce diverse sullo stesso componente. Incontriamo qui la prima differenza significativa con gli oggetti dell’OOP: in Java ed in C++, ad esempio, possiamo vedere un oggetto come un insieme di interfacce, e passare da un’interfaccia ad un’altra tramite cast, oppure possiamo vedere l’oggetto "completo", ovvero come istanza della classe più derivata, sul quale possiamo chiamare direttamente tutte le funzioni. Nel COM i componenti possono essere visti solo attraverso le singole interfacce, e mai come elementi completi. Questo dettaglio apparentemente marginale gioca un ruolo importante in fase di riuso, come vedremo più avanti.
Torniamo per ora alla necessità di passare da un puntatore ad un’interfaccia ad un puntatore ad un’altra interfaccia. In Java o in C++ possiamo utilizzare un cast, e sarà il compilatore a gestire i dettagli del caso. Ma il COM è nato come standard language-independent, e di conseguenza la funzionalità di passaggio di interfaccia non può essere una responsabilità del linguaggio: deve essere una responsabilità del componente stesso. Di conseguenza, tutte le interfacce COM derivano dall’interfaccia standard IUnknown, il cui metodo fondamentale QueryInterface serve a passare da un’interfaccia ad un’altra. Ottenuto quindi un puntatore ad una interfaccia del componente (al momento della creazione), possiamo chiamare QueryInterface su di esso ed ottenere un puntatore ad un’altra interfaccia implementata dallo stesso componente (ammesso di conoscere l’identificatore di tale interfaccia). IUnknown definisce anche altri metodi, che servono a mantenere un reference count sul componente, ma al momento possiamo tranquillamente trascurarli. Il ciclo di vita di un componente COM è quindi il seguente: viene inizialmente creato, specificando in qualche modo il package che lo implementa e l’interfaccia iniziale che vogliamo ottenere. Vengono chiamati vari metodi tramite questo puntatore iniziale, eventualmente ottenendo puntatori ad altre interfacce dello stesso componente tramite QueryInterface. Infine viene distrutto, quando il suo reference count scende a zero.
Se il COM si esaurisse qui, non sarebbe poi molto diverso da una DLL (o da un vecchio VBX). Più insiemi di funzioni correlate, con la possibilità di passare da un insieme all’altro. Invece, il COM prevede anche un meccanismo di estendibilità per i componenti, almeno in teoria. Meccanismo che è stato deliberatamente creato ex-novo, evitando l’ereditarietà.
Ereditarietà Vs Aggregation
Una delle critiche più frequenti ai vecchi VBX era l’impossibilità di estenderli e/o di specializzarne il comportamento, come è invece possibile fare per gli oggetti dell’OOP. I componenti COM sono estendibili, nel senso che è possibile aggiungere con relativa facilità il supporto per nuove interfacce. Come vedremo, non sono invece specializzabili con facilità, come avviene invece in OOP, perché il meccanismo di estensione del COM (nonostante gli evangelisti Microsoft sostengano il contrario) è molto limitato rispetto all’ereditarietà dell’OOP, che comprende ereditarietà di interfaccia e di implementazione.
Vale la pena di fermarsi e di riflettere sul perché Microsoft abbia deciso di non adottare l’ereditarietà. I motivi sono diversi, e sono peraltro molto ragionevoli; il problema nasce quando si tenta di nascondere le ragionevoli limitazioni del COM, o di farle addirittura apparire come pregi. Questo può portare a decisioni tecnicamente errate, causate da una informazione "schierata".
