Oggetti e Thread
|
|
Dr. Carlo Pescio Oggetti e Thread |
Pubblicato su Computer Programming No. 65
L'approccio classico al multithreading in OOP non è certo privo di limiti. Esistono però modelli alternativi, più semplici e più potenti.
La programmazione ad oggetti sta diventando di impiego comune. Lo stesso si può dire per i thread, che ormai non spaventano più nessuno e vengono utilizzati anche all'interno di programmi non troppo sofisticati. Ma il matrimonio fra oggetti e thread nei linguaggi ad oggetti "tradizionali", come il C++ o Java, è stato condizionato da una visione fortemente legata al passato, che ha imposto non pochi limiti. Dopo aver analizzato i problemi dell'approccio "classico" agli oggetti attivi, vedremo anche un modello alternativo, più semplice ma anche più potente ed espressivo. Vedremo anche che per implementare questo modello in un linguaggio tradizionale è necessario rimboccarsi le maniche, e quali guide metodologiche possiamo seguire per evitare sorprese di sincronizzazione.
L'approccio classico
Sia in Java che in C++ (o meglio, nelle numerose librerie che implementano un supporto al multithreading in C++) il multithreading è basato su una visione decisamente "classica" degli oggetti attivi, fortemente legata al concetto di coroutine nella programmazione procedurale da cui entrambi i linguaggi provengono.
Rivediamo quindi brevemente la radice procedurale del multithreading: in un linguaggio come il C o il Pascal in ambiente multithreaded, esisterà una funzione che chiamerò CreateThread, avente tra i parametri un puntatore a funzione. CreateThread farà quindi partire un nuovo thread (dotato di un suo stack privato) che inizierà l'esecuzione partendo proprio dalla funzione passata come parametro. Notiamo l'importanza di avere uno stack separato per ogni thread: più thread possono infatti eseguire la stessa funzione, ed in mancanza di uno stack separato si avrebbero problemi di condivisione per le variabili locali.
Passare dalla visione procedurale a quella object oriented sembra banale: basta creare una classe Thread, con un metodo Start. Al suo interno Start chiamerà CreateThread, passando un opportuno puntatore a funzione come parametro: tale funzione verrà quindi eseguita come un nuovo thread. L'unica difficoltà sta nel decidere quale funzione utilizzare come parametro, tenendo presente che in C++ una funzione membro di una classe non è utilizzabile in sostituzione di una funzione esterna (stile C/Pascal), come la nostra ipotetica CreateThread richiede.
Il problema è però facilmente risolvibile: in pratica tutte le versioni di CreateThread disponibili sui vari sistemi operativi prendono anche un void* o un long integer come "parametro ausiliario" da passare alla funzione chiamata. Quindi in C++ possiamo pensare ad una soluzione simile alla seguente:
class Runnable
{
public :
virtual void Run() = 0 ;
} ;
class Thread
{
public :
Thread( Runnable* r )
{
// ...
toRun = r ;
}
void Start() ;
{
CreateThread( ...,
StartAux,
toRun ) ;
// StartAux viene chiamata
// con toRun come parametro
}
private :
Runnable* toRun ;
// ...
} ;
void StartAux( void* p )
{
Runnable* r =
static_cast< Runnable* > p ;
p->Run() ;
}
Vediamola a grandi linee: Runnable rappresenta un'interfaccia per ogni classe di oggetti che vogliamo rendere "attivi"; è l'esatto analogo dell'omonima interfaccia di Java. La classe Thread prende come parametro un oggetto di classe derivata da Runnable, che implementa quindi la funzione Run(). Tale funzione verrà eseguita (per l'oggetto passato come parametro) all'interno del nuovo thread. La funzione Thread::Start() non fa altro che chiamare CreateThread (o qualunque funzione si debba utilizzare sul sistema operativo target), passando la funzione ausiliaria StartAux come start point per il thread ed il puntatore all'oggetto ottenuto nel costruttore come parametro ausiliario (convertito a void*, in quanto StartAux deve essere conforme alle richieste di CreateThread). StartAux non fa altro che riconvertire il parametro in un puntatore a Runnable, e chiamare la funzione Run.
