Architettura di Sistemi Reattivi, Parte 2
|
|
Dr. Carlo Pescio Architettura di Sistemi Reattivi, Parte 2 |
In questa seconda puntata della mini-serie dedicata ai Sistemi Reattivi completeremo gran parte dell'architettura complessiva, gestendo i messaggi e generando il necessario feedback verso l'esterno.
Nella scorsa puntata abbiamo iniziato a progettare
l'architettura del nostro sistema reattivo, introducendo via via
delle classi astratte per isolare i punti di variabilitŕ del
mondo esterno. Abbiamo quindi introdotto una classe astratta I/O
per virtualizzare l'interfaccia verso i dispositivi, una classe
astratta Parser ed una classe DeviceIndependentMessage per
virtualizzare i dispositivi stessi. Abbiamo inoltre deciso di
optare per uno schema a parallelismo massimo, dove il
riconoscimento dei messaggi e la gestione di ognuno di essi avviene
in thread separati, eventualmente con pooling.
In questa puntata affronteremo il problema di gestire le
attivitŕ connesse con ogni messaggio, nonché la politica
di sistema per la supervisione dei messaggi stessi. Procederemo poi
chiudendo il ciclo e fornendo il necessario feedback verso il mondo
esterno. Nel fare questo, continueremo a porre la giusta attenzione
ai requisiti iniziali di estendibilitŕ, testabilitŕ, e
fault tolerance del sistema.
Gestione dei Messaggi
Il titolo di questo paragrafo č volutamente
sbagliato; "gestire i messaggi" significa infatti ritornare ad una
visione procedurale dell'architettura di sistema. Significa
introdurre il solito, rassicurante elemento di controllo
centralizzato, che riconosce i vari messaggi e svolge delle azioni
in funzione di ognuno di essi. Significa anche rinunciare ai
benefici di estendibilitŕ, riusabilitŕ e gestione della
complessitŕ che costituiscono le grandi promesse degli
oggetti.
Un messaggio non deve essere gestito: dovrebbe sapersi
"gestire" da sé. Questa č la prospettiva degli oggetti,
semplice ed evidente quando ci si pensa, eppure cosě
sfuggevole quando si inizia a progettare con una impostazione
procedurale.
Naturalmente, il sistema puň (e in molti casi deve) comunque
intervenire sulla gestione dei messaggi, ma con una politica di
piů alto livello: ad esempio, decidere la prioritŕ di
ognuno di essi, o decidere (in caso di sovraccarico del sistema)
quali oggetti-messaggio debbano essere attivati e quali
semplicemente ignorati. Piů in generale, il sistema deve
governare le attivitŕ dei messaggi (che diventano elementi
attivi) sovraimponendo alle loro "volontŕ individuali" una
politica di sistema. Un insieme di tecniche interessanti che
possono far parte di questo componente di regolamentazione č
stato presentato in [Mes96].
Vediamo alcuni esempi: in generale, un sistema reattivo deve
probabilmente contenere un elemento in grado di gestire un
sovraccarico temporaneo, ed eventualmente uno incaricato di
migliorare le prestazioni attraverso una fusione dei messaggi. Se
arriva un messaggio "pezzo completato" da una macchina a controllo
numerico, seguito perň da un messaggio "baia di smistamento
bloccata", spesso č inutile aggiornare il database di
controllo della produzione (segnalando il completamento di un
pezzo) e poi ri-aggiornarlo subito dopo perché, di fatto, il
pezzo non č giunto a destinazione. Č piů conveniente
considerare il pezzo come non prodotto, segnalare il problema, e
lasciare alla gestione manuale (comunque necessaria) lo sblocco
della baia, il recupero del pezzo ed il suo successivo
reinserimento nella catena.
In effetti abbiamo diverse esigenze contrastanti da bilanciare: da
un lato, vorremmo che i messaggi fossero oggetti attivi, con un
loro thread di esecuzione ed una loro conoscenza interna circa i
compiti da svolgere. Dall'altro, vorremmo che fosse possibile
stabilirne il fato prima che inizino a svolgere i loro
compiti: ad esempio, la gestione di un pool di thread di cui ho
parlato nell'introduzione corrisponde ad una politica di sistema,
sovraimposta alle attivitŕ singole dei messaggi. Infine, come
avevo anticipato nella scorsa puntata, lo stesso messaggio deve
poter essere gestito in modo diverso passando da un sistema ad un
altro.