Il primo motivo va ricercato nella natura language-independent del COM. Il meccanismo di riuso del COM non può quindi far parte del linguaggio, ma deve poter essere gestito anche dal programmatore. Ad esempio, i primi componenti COM sviluppati da Microsoft erano scritti in C. L’ereditarietà, anche se ristretta a "singola implementazione, molteplici interfacce" come in Java, non è facile da gestire manualmente. Un secondo motivo va ricercato nel problema della fragile base class (per maggiori dettagli potete consultare [Pes95], disponibile anche tramite la mia home page). In breve, usando l’ereditarietà di implementazione è spesso necessario consultare il sorgente della classe base, in modo da chiarire meglio le situazioni ed i contesti in cui i metodi che vogliamo ridefinire vengono chiamati. Non a caso, nel succitato articolo invitavo a documentare adeguatamente i contesti di chiamata, che sono parte integrante del contratto tra classe base e classi derivate, ed a riusare con le molle eventuali classi base che manchino di tale documentazione. L’ereditarietà di implementazione è molto potente ma potenzialmente fragile durante la manutenzione, e va utilizzata con la dovuta cautela, sia progettando classi base che estendendole. Microsoft ha preferito fare un passo un po’ più lungo, ed ha deciso di eliminare completamente l’ereditarietà di implementazione.
Come si estende, quindi, un componente COM? Una possibilità è usare il contenimento (fig 1): creare un nuovo oggetto che aggiunge ed implementa nuove interfacce, ed anche tutte le interfacce del componente originale, implementandole come semplici forward. Ovviamente questa tecnica è quanto meno pesante da implementare, ed anche problematica in manutenzione. Se aggiungiamo un’interfaccia al componente base, dobbiamo anche modificare il componente esteso, aggiungendo l’interfaccia ed implementando i relativi metodi di forward. L’idea di aggregation nasce proprio dal tentativo di mantenere la semplicità del contenimento, ed allo stesso tempo di eliminare i metodi di forward.
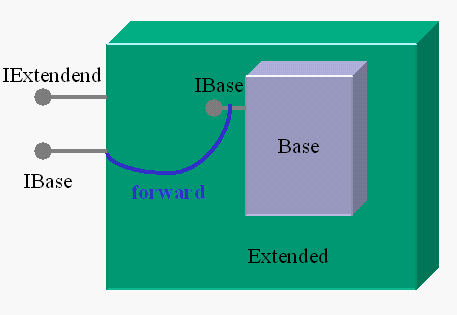
Meccanica dell’aggregation
Come abbiamo visto, nel COM possiamo passare da un’interfaccia ad un’altra tramite QueryInterface. Se il componente "esteso" aggiunge ad esempio l’interfaccia IExtended (che come tutte le interfacce COM è derivata da IUnknown), ed il componente "base" implementa l’interfaccia IBase, deve essere possibile chiedere ad IExtended di fornirci un puntatore ad IBase. Ma d’altra parte, questo è molto semplice: è sufficiente che il metodo QueryInterface implementato in IExtended deleghi le richieste che non è in grado di gestire al componente base. Se chiediamo al componente esteso (tramite la sua interfaccia IExtended) di fornirci l’interfaccia IBase, questo non farà altro che passare la richiesta al componente base che esso contiene. In questo modo non abbiamo problemi di manutenzione: possiamo aggiungere interfacce al componente base senza dover aggiornare quello esteso.
Ovviamente, non può essere tutto così semplice: cosa succede, infatti, se una volta ottenuto il puntatore ad IBase vogliamo tornare ad IExtended, o più in generale ad una delle interfacce implementate dal componente esteso? Siccome IBase è implementata dal componente base, una QueryInterface su di essa non potrà mai fornirci le interfacce del componente esteso. In effetti, per far funzionare correttamente l’aggregation occorre introdurre un ulteriore elemento, un "link all’indietro" tra il componente base ed il componente esteso. Nel COM, questo elemento è rappresentato dal cosiddetto "controlling unknown" (fig. 2), ovvero da una ulteriore implementazione di IUnknown ed in particolare del suo metodo QueryInterface.