Questa soluzione, al di là delle differenze legate alla funzione CreateThread nei vari sistemi operativi, ricalca quella proposta da Java [AG96]: un'interfaccia Runnable che va implementata da tutti gli oggetti attivi, ed una classe Thread che si preoccupa di "far girare" un oggetto Runnable in un nuovo thread di esecuzione. In C++ esistono poi alcune variazioni sul tema: ad esempio, utilizzando i template possiamo evitare di dover derivare una classe da Runnable per renderla attiva. Oppure, con opportune estensioni come la closure del Borland C++ Builder, possiamo evitare la funzione ausiliaria e passare direttamente una chiusura (ovvero, un oggetto + funzione membro visibili come funzione esterna). Si tratta comunque di dettagli di design che non si distaccano in modo sostanziale dall'approccio classico. Approccio che, come ho anticipato, sembra semplice e lineare ma in realtà è non solo limitativo, ma anche decisamente non object oriented!
L'approccio classico rivisto
Uno dei lati peggiori dell'approccio classico è che incoraggia l'uso di "oggetti funzione", ovvero di oggetti che fanno una sola cosa (eseguono il codice di Run) per la loro intera esistenza. Questo non è un buon metodo di progettazione di una classe: dovremmo invece riunire in un oggetto le funzioni ed i dati propri di una astrazione significativa del dominio del problema o della soluzione [Pes95], criterio peraltro già noto sin dai primi rilevanti lavori di ingegneria del software [Par72]. L'esistenza dei thread dovrebbe essere ben amalgamata con gli oggetti, ma nell'approccio classico finisce per alterare il concetto stesso di oggetto.
D'altra parte, è relativamente raro che ci si possa accontentare di una classe con un solo metodo Run(): anche i pochi oggetti che si adattano abbastanza bene alle limitazioni di una sola funzione principale, hanno poi la necessità di esporre alcuni altri servizi secondari. Pensiamo ad una classe PrintDocument il cui metodo Run stampa un intero documento; anche in questo semplice caso sarebbe utile poter interrogare l'oggetto circa lo stato di avanzamento, oppure poter interrompere la stampa, farla ripartire, eccetera. Ed in effetti l'approccio classico non ci impedisce di farlo: semplicemente, queste funzioni non verranno eseguite nel thread dell'oggetto cui appartengono, ma nel thread dell'oggetto chiamante. Possiamo chiarire meglio questo aspetto (che spesso sfugge a chi si trova ad usare l'approccio classico "per necessità") attraverso un semplice esempio. Ho utilizzato Java per comodità e platform independence, ma il codice è facilmente comprensibile anche da chi mastica solo il C++.
class PrintDocument implements Runnable
{
public Print( Document d )
{
doc = d ;
// lancia un nuovo thread,
// che eseguirà la
// funzione run().
new Thread( this ).start() ;
}
public void run()
{
// stampa il documento
}
public int GetProgress()
{
// ...
}
public void Suspend()
{
// ...
}
// ...
private Document doc ;
}
class WordProcessor
{
public void Print()
{
printDoc.Print( doc ) ;
}
public void SuspendPrinting()
{
printDoc.Suspend() ;
}
// ...
private Document doc ;
private PrintDocument printDoc ;
}
Il codice è molto semplice: quando un oggetto WordProcessor vuole stampare il suo documento, chiede ad un sotto-oggetto PrintDocument di stamparlo. PrintDocument è un "oggetto attivo", ovvero implementa l'interfaccia Runnable. Il suo metodo Print() non fa altro che creare un nuovo thread e mandarlo in esecuzione, usando se stesso come parametro. L'oggetto Thread chiama quindi il metodo run() del suo parametro (in questo caso lo stesso oggetto PrintDocument), che finalmente comincia l'operazione di stampa. Se l'utente decide di interrompere la stampa per qualche ragione, occorre in qualche modo notificare PrintDocument. Nell'approccio classico, "basta" chiamare un metodo di PrintDocument, in questo caso Suspend(). Tutto semplice e lineare, ma vediamo meglio, con l'aiuto della figura 1, la relazione tra oggetti e thread. Ho usato un colore diverso per ogni classe, ed una colonna per ogni thread.
