Architettura di Sistemi Reattivi, Parte 3
|
|
Dr. Carlo Pescio Architettura di Sistemi Reattivi, Parte 3 |
Terza ed ultima puntata sui sistemi reattivi: completiamo il modello e risolviamo gli interrogativi sinora lasciati in sospeso.
Siamo finalmente arrivati al termine della mini-serie dedicata ai sistemi reattivi. In questa puntata riprenderemo i punti lasciati in sospeso, rivedendo il diagramma delle classi e completando il modello impostato. Discuteremo anche la complessitŕ concettuale del sistema, e affronteremo i temi sinora solo accennati di efficienza, di distribuzione del carico e di configurazione. Come sempre, cercherň anche di andare al di lŕ del problema in sé e di parlare piů in generale di design ad oggetti, del ruolo del progettista, e cosě via.
Completiamo il diagramma
Al termine della scorsa puntata, come ricorderete, erano emerse
alcune disomogeneitŕ nella struttura. In particolare, ogni
dispositivo esterno era mappato su due classi distinte, ognuna
delle quali faceva poi riferimento ad un diverso oggetto di I/O,
utilizzato in un solo verso. Si poneva inoltre il problema di
aggiornare lo stato dei DeviceDependentParser all’interno di
una classe Activity concreta.
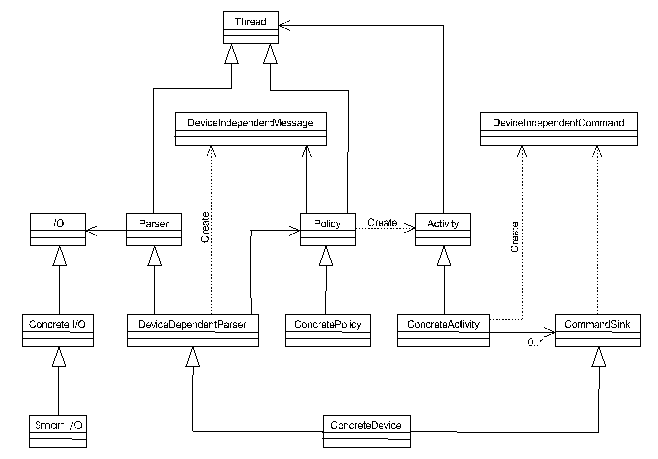
La soluzione che adotto normalmente č quella riportata in
figura 1, dove ho riassunto l’intera architettura (con
l’occasione ho anche stratificato meglio il diagramma,
cercando di riflettere i livelli di astrazione ed allo stesso tempo
di evitare incroci incomprensibili). In pratica, ho eliminato le
classi derivate da CommandSink (come Diagnostica e Produzione), che
possedevano un oggetto I/O. Al loro posto ho introdotto una classe
ConcreteDevice, che deriva da CommandSink e da
DeviceDependentParser, e che rappresenta un "intero" device, non
piů suddiviso in due unitŕ indipendenti come avveniva nel
diagramma precedente. Notiamo che ConcreteDevice č un
nome-placeholder, cosě come DeviceDependentParser: in
un diagramma reale, avremo classi come PLCSmistamento o
MainframeProduzione, cosě come dei Parser corrispondenti.
Addirittura, in diversi casi reali, risulta piů pratico
fondere insieme DeviceDependentParser e ConcreteDevice: ho lasciato
le due classi distinte perché questa č la soluzione
piů generale, che permette il massimo riuso.
La nuova struttura permette alle ConcreteActivity di parlare con il
ConcreteDevice che le ha create (tramite Policy) in modo molto
semplice: basta che il device passi se stesso, come CommandSink,
alla ConcreteActivity. Poiché il ConcreteDevice č
derivato da DeviceDependentParser, esso puň modificarne lo
stato interno, fornire feedback al dispositivo fisico (tramite la
porta di I/O del parser), e cosě via.
Notiamo che i metodi di ConcreteDevice verranno chiamati
all’interno di contesti di esecuzione diversi: questo č
il comune problema dell’approccio "classico" agli oggetti
attivi, che ho discusso a fondo in [Pes98]. Tipicamente, le letture
avverranno in un thread (Parser č un oggetto attivo), mentre
le scritture saranno invocate da un altro (normalmente una
ConcreteActivity). In pratica, questo significa che ogni
ConcreteDevice dovrŕ essere realizzato con le dovute cautele
di sincronizzazione, soprattutto nell’uso dell’oggetto
I/O.