La soluzione che adotto normalmente prevede la separazione tra il
messaggio device-independent (che č una rappresentazione della
richiesta) e l'oggetto Activity che svolge i compiti associati a
tale richiesta (compiti che variano da un sistema all'altro). Tra
questi due elementi si posiziona un componente di Policy, che
decide il fato dei singoli messaggi al momento della loro
trasformazione in attivitŕ. Anche questo componente deve
essere sostituibile: ad esempio, in caso di sovraccarico in alcuni
sistemi daremo prioritŕ ai messaggi "di progresso" di un
lavoro iniziato, in altri tenderemo a privilegiare i messaggi "di
inizio attivitŕ" a scapito di quelli che stanno attendendo da
piů tempo. La scelta della politica dipende da molti fattori
al contorno e deve essere facilmente modificabile senza alterare il
resto del sistema: come ricorderete, nella mia discussione con
Stepanov [Pes97] ho accennato proprio a questa funzione di
"commodity" degli algoritmi, che non devono influenzare la
struttura ma essere semplicemente al servizio di essa.
Vediamo quindi nel dettaglio le novitŕ della figura 1.
Innanzitutto a Parser č stato associato un Thread, come
discusso nella precedente puntata. Il parser concreto crea dei
messaggi device-independent (che, lo ripeto, sono solo una
specifica della attivitŕ da compiere) e li passa ad un oggetto
Policy.
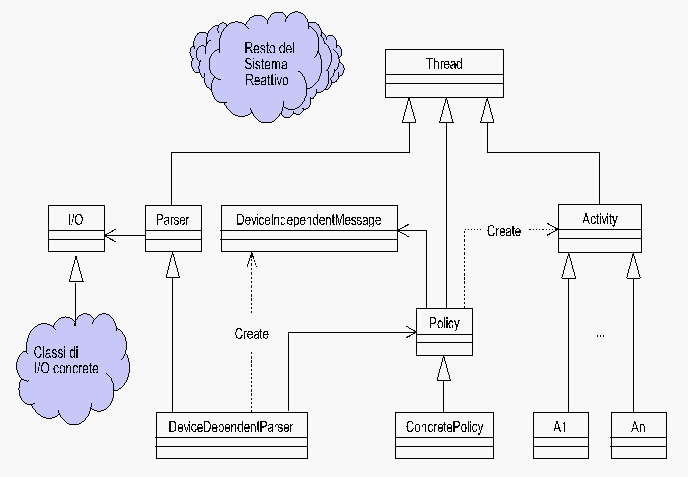
Il parser conosce solo l'interfaccia astratta Policy, e questo ci
consente di cambiare la policy concreta in ogni momento, sia
cambiando sistema che all'interno di uno stesso sistema. Nulla,
infatti, ci impedisce di cambiarla anche a run-time: anziché
prevedere un'unica politica molto complessa di gestione del
sistema, potremmo prevederne diverse, in funzione di macro-stati.
Ad esempio, potremmo avere una policy concreta allo startup, una a
regime, una in fasi di sovraccarico, una in fase di shutdown.
Questo corrisponde, in pratica, ad applicare il pattern State
[GoF95] alla classe Policy. Č anche un esempio di come gli
oggetti, le classi astratte e la conseguente sostituibilitŕ a
run-time ci permettano di mantenere sotto controllo la
complessitŕ dei sistemi, partizionando elementi monolitici in
classi separate.
Alla fine, l'oggetto Policy crea gli oggetti Activity. Osserviamo
che le decisioni prese da Policy possono essere arbitrariamente
complesse (fusione di piů messaggi, scarto di messaggi o
parcheggio in code a bassa prioritŕ, ecc), mentre il risultato
finale osservabile dall'esterno č molto semplice, ovvero viene
creato un oggetto attivo (anche Activity deriva da Thread) che
porterŕ a termine il compito richiesto.