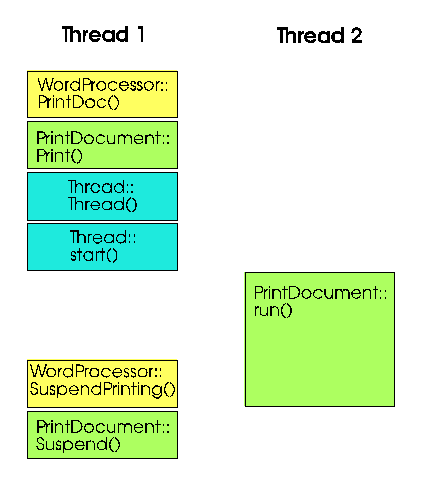
Possiamo vedere subito che il codice dell'oggetto di classe PrintDocument viene eseguito in due thread diversi; potenzialmente, in n thread diversi. Vi è quindi una completa trasversalità tra oggetti e thread: anche se continuiamo a parlare di PrintDocument come di un "oggetto attivo", di fatto questo non è vero. PrintDocument è un oggetto come gli altri, con altri oggetti e thread che chiamano le sue funzioni. Inoltre ha una particolare funzione che viene sempre eseguita in un thread separato, e che per convenzione gli altri thread non chiamano mai.
Questa trasversalità ha due conseguenze importanti: la necessità di sincronizzare l'accesso ai dati dell'oggetto (che vedremo tra breve) e l'assoluta mancanza di scalabilità dell'approccio classico. Osserviamo infatti che una condizione necessaria affinché l'approccio classico funzioni è che un thread possa "manipolare" i dati che appartengono ad un altro thread, e che le funzioni di ogni classe siano accessibili in tutti i thread. Nel nostro caso, l'oggetto di classe PrintDocument viene creato nel thread 1, la sua funzione principale (che ovviamente userà i dati dell'oggetto) viene eseguita nel thread 2, e Suspend() viene chiamata nuovamente all'interno del thread 1 (anche se in teoria potrebbe essere chiamata da un ulteriore thread). Pensiamo a cosa succederebbe passando da un diverso thread ad un diverso processo: i dati non sarebbero più liberamente accessibili da tutti, perché di norma ogni processo ha un suo spazio di indirizzamento. E se passiamo ad un altro computer, in una architettura distribuita? Anche qui, la trasversalità tra oggetti ed elemento di esecuzione (thread, processo o computer) si rivela impossibile. Non a caso, in Java abbiamo un supporto completamente separato per "oggetti attivi" che non girano nella stessa JVM (dobbiamo usare la Remote Method Invocation). Insomma, l'approccio classico porta ad un design costruito intorno ad
una serie di assunzioni piuttosto limitative:
Sincronizzazione
Abbiamo visto che, nell'approccio classico, funzioni dello stesso oggetto vengono normalmente chiamate da thread diversi. Ovviamente sono necessarie le opportune cautele per evitare comportamenti indesiderati. Pensiamo al classico esempio del conto in banca: il codice che gestisce lettura ed aggiornamento del saldo deve essere eseguito senza interruzioni, altrimenti potremmo avere un fenomeno di cancellazione:
Thread 1 - legge il saldo corrente (s)
Thread 2 - legge il saldo corrente (s)
Thread 1 - aggiorna il saldo corrente (s = s+x)
Thread 2 - aggiorna il saldo corrente (s = s+y)
Alla fine il saldo corrente risulta s + x anziché s + x + y. In genere, vorremmo che molte operazioni venissero eseguite in modo atomico, non interrompibile. Java riconosce questa necessità e mette direttamente a disposizione una keyword synchronized. Synchronized si può usare in diversi contesti, ma l'esempio classico è quello di un metodo synchronized; quando si chiama un metodo synchronized di un oggetto, l'oggetto entra nello stato locked. Se un altro thread chiama un metodo synchronized dello stesso oggetto, verrà posto in attesa sino a quando il primo metodo non terminerà l'esecuzione. In C++, possiamo facilmente ottenere la stessa funzionalità usando un template stile smart-pointer, una classe ausiliaria per il lock/unlock, ed una sezione critica. Se lo implementiamo nel modo giusto, possiamo avere una sintassi del tutto trasparente, ovvero continuare a chiamare i metodi con la sintassi obj->f() ed ottenere le stesse funzionalità dei metodi synchronized di Java. Tutto risolto, quindi? Niente affatto.