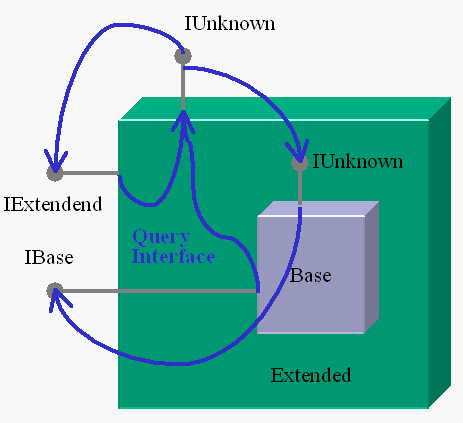
Vediamo quindi come funziona in generale un componente COM che supporta l’aggregation. Ogni interfaccia del componente deve implementare QueryInterface, ma come abbiamo visto non è generalmente in grado di farlo. Quello che fa è di delegare la richiesta "verso l’alto", ovvero al controlling unknown. Se il componente non è stato esteso per aggregation, il controlling unknown è la sua speciale implementazione di IUnknown: è il caso di Extended in fig. 2. Altrimenti, il controlling unknown è la speciale implementazione di IUnknown del componente più esterno (che gli è stata passata al momento della creazione): è il caso di Base in fig. 2. Come funziona QueryInterface in questa particolare implementazione? Se l’interfaccia richiesta è implementata direttamente dal componente, restituisce un puntatore all’interfaccia stessa. Altrimenti delega verso il basso, all’implementazione speciale di IUnknown dei componenti base.
Notiamo quindi che QueryInterface in generale va prima "verso l’esterno" in un unico passo, e poi eventualmente prosegue "verso l’interno" in passi successivi. Con riferimento alla fig. 2, se abbiamo a disposizione un puntatore ad IExtended e chiamiamo QueryInterface su questo per ottenere un puntatore ad IBase, il percorso è il seguente: IExtended delega al controlling unknown (freccia verso l’alto), il quale non conoscendo IBase delega al controlling unknown del componente Base, che ci restituisce IBase. Se ora chiamiamo su questo QueryInterface chiedendo un puntatore ad IExtended, questo delega al controlling unknown più esterno, che conosce IExtended e ci restituisce direttamente il puntatore. Potete provare a creare delle strutture composte più complesse, ed a navigare tra le interfacce simulando il comportamento di QueryInterface: basta poco per convincersi che in effetti il meccanismo funziona, e ci permette di passare da un’interfaccia ad un’altra con facilità (anche se non necessariamente in modo rapido).
Problemi dell’aggregation
Tutto risolto, quindi? Abbiamo trovato la soluzione perfetta per il riuso, che non risente dei problemi della fragile base class e che non richiede neppure di scrivere innumerevoli funzioni di forward? Se ascoltiamo Microsoft, la risposta è affermativa: il COM è la panacea di tutti i mali. Se proviamo a pensarci un po’ meglio, ci accorgiamo che le cose non stanno proprio così. L’aggregation mantiene molti dei problemi del wrapping, problemi peraltro ben noti in letteratura [Höl93] e facilmente riscontrabili in pratica. Non a caso, già nel 94 Digital Equipment aveva intrapreso un progetto interno per estendere il COM con l’ereditarietà di implementazione [WVP94].
Innanzitutto, con l’aggregation possiamo solo aggiungere l’implementazione di nuove interfacce. Se vogliamo modificare una sola funzione di un’interfaccia già implementata nel componente base, dobbiamo tornare al contenimento ed alle funzioni di forward. Ma questo è in realtà il problema minore: ciò che colpisce maggiormente è l’ingenuità dell’idea che le interfacce possano essere implementate in modo così totalmente separato come il COM suggerisce. E che si possa aggiungere l’implementazione di un nuovo insieme di interfacce nel componente esteso, senza in alcun modo legarsi all’implementazione del componente base.