Ho anche apportato un’ulteriore modifica (la classe Activity
ora ha-un Thread, invece di essere derivata da Thread), che
verrŕ spiegata piů avanti, al paragrafo "Efficienza".
Diagramma degli oggetti
Durante lo sviluppo di un progetto reale, non ci si limita a
produrre il solo diagramma delle classi, che come ricorderete
fornisce solo una visione statica del sistema. Č
pressoché indispensabile passare anche ad altri tipi di
diagrammi (es. sequence diagram), che forniscono una visione
dinamica. Inoltre, in alcune situazioni č utile ricorrere ad
un diagramma degli oggetti, anziché limitarsi ad un
diagramma delle classi come quelli visti sinora. Per
esigenze di spazio, non vedremo alcun diagramma di sequenza per il
sistema; i sequence diagram di UML non sono dissimili dai
"diagrammi degli eventi" da me presentati in [Pes95], peraltro
liberamente accessibile tramite la mia home page.
Credo sia invece utile vedere un esempio, ridotto all’osso,
di diagramma degli oggetti. La ragione principale č la
facilitŕ con cui la struttura statica di questo tipo di
sistemi puň ingannare chi non sia abituato a "ricostruire"
mentalmente un diagramma degli oggetti, problema che avevo giŕ
fatto notare nella prima puntata. In un diagramma degli oggetti,
ogni rettangolo rappresenta un singolo oggetto, identificato da un
nome e dalla classe. In UML, la sintassi adottata č "nome
oggetto : classe", una scelta purtroppo non molto azzeccata per chi
usa il C++, in quanto porta spesso ad una confusione con la
notazione di ereditarietŕ. Il nome dell’oggetto č
opzionale, e spesso si riporta solo per gli elementi piů
importanti del diagramma.
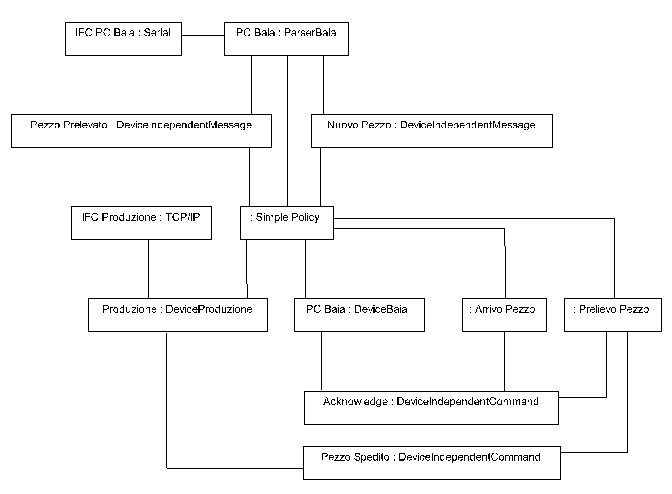
La figura 2 mostra il diagramma degli oggetti per un semplice
sistema, nel quale esistono solo due dispositivi (un PC Baia che
controlla le baie di confezionamento, collegato su porta seriale,
ed un mini Produzione che gestisce i dati di produzione, collegato
via TCP/IP). Il PC puň inviare solo due messaggi, "Nuovo
Pezzo" e "Pezzo Prelevato". La policy concreta č banale, e
crea semplicemente un oggetto Activity corrispondente al messaggio
in arrivo, senza pooling o simili. Esisteranno quindi degli oggetti
di classe ArrivoPezzo e PrelievoPezzo che svolgono le attivitŕ
richieste. In entrambi i casi č necessario mandare un comando
di Acknowledge al PC origine, e nell’esempio ho anche inviato
un messaggio "Pezzo Spedito" al mini di produzione.
Osserviamo che PC Baia appare due volte nel diagramma, una volta
come oggetto di classe ParserBaia (che sarŕ derivata da
Parser), una volta come oggetto di classe DeviceBaia (che sarŕ
a sua volta derivata da ParserBaia e da CommandSink). Questa
possibilitŕ č direttamente prevista da UML, e consente di
far vedere i diversi ruoli di un singolo oggetto all’interno
di un sistema.