Ancora una volta, i metodi synchronized corrispondono ad una visione fasulla degli oggetti attivi. Se ci pensate bene, i metodi synchronized sono basati sull'idea che altri oggetti vadano a "pasticciare" con gli oggetti attivi e che sia quindi necessario "regolamentare" l'accesso per evitare problemi. Ma in
generale, il mondo "reale" non funziona affatto così (ricordiamo che l'OOP ha un suo punto di forza nella capacità di modellare più da vicino lo spazio dei problemi). Pensiamo all'oggetto attivo per definizione: una persona, ad esempio un cameriere. Il cameriere arriva, ordiniamo dei piatti, poi va in cucina e trasmette la lista ad un altro oggetto attivo (il cuoco). Dopodiché il cameriere fa altre cose, così come gli altri oggetti attivi. Ad un certo punto i piatti desiderati (o alcuni di essi) saranno pronti, e il cameriere potrà portarli al tavolo. Notiamo che il modello descritto non assomiglia affatto ad uno ottenibile con semplicità nell'approccio classico. Intanto, cameriere, cuoco ed avventore non hanno una "funzione principale" che viene fatta partire da un thread e va avanti sino al completamento. Eseguono invece una varietà di compiti, in funzione di stimoli esterni. Come vedremo, per ricondurre all'approccio classico il nostro modello, dobbiamo introdurre degli elementi artificiali come il message loop ben noto a chi programma in ambienti event-driven. La funzione principale diventa quindi null'altro che un dispatcher. Inoltre, i metodi synchronized non sono affatto sufficienti. Anzi, dovremmo chiederci se sono utili, perché nel mondo reale un non avviene mai che un oggetto esegua i metodi di un altro oggetto all'interno del proprio thread: sarebbe come se un cliente, dopo aver ordinato, prendesse di peso il cameriere e lo portasse dal cuoco a comunicare l'ordinazione. Ed infatti, quando cominciamo a modellare problemi reali ci rendiamo conto che al di là del semplice supporto fornito dai metodi synchronized dobbiamo imparare ad utilizzare le classiche primitive di sincronizzazione wait/notify, imparare a prevenire il deadlock, e così via.
Come sempre, tutto risulta più chiaro passando ad un esempio. Riprendendo il caso del ristorante, pensiamo ad una classe Cuoco. Nel nostro modello, un cuoco aspetta
di avere una ordinazione, poi prepara il piatto corrispondente ed attende che il cameriere lo prelevi. Possiamo ipotizzare diversi "funzionamenti" per il cuoco: ad esempio, potrebbe passare subito a preparare il piatto dell'ordinazione successiva, o aspettare che il cameriere porti via il piatto appena preparato, o ancora (e più ragionevolmente) preparare fino ad N piatti in attesa che il cameriere venga a prelevarli. Un cuoco, quindi, ha una coda di input per le ordinazioni, un metodo che trasforma ordinazioni in piatti, ed una coda di uscita per i piatti. Entrambe le code potrebbero avere dimensione finita. Come possiamo strutturare il suo metodo Run() nell'approccio classico?
Innanzitutto, il cuoco dovrà attendere la presenza di una ordinazione nella coda di input. Poi dovrà processare l'ordinazione in qualche modo ed alla fine proverà ad inserirla nella coda di output. Infine tornerà ad attendere una ordinazione, e così via. Le code di input ed output sono elementi passivi (ovvero non possiedono un loro thread di esecuzione), ma i loro metodi vengono eseguiti da thread diversi (il cuoco ed il cameriere). Osserviamo, come premesso, che ci stiamo avvicinando alla struttura dei programmi event-driven tradizionali (nel paradigma imperativo, non object oriented): un loop degli eventi/messaggi, una coda degli eventi/messaggi di input, un'unica funzione che preleva gli eventi e li processa. Inoltre le code di cui sopra dovranno ovviamente avere metodi synchronized (l'aggiunta e la rimozione di elementi devono essere operazioni atomiche) ma certamente synchronized non basta. Pensiamo infatti ad una operazione di prelievo di un elemento: cosa succede se la coda è vuota? Il thread attivo (ad esempio il cuoco) dovrà fermarsi ed aspettare sino a quando qualche altro thread inserirà una richiesta nella coda. In C++ potremmo usare una chiamata di attesa su un evento, in Java useremo un loop con una chiamata a wait() nel corpo. Al momento dell'inserime
nto, in C++ dovremmo "segnalare" l'evento (sbloccando così l'altro thread), mentre in Java useremo la funzione notify() per sbloccare il thread del cuoco. Analogamente, quando inseriamo un piatto nella coda di input dobbiamo attendere che vi sia posto. In entrambi i casi, synchronized ci aiuta a gestire l'atomicità dell'operazione, ma la sincronizzazione vera e propria è a carico del programmatore, così come la responsabilità di garantire l'assenza di deadlock nel protocollo di sincronizzazione.