Chi ha un po’ di esperienza di progettazione si rende subito conto che questo non è possibile. Se l’oggetto base implementa (ad es.) l’interfaccia di persistenza, e voglio aggiungere nel componente esteso l’interfaccia per la GUI, in qualche modo dovrò accedere ad alcuni dati del componente base. In OOP, questo avviene attraverso un’interfaccia privilegiata (protetta). Nel COM, esistono due strade possibili. La prima è di esporre quei dati attraverso una delle interfacce, sostanzialmente come property. Questo è ovviamente un passo indietro rispetto all’OOP, perché in COM non esistono livelli di protezione o privilegio. La seconda strada (tristemente percorsa dai primi esempi forniti con OLE2 SDK, diversi anni fa) è addirittura raccapricciante. Quando chiediamo il puntatore ad un’interfaccia al componente base, quello che otteniamo è generalmente il puntatore ad una classe concreta che implementa quell’interfaccia. Allora basta fare un cast alla classe concreta, o addirittura ad una struct con lo stesso layout, ed ecco che possiamo liberamente accedere ai suoi campi. Ovviamente, questo rende le classi ancora più accoppiate che nell’ereditarietà di implementazione dell’OOP. Va detto che questo problema di condivisione dei dati esiste anche tra le diverse interfacce di un singolo componente. L’idea iniziale di Microsoft era che ogni interfaccia fosse implementata separatamente. Ovviamente, nasceva il problema di condividere i dati tra le diverse interfacce dello stesso componente, che negli esempi dell’OLE2 SDK venivano ottenuti tramite cast alle classi concrete. Questo, peraltro, rendeva tutti i componenti forniti come esempio non aggregabili, perché la classe concreta dei componenti estesi non è ovviamente la stessa dei componenti base. Oggi Microsoft fa un passo indietro anche su questo, ed ATL permette di implementare più interfacce attraverso l’ereditarietà multipla. Risolto il problema all’interno di un singolo co
mponente, rimane purtroppo quello relativo all’estensione per aggregation. Esiste inoltre un ulteriore limite al riuso, che merita però un capitolo a sé.
Modelli di riuso
L’idea dei "circuiti integrati software", o Software IC, è così vecchia che tutti ne hanno sentito parlare; credo che la prima apparizione ufficiale risalga ad una conferenza NATO del 1968, anche se i proceedings sono stati pubblicati solo nel 1976 [McI68]. Di solito l’idea viene anche giustificata attraverso gli enormi progressi dell’hardware e della sua relativa assenza di bug se confrontato con il software.
Premetto che personalmente ritengo il paragone con l’hardware totalmente fuori luogo, ma si tratterebbe di un discorso molto lungo e che porterebbe fuori strada. Invece, vorrei soffermarmi su un punto molto importante: l’idea dei Software IC corrisponde ad un solo modello di riuso, che negli anni ha visto diverse realizzazioni. Dalla condivisione dei sorgenti, alle librerie standard di funzioni, ai componenti COM, tutto gira intorno al concetto di riuso Black Box. Purché l’implementazione delle funzioni rispetti una specifica (di solito informale: si veda [Pes97]), possiamo cambiare e comporre tra loro i componenti senza problemi. Ed in effetti, tutti abbiamo applicato questo metodo di riusare il codice, sin dai tempi del Fortran e della libreria standard del C, senza troppi problemi. I componenti COM aggiungono un ulteriore livello di sofisticazione, soprattutto quando li uniamo a degli ambienti di sviluppo grafici, ma non c’é nulla di nuovo che faccia gridare al miracolo.
Il software, però, non è l’hardware e non è neppure una casetta fatta con i mattoncini lego. Molte volte quello che vogliamo riusare non è il singolo componente, ma la struttura circostante. Vogliamo creare un programma "incompleto" che viene poi adattato a situazioni diverse. Questo modello di riuso, detto comunemente White Box, è quello promosso da framework applicativi come MFC (l’esempio è controproducente ma molto conosciuto). Nella sua concezione più elementare, un framework White Box si basa sul pattern detto "Template Method" (fig 3). La classe Application implementa OpenDocument come una sequenza di passi ben determinata, ma l’implementazione di ogni passo è demandata alla classe derivata MyApplication. Notiamo che per estendere un framework White Box, è necessario conoscere (ad esempio) la sequenza esatta dei passi; più in generale, è necessario conoscere i contesti di chiamata delle funzioni che nel succitato [Pes95] ho chiamato "di tipo 2". In genere, questo tipo di documentazione non viene fornito, il che ha contribuito a creare la leggenda che i framework White Box siano difficili da usare. Un’altra ragione è la pretesa di molti produttori di framework White Box (MFC in testa) di creare "il framework definitivo", il che porta ad aggregati informi ed inestricabili di classi. Questo non significa comunque che i framework White Box non siano utili: anzi, io li ho sempre utilizzati con ottimi risultati, creando framework specializzati per linee di prodotto, o per settori verticali, con dimensioni accettabili e molto semplici da customizzare.