Complessitŕ Concettuale
Il diagramma degli oggetti ribadisce alcuni punti
tutt’altro che evidenti in figura 1, ovvero la presenza di
piů istanze per ogni classe, e come queste istanze siano tra
loro connesse. Nel caso del nostro sistema, il diagramma di figura
2 chiarisce anche un ulteriore punto: per gestire una situazione
banale, abbiamo messo in piedi una soluzione piuttosto
complicata.
La complessitŕ concettuale della soluzione č un punto
molto importante, su cui vale la pena di spendere alcune parole.
Ovviamente, se il nostro obiettivo fosse stato la gestione del
semplice caso descritto in figura 2, la soluzione di figura 1
sarebbe stata quanto meno sovradimensionata. Tuttavia, il nostro
obiettivo era diverso, ovvero la realizzazione di un framework in
grado di operare in situazioni reali. La soluzione adottata,
che distribuisce le responsabilitŕ tra molti oggetti (ognuno
dei quali rimane quindi relativamente semplice) ha una soglia di
ingresso piuttosto alta, ma anche una scalabilitŕ
eccellente.
Aggiungere un PC di diagnostica al sistema di figura 2, ad esempio,
significa sostanzialmente implementare una nuova classe
ConcreteDevice e far sě (tramite configurazione) che le
Activity concrete notifichino anche questo elemento (visto sempre
come un CommandSink) degli eventi occorsi. Gestire nuovi eventi
significa sviluppare delle (ragionevolmente piccole) classi
Activity corrispondenti.
Le singole Activity diventano, nel nostro sistema,
l’equivalente dei Business Object in architetture
transazionali. Peraltro, in completa analogia, potremmo anche
pensare ad un loro sviluppo basato su Custom Wizard. In fondo, in
molti sistemi industriali, le Activity concrete cambiano con
relativa frequenza, e in determinate situazioni la scelta di
svilupparle in modo "usa e rimpiazza" puň anche essere quella
complessivamente migliore. Osserviamo, tra l’altro, che i
vari algoritmi concreti finiranno per essere implementati a livello
di ConcreteActivity e ConcretePolicy: essi avranno, come ho
piů volte fatto osservare, un ruolo di servizio. In effetti,
nonostante qualcuno affermi che i grandi sistemi sono algoritmici
per natura, e di conseguenza tenda a programmare a suon di
algoritmi, noi abbiamo modellato l’intera struttura relegando
sin dall’inizio gli algoritmi ad un livello di "programming
in the small", dove č giusto che stiano. Il sistema sarŕ
algoritmico nei suoi dettagli, non nella sua natura.
Tornando alla complessitŕ del sistema, va quindi osservato
come la struttura impostata, che sembra eccessiva su casi banali,
sia utile per gestire i casi reali. Ci fornisce una
collocazione naturale per ogni elemento che si verrŕ ad
aggiungere, permettendo al sistema di crescere senza
deformitŕ. Questo a differenza di soluzioni
sub-ingegnerizzate, tipiche dei sistemi nati senza un reale
progetto architetturale, che spesso non permettono una reale
scalabilitŕ e tendono frequentemente a degenerare nel
caos.
Efficienza
Le vecchie volpi dell’automazione, parzialmente convinte
da quanto sopra, passeranno probabilmente al contrattacco
affermando che la soluzione di figura 2 č inefficiente.
Impossibile dar loro torto: senza le opportune misure, per
rispondere con un acknowledge dovremmo:
In una struttura "tradizionale", con intelligenza centralizzata,
avremmo semplicemente letto il messaggio, scelto l’azione con
uno switch/case, e mandato l’acknowledge. Se vogliamo che il
nostro sistema abbia le prestazioni desiderate, dobbiamo
necessariamente aggiungere alcuni ingredienti.
Iniziamo dall’operazione sicuramente piů costosa, ovvero
la creazione e distruzione del thread che accompagna ogni Activity.