Un approccio migliore
Per ottenere reali benefici dall'unione di oggetti e thread dobbiamo recidere il legame con la tradizionale visione del thread come funzione, eliminando quindi il famoso metodo Run(). Dobbiamo invece partire dagli oggetti, e definire cosa voglia dire "oggetto attivo". Nel modello SCOOP (Simple Concurrent Object Oriented Programming) [Mey93], un oggetto attivo è un oggetto che "gira" su un processore virtuale. Il processore virtuale può essere un diverso thread sullo stesso processore fisico o su un processore diverso, oppure un diverso processo o anche un diverso computer, magari attraverso una connessione internet. Cosa significa che l'oggetto "gira" su un diverso processore virtuale? Molto semplicemente, che ogni chiamata di funzione su quell'oggetto verrà eseguita dal processore virtuale. Da notare l'accento su ogni: non esiste un metodo privilegiato Run() che gira in un thread separato. Qui tutte le chiamate di funzione ad un oggetto attivo (che in SCOOP viene detto oggetto separate) girano nel thread che è proprio di quell'oggetto. Questo cambio di prospettiva ha due importanti conseguenze: da un lato, diventa molto più semplice programmare ad oggetti in modo concorrente; dall'altro, diventa molto più complicato, per chi scrive il compilatore, fornire il necessario supporto basandosi solo sulla nozione non-object-oriented di thread che i sistemi operativi tradizionali forniscono. Al momento, l'unico ambiente che fornisce una adeguata implementazione di SCOOP è Eiffel, il che non dovrebbe stupire dato che l'ideatore di SCOOP è lo stesso Bertrand Meyer che ha progettato Eiffel.
Non a caso, nella mia intervista [Pes97] l'ho definito "uno dei pensatori più originali nel campo della tecnologia ad oggetti". Le idee alla base di SCOOP sono semplici, ma "rompono" una lunga tradizione che vede il thread come una funzione. In quanto segue vedremo brevemente i due concetti fondamentali (preco
ndizioni come sincronizzazioni e wait by necessity), utilizzando per gli esempi uno pseudo-C++, e cercheremo poi di riportare alcuni insegnamenti all'interno della programmazione di ogni giorno, in ambienti più tradizionali.
Precondizioni e sincronizzazione
Riprendiamo l'esempio del cuoco, concentrandoci per semplicità sulla funzione che aggiunge una richiesta alla sua coda di ingresso: Cook::AddRequest(). Dimentichiamoci per un attimo la programmazione concorrente e proviamo ad impostare la classe Cook e la funzione AddRequest.
class Request
{
...
} ;
class Cook
{
public :
void AddRequest( Request& r )
{
assert( ! in.IsFull() ) ;
in.Add( r ) ;
}
private :
BoundedQueue< MAXREQ, Request > in ;
// ...