Nuovamente, Activity č solo una classe interfaccia: questo ci
permette di soddisfare l'ulteriore requisito sui messaggi, ovvero
che la gestione di un identico messaggio device-independent possa
cambiare da un impianto ad un altro. Nel nostro caso, questo
corrisponde a dire che l'oggetto Policy creerŕ oggetti di
classe concreta diversa. Inoltre, la presenza di una classe
astratta Activity ci garantisce un ulteriore punto di
estendibilitŕ: possiamo aggiungere nuove attivitŕ
concrete semplicemente derivando una nuova classe (una volta
risolto il problema delle dipendenze di creazione, che vedremo
nella prossima puntata).
Č importante osservare che, al livello di astrazione cui ci
siamo posti, i dettagli di progettazione della singola classe
Activity concreta non vengono affrontati. Tuttavia, questo non
significa che si tratti di classi banali (tutt'altro), né che
le possibilitŕ di riuso si limitino al nostro livello
architetturale.
Un buon sistema č composto di molti strati. Progettando la
singola classe concreta Activity, dovremmo sempre pensare ad
isolare parti potenzialmente riutilizzabili (in questo caso tramite
ereditarietŕ di implementazione) in una classe derivata
dall'interfaccia Activity ma ancora specializzabile.
Il risultato finale č di ottenere un framework white-box
stabile (quello che stiamo costruendo), piů una serie di
componenti riusabili (ad es. le classi di I/O), piů una serie
di classi che potremmo chiamare semi-lavorati (es. le classi
Activity intermedie), che sono recuperabili in progetti diversi ma
che sono anche troppo specializzate per fare parte del
framework.
Se progettiamo impianti custom, noteremo che lo sviluppo
tenderŕ a produrre inizialmente un certo numero di componenti
e di semi-lavorati, ma in tempi ragionevoli ci muoveremo verso
l'integrazione di componenti giŕ sviluppati e l'estensione dei
semi-lavorati. Al resto penserŕ il framework, che ovviamente
subirŕ qualche assestamento durante l'evoluzione dei sistemi,
ma se abbiamo definito bene le interfacce delle classi astratte,
l'evoluzione difficilmente avrŕ un impatto notevole sulle
parti preesistenti.
Testability
Tra gli obiettivi che ci eravamo prefissi nella prima puntata,
non apparivano soltanto le caratteristiche di estendibilitŕ e
di adattabilitŕ di cui ho parlato poc'anzi, ma anche la
possibilitŕ di testare a fondo il sistema e di simularne il
comportamento.
Osserviamo che l'introduzione di una classe astratta per Policy ci
consente anche di sostituire delle Policy concrete con
finalitŕ di testing e di simulazione, sia al fine di
verificare il comportamento del sistema in situazioni limite, sia
per una eventuale prototipazione di un componente di Policy mirato
a problematiche specifiche.
In generale, possiamo pensare ad ogni classe astratta che
introduciamo nel sistema come ad un hot point di testing e
di simulazione. Questo č un concetto molto importante, che
puň dare un significato concreto a frasi come "design for
testability" che restano altrimenti solo dei desideri
irrealizzati.
Quando si realizza un sistema complesso (hardware o software)
č pressoché impossibile verificarne la correttezza con un
approccio totalmente black box. Il problema č ancora piů
sentito per i sistemi reattivi, il cui funzionamento dipende dal
mondo esterno (a differenza dei sistemi batch, che si prestano
meglio ad una verifica black-box). Cosě come nell'hardware si
introducono dei punti di test intermedi, in modo da poter esaminare
il funzionamento di sotto-circuiti, nel software si possono
introdurre degli hot point in cui la sostituzione di un elemento
consente di condurre un testing piů approfondito, in
modalitŕ white-box.
Possiamo applicare lo stesso ragionamento alle classi Activity.
All'interno di una classe Activity concreta possiamo facilmente
simulare una serie di situazioni particolari che sarebbe
problematico ottenere sul campo.
Fault tolerance
Ad un livello piuttosto alto come quello architetturale, le
classi interfaccia hanno anche una ulteriore valenza. Di solito
(come ho ripetuto piů volte) esse rappresentano punti di
contatto tra il framework (il cui codice č sufficientemente
stabile) e le estensioni/customizzazioni, che sono invece soggette
a modifiche frequenti, adattamenti, sostituzioni. La classe
astratta rappresenta quindi anche un confine tra due mondi, e come
spesso accade questo richiede una barriera di protezione: non
vorremmo certamente che un errore in una parte esterna al framework
possa compromettere l'integritŕ dell'intero sistema.