Il modo migliore per velocizzare questa operazione č... non
farla. Poco fa ho accennato alle architetture transazionali, ed
alla somiglianza tra le nostre Activity ed i Business Object. Una
delle lezioni apprese sin dai primi transaction monitor
implementati su mainframe č che la continua acquisizione (ed
il conseguente rilascio) di risorse č deleteria per le
prestazioni. Ogni sistema transazionale degno di questo nome opera
con una politica di pooling delle risorse, ed il nostro sistema
reattivo farŕ bene a seguire la stessa strategia. In pratica,
questo significa che i thread non verranno creati e
distrutti dinamicamente: verranno creati allo startup, in misura
determinata dal componente di Policy, e lasciati in stato di sleep
sino a quando si crea un oggetto Activity, cui viene assegnato il
primo thread disponibile. Questa č la ragione che mi ha
portato a modificare il legame tra Activity e Thread da
ereditarietŕ a contenimento: il contenimento permette una
riassegnazione dinamica del contenuto, l’ereditarietŕ
lega al sotto-oggetto padre per l’intera lifetime
dell’oggetto. Chi si occupa di legare un Thread ad una
Activity? Naturalmente il componente Policy, che puň usare una
eventuale conoscenza del dominio per scegliere la prioritŕ del
Thread, selezionare il miglior candidato a partire tra i
DeviceDependentMessage, eccetera. Questo coincide con il ruolo
"politico" di Policy (da cui il nome) discusso nelle puntate
precedenti. Notiamo che il pooling non č necessariamente
limitato ai thread: in funzione dell’impianto, possiamo
facilmente ipotizzare anche un pool di ConcreteActivity, magari
solo per certi tipi di attivitŕ. Sarŕ sempre il
componente di Policy a nascondere questi dettagli al resto del
sistema.
Passiamo ora ai DeviceIndependentMessage/Command. Una
caratteristica frequente di tali elementi č di avere uno
stato intrinseco che domina su quello estrinseco.
Ciň significa che, di norma, ogni oggetto
DeviceIndependentCommand che rappresenta un comando di Acknowledge
tenderŕ ad avere esattamente lo stesso stato interno. In
questi casi, si puň utilizzare il pattern FlyWeight [GoF95],
creando dei "rappresentanti" per ogni tipo di messaggio e comando,
e limitandosi a "rivestirli" con lo stato estrinseco nei pochi casi
in cui sia realmente necessario.
A questo punto, rimane fondamentalmente l’onere di un mapping
tra messaggio e activity, e l’overhead della chiamata a
funzione virtuale necessaria a scatenare le singole
ConcreteActivity. Ricordiamo che in un programma "tradizionale",
questa parte viene normalmente svolta a suon di switch/case, o con
una tavola di puntatori a funzione gestita da una ricerca binaria.
Nel nostro caso, emerge l’utilitŕ dello strato di
device-independence per i messaggi. I messaggi device-independent
che gestiscono i diversi eventi sono relativamente stabili, anche
perché il dominio del problema tende a stabilizzarsi dopo un
certo numero di impianti. In questa situazione, il mapping tra
messaggi ed activity puň facilmente essere implementato come
funzione hash perfetta [Pes96], che richiede pochi cicli di clock
per essere valutata, sicuramente meno di uno switch/case o di una
ricerca binaria. Arriviamo ora alla chiamata di funzione virtuale:
su una CPU moderna, una chiamata di funzione virtuale ha un
overhead di circa 2 cicli di clock se paragonato ad una normale
chiamata di funzione. Se poi lo paragoniamo al costo delle sue
alternative logiche (uso di puntatori a funzione o di uno
switch/case con codice in linea) ci rendiamo conto che un puntatore
a funzione ha esattamente lo stesso costo, mentre uno switch/case
č raramente piů veloce, spesso piů lento. In diverse
prove, ho osservato che sopra i 4 "case" si ha un vantaggio
notevole ad usare una funzione virtuale, tranne per alcuni "numeri
magici" (es. potenze di 2) che il compilatore ottimizza al meglio,
nel qual caso l’overhead di una funzione virtuale č
comunque di pochi cicli, ed il risparmio reale č dovuto
all’espansione delle operazioni nel corpo del case.
In conclusione, rendere efficiente l’architettura di figura 1
č sicuramente possibile, ma č necessario adottare delle
tecniche di programmazione piů sofisticate, che devono essere
tenute ben presenti in fase di design dettagliato. Un lato
decisamente positivo č che tali tecniche possono essere
nascoste in apposite classi, senza che ad esempio le singole
Activity (che sono gli elementi piů soggetti a modifiche ed
estensioni) debbano esserne a conoscenza. Nuovamente, abbiamo un
livello di complessitŕ iniziale aggiuntiva, che serve a
bilanciare la futura espandibilitŕ e maneggevolezza del
sistema.
Completiamo il sistema
Stiamo ormai tirando le fila del discorso, e possiamo quindi
completare i punti lasciati in sospeso nelle precedenti puntate.