} ;
Come visto al paragrafo precedente, la classe Cook utilizza internamente una coda finita per le richieste in input: ho ipotizzato l'esistenza di un template BoundedQueue con due parametri (il numero di elementi nella coda ed il tipo degli elementi). Notiamo l'asserzione all'interno di AddRequest: il chiamante non può aggiungere più di MAXREQ elementi alla coda. Nella programmazione "tradizionale" (non concorrente), una simile precondizione viene utilizzata per specificare meglio i vincoli che Cook impone al chiamante, ed allo stesso tempo come strumento di debugging. Pensiamo a cosa succede passando alla programmazione concorrente, dove un oggetto di classe Cook viene gestito da un diverso processore virtuale:
separateCook* cook = new Cook() ; // ... Request r ; cook->AddRequest( r ) ;
La parola chiave separate non fa parte del C++, ma secondo il modello SCOOP dovrebbe assegnare un diverso processore virtuale (ad esempio un nuovo thread) all'oggetto cook. Quindi se la chiamata cook->AddRequest( r ) avviene in un thread T1, l'esecuzione di AddRequest avverrà interamente in un thread T2. Notiamo ancora una volta la differenza con il modello tradizionale, dove l'esecuzione di AddRequest avverrebbe sempre in T1, mentre l'oggetto cook sarebbe impegnato a far girare la funzione Run, qui del tutto assente nel thread T2. Il fatto che l'esecuzione di AddRequest avvenga in un thread diverso significa che T1 passerà immediatamente ad eseguire la prossima istruzione, senza aspettare che AddRequest finisca.
Dobbiamo però chiarire due punti molto importanti: cosa succede se l'oggetto cook è già impegnato, e cosa succede alle precondizioni in ambiente concorrente. Supponiamo infatti che un terzo thread T3 abbia chiamato cook->AddRequest prima di T1, e che T2 non abbia ancora terminato l'esecuzione di AddRequest. Allora qualunque chiamata ad un metodo dell'oggetto cook dovrà necessariamente aspettare che il processore virtuale associato a cook sia libero: quindi la chiamata cook->AddRequest( r ) all'interno di T2 dovrà attendere che l'oggetto cook sia disponibile. Ciò equivale a dire che ogni chiamata di funzione su un oggetto separate è automaticamente synchronized. Nella sua formulazione attuale, SCOOP prevede la possibilità di specificare un timeout per le chiamate di funzione su un oggetto separate. Se l'oggetto non è disponibile entro un tempo specificato, viene sollevata un'eccezione. Questo corrisponde all'idea che la chiamata non è stata completata correttamente: l'uso attento delle feature già disponibili evita quindi l'introduzione di nuovi concetti. Veniamo adesso al secondo punto, vera chiave di volta per la semplificazione della programmazione c
oncorrente: mentre in una visione sequenziale le precondizioni devono essere rispettate dal chiamante, e definiscono quindi un contratto tra gli oggetti, in una visione concorrente le precondizioni diventano necessariamente delle condizioni di sincronizzazione.
Pensiamoci bene: se il programma è sequenziale, il chiamante può garantire il rispetto della precondizione ! in.IsFull(), ad esempio chiamando una funzione di Cook che verifica se c'é ancora posto nella coda delle richieste. Ma in un programma concorrente, il chiamante non ha alcun modo per esserne certo: tra la verifica della precondizione e la chiamata ad AddRequest, un altro thread potrebbe riempire la coda. Sembrerebbe che non ci sia altra via d'uscita se non il ritorno alle primitive di lock dell'approccio tradizionale, ma non è così. In SCOOP, una precondizione che coinvolga i data member di un oggetto diventa una condizione di sincronizzazione. Quindi, nel listato precedente in ambiente concorrente, il thread T1 non deve preoccuparsi di garantire la precondizione: il sistema aspetterà che sia valida prima di eseguire AddRequest. È importante capire bene il passaggio: la precondizione deve diventare una condizione di sincronizzazione, perché in ambiente concorrente il chiamante non ha modo di garantire un certo stato interno dell'oggetto chiamato. Se la coda di un oggetto Cook separate è piena, AddRequest dovrà attendere sino a quando l'oggetto stesso avrà prelevato un elemento, lo avrà processato, ed inserito il risultato nella coda di uscita. Tutto questo senza la necessità di ri-progettare Cook per il funzionamento concorrente, ma semplicemente attraverso una nuova keyword separate ed un supporto più intelligente da parte del compilatore.