Il punto di contatto framework-mondo esterno č uno dei siti
migliori per posizionare un firewall contro le condizioni di
errore. In un framework ad oggetti come il nostro, probabilmente
useremo le eccezioni come metodo di propagazione degli errori. Chi
ha seguito il mio corso sull'uso delle eccezioni in C++ (vi ricordo
che una versione ridotta delle slide č disponibile liberamente
sulla mia home page) sa bene che rendere exception-safe ogni
porzione di codice č un compito difficile e gravoso. In
genere, la scelta migliore č di creare delle barriere di
propagazione controllata come parte integrante
dell'architettura.
Nel punto di contatto tra framework ed estensioni dovremmo quindi
pensare di gestire la maggior parte delle eccezioni
provenienti dai moduli esterni, e di propagare le rimanenti
(incluso il re-mapping delle eccezioni entranti) in modo
estremamente controllato.
Al limite, un errore irrecuperabile puň essere affrontato
disabilitando l'intero sottosistema (rappresentato dal modulo di
estensione e da quelli strettamente dipendenti), oltre a fornire la
necessaria diagnostica. Meglio ancora (seguendo una strategia
tipica dei sistemi di telecomunicazioni) dovremmo pensare di
adottare una tecnica di reboot selettivo dei sottosistemi in
cui si verifica un errore irrecuperabile (potete consultare [ACG96]
per ulteriori informazioni). Osserviamo quindi che isolare i moduli
tramite classi interfaccia ci aiuta anche ad ottenere un altro
degli obiettivi prefissi, l'high availability del sistema.
Performance
Ricordiamo infine che un ulteriore obiettivo del nostro sistema
erano le prestazioni soft real-time. Sicuramente qualcuno
obietterŕ che la struttura vista sopra č inefficiente
rispetto ad un agglomerato informe ma ultra-ottimizzato, dove non
esistono classi virtuali, non esiste separazione tra messaggio
device-dependent e device-independent, e tra messaggio e richiesta
attiva. Dei problemi di prestazioni mi occuperň nella prossima
(ed ultima) puntata. Posso dire sin d'ora che in molti casi un uso
accorto del polimorfismo porta a codice piů efficiente,
nonostante le tante leggende metropolitane sostengano il contrario.
Il dispatch di una funzione virtuale, con un buon compilatore C++,
ha un overhead di un paio di cicli di clock su un comune processore
Pentium. Se per evitare la funzione virtuale, rinunciando
all'estendibilitŕ, utilizziamo un if/else o uno switch/case,
rischiamo seriamente di peggiore le prestazioni anziché
migliorarle. Di questo, comunque, parlerň piů in
dettaglio nella prossima puntata.
Un argomento strettamente legato alle performance, sul quale vi
invito a riflettere prima del prossimo numero, č anche il
ruolo di DeviceIndependentMessage. Possiamo ipotizzare di renderlo
stabile, sotto forma di classe concreta, oppure pensarlo a sua
volta come classe interfaccia, da cui derivare sotto-classi
analoghe ai semi-lavorati discussi sopra: classi concrete riusabili
tra un progetto ed un altro, ma comunque troppo specializzate per
far parte del framework. Provate a pensare alle possibili
conseguenze delle due scelte.
Chiudiamo il cerchio
Riprendiamo in esame il sistema complessivo: una volta che il
messaggio č stato ricevuto, decodificato, ed infine
trasformato in un oggetto Activity, questo dovrŕ eseguire una
serie di compiti che aggiorneranno lo stato interno del sistema
e agiranno sul mondo esterno. In generale, ogni Activity
dovrŕ essere in grado di:
A rendere piů complicato il nostro compito contribuiscono
anche le problematiche di riuso. Non di rado, una Activity concreta
potrebbe essere riutilizzata su impianti diversi. Ad esempio, a
seguito di un messaggio "pezzo completato" vogliamo abitualmente
notificare il controllo produzione (che in seguito ci
informerŕ di come proseguire) ed anche dare le necessarie
disposizioni ai dispositivi "a valle". Il numero di questi
dispositivi, ed anche il comando concreto da inviare, puň
perň variare (e quasi sicuramente varierŕ) da un impianto
ad un altro.