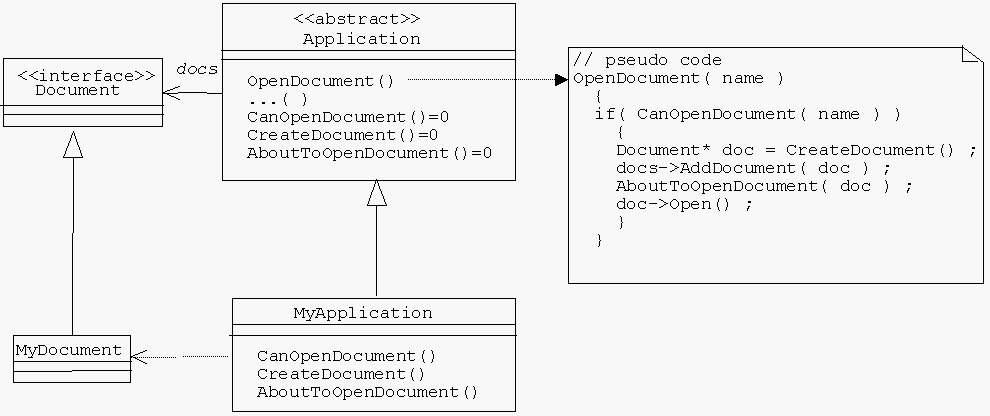
Ovviamente, un framework White Box richiede un meccanismo di ereditarietà di implementazione. Possiamo pensare di sostituirlo con un meccanismo di callback (come si fa spesso nel COM) ma chi prova a farlo si rende conto che il problema della separazione tra le singole interfacce qui acquista una nuova dimensione. Chi implementa le funzioni callback (che prendono il posto delle funzioni virtuali di tipo 2) molto spesso si trova a dover accedere ad alcuni dati del chiamante, il quale nuovamente deve esporli pubblicamente come property. Non solo, questo non ci esime dal documentare le sequenze di chiamata, ottenendo quindi il peggio dei due mondi. In conclusione, sinora il meccanismo migliore per realizzare un framework White Box è l’ereditarietà di implementazione. Altrimenti, dobbiamo limitarci ad un riuso prevalentemente Black Box, che è indubbiamente molto utile e decisamente più semplice, ma che in parecchi casi si rivela insufficiente. Oppure, dobbiamo accettare di esporre pubblicamente un maggior numero di dettagli, andando contro uno dei principi fondamentali dell’ingegneria del software (information hiding).
Implementation Inheritance in COM
Il fatto che il COM non supporti direttamente l’ereditarietà di implementazione e le funzioni virtuali "di tipo 2" non significa che queste non possano essere simulate. In fondo, il C++ non supporta direttamente l’aggregation, ma possiamo pur sempre simularla tramite una libreria come ATL, o scrivendo a mano il codice relativo.