Wait by necessity
Torniamo ancora una volta all'esempio del ristorante: mentre un cameriere può aggiungere la sua richiesta alla coda senza aspettarne il processing, lo stesso non avviene quando vuole prelevare un piatto per portarlo al cliente. Evidentemente, il modello totalmente asincrono che abbiamo visto sinora ha dei limiti, che ancora una volta SCOOP supera all'insegna della semplicità. I metodi che non restituiscono un valore avranno esecuzione asincrona (come visto sopra), mentre i metodi che restituiscono un valore avranno esecuzione sincrona. Quindi, se la classe Cook implementa un metodo GetDish(), in uno scenario come il seguente:
separateCook* cook = new Cook() ; // ... Dish d = cook->GetDish() ;
L'esecuzione di cook->GetDish() sarà comunque sincrona: anche se GetDish viene eseguito da un altro processore virtuale, il thread chiamante non proseguirà sino a quando il valore di ritorno non sarà disponibile. Questo metodo di sincronizzazione viene detto Wait by Necessity [Car89], intendendo che i chiamanti non dovranno mai aspettare a meno che non sia assolutamente necessario. In genere possiamo pensare ad una struttura come:
separateC* c = new C () ; c->f() ; // ... // fa altre cose // ... // ora ha bisogno di un risultato da c R r = c->GetRes() ;
Sino a quando non abbiamo bisogno di un risultato, l'esecuzione può andare avanti in modo asincrono, secondo quanto visto prima. Notiamo la completa assenza di primitive di lock, notifiche, e così via; il modello SCOOP, anche se leggermente più complesso di quanto visto sinora, riesce effettivamente a semplificare in modo sostanziale la programmazione concorrente/distribuita ad oggetti. Perché concorrente/distribuita? In quanto sopra, non ho fatto menzione di come venga specificato il tipo di processore virtuale da utilizzare. SCOOP propone un file di configurazione esterno al codice vero e proprio (che rimane invariato) e che permette di specificare come reperire un processore virtuale nelle varie situazioni. Sta al sistema generare il codice migliore nel caso si tratti di un thread, di un diverso processo, di un mapping verso CORBA, eccetera. Di nuovo, ci troviamo ad un livello di astrazione ben più alto di Java, che porta a scrivere codice diverso per oggetti locali e remoti, e quindi a cablare nel codice decisioni che potrebbero variare nel corso del tempo. Oltre al già citato [Mey93], potete trovare una approfondita discussione del modello SCOOP all'interno di Eiffel nel più facilmente reperibile (ma meno economico) [Mey97].
Chiudiamo il cerchio
Quando ho letto i primi lavori su SCOOP ho capito che si trattava di un deciso passo in avanti rispetto all'approccio classico, ma come sempre nei progetti reali ci si trova più facilmente a lavorare con linguaggi ed ambienti consolidati, piuttosto che con strumenti tecnologicamente all'avanguardia (con buona pace di chi ritiene i Wizard del Visual C++ il massimo della tecnologia). Tuttavia, possiamo rimanere in C++ o in Java ed imparare molto dal modello SCOOP. La prima, importante lezione è metodologica: ogni precondizione di C::f() sui data member di C implica la necessità di una sincronizzazione sofisticata per la funzione f, non fornita da una primitiva come synchronized o da una semplice sezione critica intorno all'oggetto. Da sola, questa linea guida può evitare una discreta quantità di errori da mancata sincronizzazione, soprattutto in Java dove si è propensi a credere che un semplice synchronized metta al riparo da ogni problema. La seconda lezione è implementativa: pensare in termini del modello SCOOP ci fornisce anche delle indicazioni su come potremmo costruire la "sincronizzazione sofisticata" di cui sopra in un ambiente tradizionale, in termini di wait e notify.
A dire il vero, ho anche cercato di "ricreare" un supporto automatico per SCOOP in C++, ma anche con la gran quantità di funzionalità del linguaggio, non sono riuscito a creare una sorta di template per oggetti separate. È invece possibile creare manualmente dei wrapper intorno a degli oggetti esistenti, in modo da farli funzionare come oggetti attivi secondo il modello SCOOP. La classe wrapper dovrebbe avere la stessa interfaccia della classe originale, con tutti i metodi synchronized (ricordo che in C++ questo è facilmente ottenibile con una sezione critica). Avrà anche, come necessario, una funzione Run(), della quale parlerò fra breve. Dopodiché, per ogni funzione della classe originale, dov
remo trovare le precondizioni sui data member e trasformarle in condizioni di sincronizzazione, tipicamente usando una funzione ausiliaria ed un semaforo. A questo punto, il corpo di ogni funzione della classe wrapper seguirà uno degli stili seguenti:
// comando asincrono
void WrappedC :: f( p1, ..., pn )
{
- copia i parametri in altrettanti data member
- attende che le precondizioni siano soddisfatte
- funzione da eseguire = f
- sveglia il thread
}
// funzione sincrona
T Wrapped :: g( p1, ..., pn )
{
- copia i parametri in altrettanti data member
- attende che le precondizioni siano soddisfatte
- funzione da eseguire = g
- sveglia il thread
- attende il risultato
- return( res ) ;
}
La funzione Run() sarà invece modellata su questo stile:
void WrappedC :: Run()
{
do
{
wait() ;
switch( funzione da eseguire )
{
case f :
{
chiama C::f usando i parametri
copiati localmente
break ;
}
// ...