Piů per caso che per volontŕ, un tema comune a tali
situazioni sarŕ la scelta fra una struttura completamente
strongly-typed, oppure una alternativa con un parziale controllo
dinamico sui tipi.
Iniziamo dal caso piů semplice: i vari elementi concreti sono
"collegati" fra loro solo attraverso interfacce/classi astratte.
Questo č un elemento fondamentale dell’architettura, che
ci permette di sostituire a piacimento i componenti concreti.
D’altro canto, questo significa anche che le varie classi
concrete non potranno sfruttare le particolaritŕ di altre
classi concrete: per farlo occorrerebbe modificare le interfacce, e
questo va fatto solo quando č assolutamente giustificato ed
importante (pena la ricompilazione di tutte le classi accoppiate
con l’interfaccia). Vediamo un esempio concreto: una delle
nostre classi concrete di I/O (FailSafeIO) supporta una funzione
aggiuntiva per lo switch a caldo. Purtroppo non abbiamo previsto
tale funzione nell’interfaccia I/O, quindi il nostro
ConcreteDevice non potrŕ chiamarla. Abbiamo ora due
alternative: la prima č di modificare l’interfaccia, e
dobbiamo essere pronti a pagarne il costo. La seconda č di
realizzare una nuova classe, ulteriormente derivata dal nostro
ConcreteDevice (FailSafeDevice), che "conosca" la classe del suo
oggetto di I/O. In tale classe, possiamo prendere l’oggetto
di I/O, farne un cast dinamico a FailSafeIO, e chiamare la funzione
desiderata. Ovviamente il cast puň fallire: se usiamo
FailSafeDevice con un oggetto di I/O diverso da FailSafeIO avremo
un errore a run-time, come in tutti i sistemi con controllo
dinamico dei tipi.
In tutta onestŕ, questa situazione č decisamente "sicura"
se la riconduciamo entro i limiti molto controllati descritti
sopra: due gerarchie di derivazione parallele, le cui classi foglia
usano un cast per parlarsi direttamente. Con un codice cosě
delimitato, le possibilitŕ di non riscontrare immediatamente
eventuali errori sono molto basse.
Questo č ancora piů importante quando pensiamo al secondo
caso, ovvero la condivisione di uno "stato del sistema" da parte
delle varie classi concrete. Ad esempio, il nostro sistema reattivo
potrebbe contenere un database in RAM, che deve essere manipolato
da molte Activity concrete. In generale, č difficile trovare
un’interfaccia stabile per "lo stato del sistema", che tende
a variare parecchio da un impianto all’altro.
Di nuovo le soluzioni sono fondamentalmente due, con qualche
gradazione intermedia. La prima č accettare di creare una
diversa versione del framework in ogni impianto, salvando molto
codice ma ricompilando i vari moduli perché
l’interfaccia InternalState cambia da una versione
all’altra. La seconda č di avere un’interfaccia
InternalState minimale (praticamente vuota) e nelle varie classi
concrete (che sono specifiche dell’impianto) fare un cast
dinamico alla classe ConcreteState tipica di
quell’impianto.
Una via di mezzo č l’uso di una interfaccia Broker che
consenta di interrogare lo stato del sistema con una tecnica "a
property", del tipo QueryProperty( string propertyName ). Questo
consente in una discreta percentuale di casi di evitare i cast, ma
va comunque previsto il caso di property sconosciuta.
Personalmente, non appena lo stato del sistema diventa un elemento
non banale, preferisco passare alla soluzione basata sui cast
dinamici. L’uso di un Broker con get/set porta a una pessima
distribuzione dell’iniziativa e dell’intelligenza (chi
ha letto il mio C++ Manuale di Stile o ha seguito il mio WorkLab
sul SysOOD riconoscerŕ una violazione della Legge di Demeter
nel concetto stesso di classe Broker).
Distribuzione del carico
Come avevo accennato nella prima puntata, spesso un sistema
reattivo richiede una potenza computazionale notevole, ed in molte
situazioni č piů vantaggioso utilizzare piů macchine
anziché una sola unitŕ di elaborazione molto potente.
Questo richiede un mapping degli oggetti sulle diverse macchine, ed
ovviamente richiede anche una tecnica per far "parlare" tra loro i
vari oggetti.