Torniamo quindi al problema precedente, ovvero la realizzazione del pattern di fig. 3 come componente COM. Un "componente" decisamente atipico, ma COM a tutti gli effetti. Esiste una tecnica molto semplice (che non mi risulta sia mai stata presentata) per ottenere un effetto simile all’ereditarietà di implementazione rimanendo all’interno del COM. Basta introdurre una interfaccia ad-hoc (IApplSpec), che includa tutte e sole le funzioni che vogliamo rendere "di tipo 2". Dopodiché l’implementazione di OpenDocument diventa:
IApplSpec* as = NULL ;
controllingUnknown->
QueryInterface( IID_ApplSpec, &as ) ;
if( as->CanOpenDocument( name ) )
{
Document* doc =
as->CreateDocument( name ) ;
docs->addDocument( doc ) ;
as->AboutToOpenDocument( doc ) ;
doc->Open() ;
}
Notiamo che il componente che contiene il codice di cui sopra non implementa IApplSpec; di conseguenza, provando ad utilizzarlo direttamente avremo un errore analogo alla chiamata di una funzione virtuale pura. Tuttavia, possiamo ora specializzare il componente usando l’aggregation: è sufficiente che il componente aggregato implementi IApplSpec. Non solo: se il componente aggregato viene a sua volta specializzato per aggregation, ed il nuovo componente esteso re-implementa IApplSpec, le chiamate a (ad es.) CreateDocument verranno gestite come nel caso dell’ereditarietà, ovvero demandate al componente più specializzato.
Rimangono comunque i due limiti visti prima: possiamo ridefinire le funzioni solo in blocco (pena il forward), e richiediamo comunque al componente base di esporre pubblicamente sufficienti dettagli per poter implementare il componente esteso. Inoltre il risultato è sicuramente molto più lento di quello ottenibile in un linguaggio come il C++, dove il dispatch di una funzione virtuale richiede un paio di cicli di clock.
Il COM attuale e futuro
Il COM che ho sinora descritto è il modello iniziale, dove si prevedeva che per utilizzare un componente fosse necessario conoscerne a priori le interfacce; tipicamente, queste venivano distribuite come header file per il C ed il C++. Negli anni, molte cose sono cambiate. L’integrazione tra COM ed ambienti RAD, primo fra tutti il Visual Basic, ha seguito una strada un po’ accidentata. Dapprima Microsoft ha preso la scorciatoia dell’interfaccia IDispatch. In pratica, ambienti come il Visual Basic interagivano con un componente COM solo attraverso questa interfaccia, che poteva enumerare tutti i metodi di tutte le interfacce ed invocarli usando parametri variant. Ovviamente si perdeva molto in type-safety, e si costringevano i programmatori ad un doppio lavoro per implementare le interfacce "normali" ed il grande fratello IDispatch. Attualmente, come è successo per altri standard per componenti (CORBA, SOM), l’enfasi è stata spostata su un linguaggio separato per definire le interfacce (IDL). Oggi anche il Visual Basic può chiamare direttamente le funzioni delle diverse interfacce, anche se altri linguaggi (es. VB-Script) rimangono ancora limitati ad IDispatch.
Il futuro ci riserva qualche altra sorpresa, e non tutte piacevoli. Sul lato positivo, scorrendo le specifiche del COM+ si nota che verrà supportata l’ereditarietà di implementazione. Poco importa che gli evangelisti di Microsoft abbiamo speso fiumi d’inchiostro per spiegarci come l’ereditarietà fosse così decisamente inferiore all’aggregation. D’altro canto si vede anche che Microsoft punta sempre di più ad una integrazione tra il linguaggio di programmazione ed il COM: in pratica, il C++ verrà "arricchito" con costrutti proprietari che renderanno l’IDL superfluo per il programmatore. In generale, ciò che avverrà dietro le quinte del COM+ mi sembra decisamente meno controllabile dal programmatore rispetto al COM, ma al momento questa è solo una prima impressione, non corroborata da una sufficiente esperienza.
COM o non COM?
Immagino che non pochi lettori siano rimasti un po’ stupiti da quanto sopra. In un momento in cui tutti inneggiano ai componenti, è raro che qualcuno si azzardi a dire che, tutto sommato, i componenti non sono la soluzione a tutti i mali. Per non parlare delle affermazioni esagerate di Microsoft nei confronti dell’ereditarietà di implementazione, che non solo non trovano conferma nella pratica, ma che lo stesso COM+ smentisce.