Al solito, la soluzione piů semplice se si guarda solo
l'immediato č di scrivere delle Activity custom e di
riciclarne delle parti tramite copy&paste. Noi cercheremo
invece di prevedere queste possibilitŕ di estensione e di
adattamento all'interno della nostra architettura.
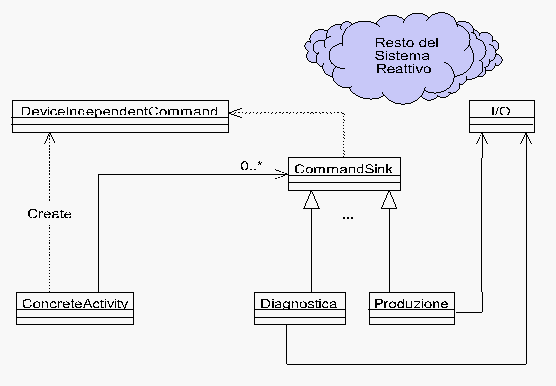
Iniziamo affrontando uno dei problemi, ovvero la comunicazione con
un numero variabile di dispositivi (si veda la figura 2; la classe
Activity concreta č qui chiamata ConcreteActivity). In
analogia a quanto realizzato per la parte di input, introduciamo
una classe DeviceIndependentCommand: gli oggetti di questa classe
rappresentano comandi astratti verso la periferia, e vengono creati
dalla ConcreteActivity ed inviati ad uno o piů CommandSink.
CommandSink č una classe interfaccia, da cui deriveremo le
varie classi concrete che si interfacciano in uscita con in vari
dispositivi: in figura 2 ho riportato come esempio una classe che
si interfaccia al PC di Diagnostica ed una che si interfaccia al
Controllo Produzione. Ognuna di esse possiede un oggetto di I/O e
svolge principalmente il compito di convertire il comando
device-independent in uno comprensibile dal dispositivo
target.
In fase di configurazione (un tema centrale per la
realizzabilitŕ di tutto il sistema, che discuterň nella
prossima puntata), decideremo quali oggetti concreti di
classe derivata da CommandSink debbano essere collegati ad ogni
ConcreteActivity. Questo ci consentirŕ di riusare la stessa
ConcreteActivity in impianti diversi, notificando dispositivi
differenti ed in numero differente, semplicemente variando le
connessioni.
Mancano ancora degli elementi, ma prima di proseguire č
necessario rivedere il risultato sinora ottenuto: come vedremo, la
soluzione ad alcuni punti ancora da coprire č giŕ
presente nel sistema, ma č necessaria una riorganizzazione di
alcune classi per farla emergere.
Clean-up
Una delle decisioni piů difficili da prendere quando si
affronta un articolo sul design di un sistema č quanto
imbrogliare i lettori. Spesso si decide di presentare
direttamente un design perfetto, argomentandone in modo logico la
nascita, e facendo sembrare naturali anche le decisioni piů
sofferte [PC86]. Si tende anche a nascondere ogni necessitŕ di
revisione del design, come se tutto fosse andato nella direzione
migliore sin dall'inizio.
Esempi simili sono comunque utili, ma tendono a proiettare una
immagine alterata del lavoro del progettista. In realtŕ, via
via che si aggiungono classi e si prendono decisioni piů
dettagliate circa il partizionamento delle responsabilitŕ,
č normale che emergano similitudini (che portano alla fusione
di piů classi), dissonanze (che portano alla separazione di
elementi o alla modifica di un tipo di relazione in un'altra) e
vere e proprie incoerenze, che richiedono interventi di maggiore
portata.
In questo caso, ho scelto di seguire una strada realistica ed
arrivare ad un punto in cui č necessario intervenire sul
risultato con una operazione di "ripulitura". Osserviamo infatti le
classi "Diagnostica" e "Produzione": esse possiedono un oggetto
I/O, che utilizzano nel verso di Output. Il loro compito č
trasformare comandi device-independent in comandi device-dependent.
A dire il vero esistono giŕ delle classi "simmetriche", che
possiedono un oggetto di I/O, lo usano nel verso di Input, e
trasformano messaggi device-dependent in messaggi
device-independent: sono i vari DeviceDependentParser.
Un qualunque dispositivo periferico č attualmente mappato su
due classi, completamente disgiunte e con nomi anche fortemente
discordanti. Ovviamente dobbiamo intervenire sul diagramma e
razionalizzarlo. Se operiamo con attenzione, potremmo anche
ottenere "gratis" i punti lasciati in sospeso al paragrafo
precedente (ad esempio l'aggiornamento dello stato del
parser).