In queste situazioni, il criterio di partizionamento che adotto
abitualmente č il trade/off tra il bilanciamento del carico e
la minimizzazione del data flow distribuito. In parole piů
semplici, un obiettivo deve essere la distribuzione di un carico il
piů possibile uniforme sulle diverse macchine (e questo tende
a farci "sparpagliare" gli oggetti), ma un altro obiettivo deve
essere la minimizzazione del traffico di rete, sia per ragioni di
reliability che di overhead (e questo tende a farci "concentrare"
gli oggetti). In pratica, una strategia molto semplice che tende a
funzionare bene č la separazione tra I/O e Processing, seguita
eventualmente da un partizionamento delle diverse Activity. Vediamo
un caso concreto: le interfacce seriali sono lente e tendono a
"rubare" parecchio tempo di CPU se confrontate con una rete.
Spostare su un’unica macchina la gestione di un buon numero
di porte seriali, facendo vedere alle macchine di Processing solo
una o piů schede di rete, č un’ottima (e semplice)
tecnica di distribuzione del carico. Analogamente, se il nostro
sistema richiede un alto numero di Activity, č ragionevole
partizionarle su piů macchine, seguendo anche in questo caso
la tecnica di minimizzazione del data-flow distribuito.
Definito il partizionamento, occorre individuare una tecnica per
distribuire gli oggetti. Fondamentalmente abbiamo due scelte: una
distribuzione "manuale" o l’uso di un middleware, ad es.
CORBA o DCOM. Distribuzione "manuale" significa sostanzialmente
scrivere un oggetto Proxy che gira sulla macchina locale, scrivere
un oggetto Stub che gira sulla macchina remota, e far parlare i due
attraverso qualche protocollo, normalmente sfruttando una delle
primitive di comunicazione del sistema target (socket, pipe,
NetBIOS, ecc). Si tratta di una soluzione ampiamente adottata,
tanto da essere classificata come pattern ("Half Object +
Protocol", [Mes95]). Ha l’innegabile vantaggio di permettere
il totale controllo, caratteristica che si rivela molto importante
in fase di testing e messa in opera, e l’innegabile
svantaggio di richiedere la scrittura (ed il test) di due classi
aggiuntive per ogni classe distribuita.
L’uso di un middleware ha vantaggi e svantaggi esattamente
opposti, ovvero otteniamo piů o meno gratuitamente la
creazione dei proxy/stub, normalmente al solo costo di definire
l’interfaccia in un IDL, e poi dobbiamo compiere un "salto
nella fede" e sperare che le chiamate di funzione... funzionino.
Non di rado, se qualcosa va storto diventa un po’ difficile
scoprire l’origine esatta del problema e porvi rimedio.
Come dico spesso in questi casi, dal mio punto di vista č un
caso di gap generazionale: spesso incontro neolaureati cui brillano
gli occhi a parlare di CORBA, mentre a chi ha un po’ piů
di esperienza su casi reali calano gocce di sudore pensando ai
grattacapi di testing, debugging ed assistenza remota.
Personalmente, per almeno un altro paio di anni, credo che
continuerň a puntare su soluzioni che mi garantiscono il
controllo che desidero, anche a costo di dover scrivere un
po’ piů di codice (spesso peraltro molto
semplice).
Infine, vorrei ricordare che la gestione "manuale" consente anche
di ottimizzare ulteriormente il sistema, ad esempio accorpando in
un unico invio su rete piů messaggi provenienti da dispositivi
diversi, in funzione di un sistema a prioritŕ e dimensione dei
pacchetti studiato a puntino.
Configurazione e Creazione
L’ultimo, importante punto lasciato in sospeso riguarda
la configurazione del sistema, ed in particolare la gestione delle
dipendenze di creazione. Come avevo accennato nella scorsa puntata,
il diagramma di figura 1 "non funziona", ovvero non puň essere
direttamente implementato cosě com’é. Questo č
peraltro un rischio sempre presente a livello di progettazione, ed
č una delle ragioni per cui, a mio avviso, i progettisti
dovrebbero sempre avere una reale esperienza di programmazione alle
spalle, e dovrebbero cercare di mantenerla sempre viva: aiuta a
capire piů rapidamente eventuali "buchi" nei diagrammi.
In particolare, i nostri problemi sono i seguenti:
Chi ha seguito il mio corso o worklab sul Systematic OOD
riconoscerŕ immediatamente una serie di dipendenze di
creazione che devono essere gestite. Le tecniche possibili sono
diverse, in funzione del grado di flessibilitŕ desiderato. In
particolare, dobbiamo decidere se una variazione nelle associazioni
discusse sopra č passibile di ricompilazione, o se deve essere
possibile riconfigurare il sistema senza mettere mano al
codice.