Del resto, se invece di prestare orecchio al marketing guardiamo lo stato attuale dei componenti COM, credo che le conseguenze del loro limitato supporto per l’estendibilità siano sotto gli occhi di tutti. Da un lato, i componenti COM disponibili sul mercato tendono ad esporre pubblicamente moltissime property (che altro non sono che Get/Set), sia per permettere una customizzazione senza ereditarietà, sia per consentire a chi li estende per aggregation di accedere ai dati che gli servono. Dall’altro, l’aggregation è stata messa in un angolo e semplicemente ignorata dagli sviluppatori. Addirittura nei testi recenti viene appena nominata: in "Understanding ActiveX and OLE" di Chappel (un ottimo libro, peraltro), all’aggregation vengono dedicate in tutto due pagine e mezza (su quasi 350); in "The Essence of OLE with ActiveX" (un altro ottimo libro), su quasi quattrocento pagine non troviamo neppure una breve spiegazione dell’aggregation, che non appare nemmeno nell’indice analitico. Il perché è presto detto: una volta che i componenti espongono tutte le property immaginabili, i programmatori trovano molto più semplice modellare i loro programmi su una struttura a mediatore, tipicamente inserendo i componenti in un contenitore (spesso la classica form). Nei casi restanti, usano le funzioni callback. E l’aggregation semplicemente scompare. Non credo sia un caso che il COM+ supporti l’ereditarietà (singola) di implementazione: è un tentativo di riportare l’estendibilità dei componenti COM almeno ai livelli dei Java Beans. Purtroppo, la mia opinione personale è che il COM sia nato bene, come tecnologia leggera per il packaging e la distribuzione di macro-componenti, e stia crescendo male, come tecnologia pesante e mirata anche a micro-componenti.
Per chi ha dunque senso, oggi, il COM? Occorre innanzitutto distinguere tra l’uso del COM per accedere a funzionalità del sistema operativo, o per interfacciarsi con sistemi come Microsoft Transaction Server, e l’uso del COM come infrastruttura dei nostri progetti. Nel primo caso, semplicemente non abbiamo scelta. È comunque confortante pensare che in queste situazioni il COM continua a giocare il ruolo di standard per macro-componenti, che tipicamente non devono neppure essere estesi.
L’uso del COM come elemento architetturale ha una valenza diversa. Sicuramente ha senso per chi utilizza il Visual Basic, visto che le "classi" del VB sono componenti COM: di conseguenza, imparare a progettare componenti riusabili per aggregation, o simulando l’ereditarietà di implementazione come visto sopra, è l’unica scelta a disposizione. Ha senso anche per chi vuole scrivere componenti in linguaggi diversi, ed integrarli magari in Visual Basic: con tutti i suoi limiti, il COM resta il più diffuso standard language-independent per i componenti Windows. Ovviamente ha molto senso anche per chi produce componenti più che applicazioni, perché il mercato (anche limitandosi al solo VB) è certamente rilevante. La possibilità di distribuire i componenti su una rete tramite DCOM è un altro punto interessante, anche se al momento la struttura mi sembra ancora un po’ fragile.
Non ritengo invece il COM una infrastruttura applicativa interessante per chi sviluppa applicazioni in un solo linguaggio ad oggetti, ad esempio il C++, che usato opportunamente apporta tutti i vantaggi del riuso Black Box e White Box. E forse qui sta (in parte) la chiave di lettura del COM: il COM è una soluzione piuttosto drastica al problema del riuso, e le soluzioni drastiche evitano a chi le adotta di dover riflettere troppo. Usare bene l’OOP non è facile, perché la sua grande flessibilità richiede numerose scelte mirate ed una notevole capacità di progettazione. Il COM è pensato come soluzione per il riuso di massa, ed il riuso di massa deve essere semplice, anche a costo di essere limitativo. Usare il COM come infrastruttura di una applicazione sviluppata interamente in C++ significa accettarne i limiti senza ricavarne alcun beneficio. Usare il DCOM come infrastruttura di una simile applicazione può avere senso o meno, in funzione di altri fattori come la portabilità, la robustezza e la possibilità di controllo. Non di rado, usando un semplice pattern come "Half Object + Protocol" [Mes95], ed un meccanismo di IPC come i socket o le pipe, si ottiene un grado di portabilità e di tracciabilità molto più elevato. Va comunque detto che il mio giudizio è sicuramente influenzato dal tipo di progetti di cui mi occupo abitualmente. Tutto sommato, per applicazioni mission-critical preferisco avere il massimo controllo possibile, senza troppi strati tra le applicazioni ed il sistema operativo. D’altra parte, però, quale applicazione seria può essere considerata non mission-critical?