}
}
}
Come vedete, Run() aspetta che ci sia una richiesta da esaudire, poi la processa. È proprio la copia di parametri in data member locali nelle singole funzioni, e la successiva chiamata della funzione corrispondente in un thread diverso, che non sono mai riuscito ad implementare in modo trasparente in C++. Del resto, rispetto al codice generabile da un compilatore, non siamo certamente al massimo dell'efficienza, a causa della copia e dello switch/case. Certe funzionalità sono difficili da implementare senza un adeguato supporto del linguaggio: nei casi reali, quindi, il programmatore dovrà imporre dei vincoli per rendere la sua implementazione più efficiente. Ad esempio, potremmo usare solo il passaggio per riferimento o per puntatore, in modo che la copia sia efficiente. Potremmo anche usare direttive system dependent anziché il case/switch. In Windows, ad esempio, possiamo cambiare l'instruction pointer di un thread usando la funzione SetThreadContext. Restringendo a sufficienza la generalità della soluzione, possiamo trovare un buon compromesso tra l'applicazione sistematica di una tecnica sofisticata per la sincronizzazione e la necessità di scrivere codice efficiente.
Conclusioni
Uno dei vantaggi di una visione non-religiosa dei linguaggi è che si può imparare molto da ognuno di essi, e riportare parte di quella conoscenza all'interno del lavoro di ogni giorno. SCOOP resta un po' lontano dalla realtà di chi lavora in C++, Java e molti altri linguaggi, ma ci fornisce sia una guida teorica che una implementativa per la scrittura di programmi concorrenti ad oggetti. Una volta capiti i principi, possiamo applicare almeno in parte le tecniche.
Una nota finale: se programmate in C++, non dimenticate che potete abbonarvi gratuitamente a C++ Informer, la mia newsletter elettronica via email, semplicemente compilando il modulo di richiesta. Troverete tutte le informazioni sulla mia pagina web: http://www.programmers.net/artic/Pescio.
Bibliografia
[AG96] Ken Arnold, James Gosling, "The Java Programming Language", Addison-Wesley, 1996.
[Car89] Denis Caromel, "Service, Asynchrony, and Wait-by-Necessity", Journal of Object Oriented Programming, Nov-Dec 1989.
[Mey93] Bertrand Meyer, "Systematic Concurrent Object Oriented Programming", Communications of ACM, September 1993.
[Mey97] Bertrand Meyer, "Object-Oriented Software Construction", Prentice Hall, 1997.
[Par72] David L. Parnas, "On the Criteria to be Used in Decomposing Systems into Modules", Communications of ACM, December 1972.
[Pes95] Carlo Pescio, "Object Oriented Analysis", Computer Programming, Aprile 1995.
[Pes97] Carlo Pescio, "Intervista a Bertrand Meyer", Computer Programming, Settembre 1997.
Biografia
Carlo Pescio svolge attivitŕ di consulenza e formazione in ambito internazionale nel
campo delle tecnologie Object Oriented. Ha svolto la funzione di Software Architect in
grandi progetti per importanti aziende europee e statunitensi. Č l'ideatore del metodo
di design ad oggetti SysOOD (Systematic Object Oriented Design), ed autore di numerosi
articoli su temi di ingegneria del software, programmazione C++ e tecnologia ad oggetti,
apparsi sui principali periodici statunitensi. Laureato in Scienze dell'Informazione,
č membro dell'ACM e dell'IEEE.