Vi invito a spendere un po' di tempo costruendo il diagramma delle
classi completo e modificandolo in modo da ottenere una soluzione
completa ed elegante. La mia personale versione, completa come
sempre delle giustificazioni di progetto, apparirŕ sul
prossimo numero,
Conclusioni
Nella prossima puntata, oltre a completare il diagramma
lasciato in sospeso, affronteremo diversi temi di importanza
fondamentale. Stranamente, sono anche temi che troppo spesso
vengono ignorati nei vari libri ed articoli sul design. Ad esempio,
nel nostro diagramma, vi sono classi concrete (Policy) che usano e
creano classi astratte (Activity) . Ovviamente, a run-time, tutti
gli oggetti creati devono avere classe concreta. Come si supera
questo importante scoglio senza vanificare l'estendibilitŕ del
sistema? Analogamente, chi decide (e come) quali oggetti di classe
derivata da CommandSink passare ad ogni ConcreteActivity? Chi
decide quali classi concrete di I/O debbano essere create, e chi le
crea, e come? Se Policy crea gli Activity, chi li distrugge?
Riprenderemo poi alcuni argomenti appena accennati, come la
scalabilitŕ su piů macchine e l'efficienza del risultato.
Questa sarŕ anche l'occasione per accennare agli oggetti
distribuiti ed alle eventuali alternative.
Vorrei infine far notare che l'architettura che abbiamo impostato
non č l'unica possibile. Si tratta solo di una
struttura che ho utilizzato (con alcune variazioni) in diversi casi
reali, e che ho visto funzionare bene sul campo. Esistono
ovviamente approcci alternativi. Uno di questi, mirato
all'integrazione con uno strumento CASE custom e basato su idee
molto diverse, č stato ampiamente discusso in [MEM93] ed in
[AEM95]. Un altro esempio, piů simile alle idee qui presentate
e piů specializzato per problematiche di manufacturing (mentre
gran parte del nostro framework č adattabile ad altre
situazioni) č reperibile in [Sch96].
Bibliografia
[ACG96] Michael Adams, James Coplien, Robert Gamoke, Robert
Hammer, Fred Keeve, Keith Nicodemus, "Fault Tolerant
Telecommunication System Patterns", in Pattern Languages of Program
Design Vol. 2, Addison-Wesley, 1996.
[AEM95] Amund Aarsten, Gabriele Elia, Giuseppe Menga, "G++: A
Pattern Language for Computer-Integrated Manufacturing", in Pattern
Languages of Program Design Vol. 1, Addison-Wesley, 1995.
[GoF95] Gamma ed altri, "Design Patterns", Addison-Wesley,
1995.
[MEM93] Giuseppe Menga, Gabriele Elia, M. Mancia, "G++: An
Environment for Object Oriented Design and Prorotyping of
Manufacturing Systems", in Intelligent Manufacturing: Programming
Environments for CIM, Springer-Verlag, 1993.
[Mes96] Gerard Meszaros, "A Pattern Language for Improving the
Capacity of Reactive Systems", in Pattern Languages of Program
Design Vol. 2, Addison-Wesley, 1996.
[PC86] David Parnas, Paul Clements, "A Rational Design Process: How
and Why to Fake it", IEEE Transactions on Software Engineering,
February 1986.
[Pes97] Carlo Pescio, "Ipse Dixit", Computer Programming No.
64.
[Sch96] Hans Albrecht Schmid, "Creating Applications from
Components: A Manufacturing Framework Design", IEEE Software,
November 1996.
Biografia
Carlo Pescio (pescio@eptacom.net) svolge attività di consulenza, progettazione e formazione in ambito internazionale. Ha svolto la funzione di Software Architect in grandi progetti per importanti aziende europee e statunitensi. È autore di numerosi articoli su temi di ingegneria del software, programmazione C++ e tecnologia ad oggetti, apparsi sui principali periodici statunitensi, nonché dei testi "C++ Manuale di Stile" ed "UML Manuale di Stile". Laureato in Scienze dell'Informazione, è membro dell'ACM, dell'IEEE e dell'IEEE Technical Council on Software Engineering.