Conclusioni
Esiste una vecchia diatriba psico-filosofica riguardo l’interazione tra pensiero e linguaggio, che si estende molto bene anche ai linguaggi di programmazione. È il pensiero che plasma il linguaggio, o il linguaggio plasma il pensiero? La teoria più accreditata è che si plasmino a vicenda. Lo stesso avviene con i linguaggi di programmazione, i meccanismi che questi mettono a disposizione, e la cultura dei programmatori.
Per qualche ragione, chi usa i linguaggi ad oggetti tende spesso ad abusare dell’ereditarietà di implementazione, senza prestare le giuste cautele. Viceversa, è ormai chiaro che chi usa il COM tende ad ignorare le possibilità di estensione dei componenti, ed a favorire la composizione tramite mediatori e classi manager. In questo schema, anche varianti minori tendono a creare una differente cultura tra gli sviluppatori: in Java, l’uso dell’ereditarietà di interfaccia sta diventando molto più comune che in C++, nonostante il C++ disponga delle stesse funzionalità. Java, tuttavia, le rende più esplicite tramite le keyword "interface" ed "implements", e questo dettaglio apparentemente minore ha influito non poco sulle abitudini dei programmatori.
Per formazione ed esperienza, io tendo a privilegiare linguaggi ed ambienti di sviluppo senza complessi materni. Ambienti in cui le decisioni vengono prese dal progettista, non dai tool. Preferisco avere il problema di razionalizzare l’uso degli strumenti disponibili, piuttosto che cercare in tutti i modi di scavalcare i limiti imposti da una eccessiva semplificazione. Ad esempio, il mio libro "C++ Manuale di Stile" è in gran parte il risultato di un processo di razionalizzazione del C++, che con la sua grande potenza si presta facilmente all’abuso. In altri ambienti ci si scontra con il problema opposto, la ricerca continua del trucco che scavalca le restrizioni degli strumenti disponibili. In quest’ottica, i componenti COM appartengono alla seconda categoria più che alla prima, e personalmente li considero una soluzione adeguata solo in situazioni molto delimitate.
Bibliografia
[Höl93] Urs Hölzle, "Integrating Independently-Developed Components in Object-Oriented Languages", ECOOP ’93 Proceedings, Springer Verlag.
[McI68] M.D. McIlroy "Mass Produced Software Components", in "Proceesings of 1968 NATO Conference on Software Engineering Conference", Van Nostrand Reinhold, 1976.
[Mes95] Gerard Meszaros, "Pattern: Half-object + Protocol", in Coplien, Schmidt, "Pattern Languages of Program Design", Addison-Wesley, 1995.
[Pes95] Carlo Pescio, "Il problema della fragile base class in C++", Computer Programming No. 41.
[Pes97] Carlo Pescio, "Oggetti ed Interfacce", Computer Programming No. 63.
[WVP94] Shawn Woods, Mike Vogl, John Parodi, "Class Inheritance and the Common Object Model", Technical Report, Digital Equipment Corporation, 1994.
Biografia
Carlo Pescio (pescio@eptacom.net) svolge attivitŕ di consulenza in ambito internazionale nel campo
delle tecnologie Object Oriented. Ha svolto la funzione di Software Architect in grandi progetti per
importanti aziende europee e statunitensi. Č incaricato della valutazione dei progetti dal
Direttorato Generale della Comunitŕ Europea come Esperto nei settori di Telematica e Biomedicina.
Č laureato in Scienze dell'Informazione ed č membro dell'ACM, dell'IEEE e della New York Academy
of Sciences.