In impianti di controllo industriale, va detto che l’ipotesi
di ricompilazione non č cosě disastrosa, purché
venga confinata a moduli molto delimitati (per evitare di dover
ri-testare a fondo moduli complessi). In fondo, se per associare un
DeviceDependentParser ad un I/O su TCP/IP anziché su seriale
dobbiamo modificare una linea e ricompilare un piccolo
modulo-factory, il costo č quasi trascurabile rispetto alle
operazioni da compiere sui dispositivi fisici per cambiare le
schede, stendere i cavi, eccetera.
In queste situazioni, l’opzione migliore resta quella della
Class Factory [GoF95], ovvero una classe particolare che conosce la
topologia dell’impianto ed č in grado di creare gli
oggetti di classe "giusta" per ogni elemento visto sopra (tranne il
punto 3 che vedremo tra poco).
In situazioni particolarmente dinamiche, o quando si prevede di
installare molti impianti diversi e si vuole evitare
l’inferno delle versioni multiple, puň essere opportuno
usare una strategia differente. La tecnica che uso abitualmente
č di isolare ogni classe concreta in una DLL, che esporta
delle funzioni di creazione e distruzione degli oggetti. Gli
oggetti vengono esposti come puntatori alle classi base, anche se
internamente alla DLL vengono creati come oggetti di classe
derivata.
A questo punto č sufficiente che ogni elemento conosca il nome
della DLL che implementa gli oggetti associati (nel SysOOD, questa
tecnica č chiamata Indexed Creation): ad esempio, per quanto
riguarda il punto 1 ogni DeviceDependentParser dovrŕ conoscere
il nome della DLL che implementa la classe di I/O associata, ed i
parametri di configurazione. Per quanto riguarda il punto 3, di
solito una tecnica di Indexed Creation č praticamente
indispensabile, in quanto si tratta di una associazione dinamica e
soggetta a frequenti cambiamenti. Possiamo ipotizzare di
memorizzare proprio questa associazione nella tavola hash discussa
al paragrafo "Efficienza".
I dati di configurazione possono essere facilmente memorizzati in
un file "a sezioni" (stile .INI), in un database, o in uno script.
Avendo provato le tre soluzioni, mi sento di affermare che (salvo
situazioni particolari) il file INI funziona al meglio, seguito
dallo script in alcune circostanze, ed a larga distanza dal
database, che mal si presta a gestire i vari parametri custom
associati ad ogni elemento.
In fase di installazione, talvolta č anche ipotizzabile la
scrittura manuale di un file di configurazione. In fondo, in alcuni
impianti non troppo complessi ci si trova di fronte a
trenta-cinquanta oggetti da configurare, una quantitŕ
facilmente gestibile con un editor. In altri casi, tuttavia, č
necessario dedicare la giusta attenzione ad un programma di
configurazione.
Ad esempio, alcuni anni fa ho progettato ed in gran parte
implementato una piattaforma aperta per l’acquisizione,
l’analisi in tempo reale e la rappresentazione di dati
fisiologici. In quel caso, il numero di oggetti da connettere e
configurare era tipicamente esiguo, ma volevamo che il processo
fosse svolto con facilitŕ dall’utente finale. Solo
attraverso una GUI decisamente sofisticata abbiamo ottenuto il
risultato voluto.
Altre volte č il numero degli oggetti a sconsigliare una
gestione manuale. Scrivo queste note proprio dopo alcuni giorni
passati presso un’azienda, durante i quali abbiamo progettato
l’architettura di un concentratore di terminali di pagamento.
Credo non vi sorprenderŕ troppo sapere che la struttura emersa
ha diversi punti in comune con quella di figura 2, anche se la
differente natura del sistema ha portato anche ad importanti
scostamenti, che riflettono un diverso dominio del problema.
Tuttavia, le problematiche di configurazione erano del tutto
analoghe a quelle viste poco sopra. Da una sommaria analisi
quantitativa, abbiamo visto che in un sistema piuttosto "carico"
gli oggetti da configurare erano circa 1600, e si richiederŕ
indubbiamente una interfaccia ben studiata per rendere
ragionevolmente semplice (e ragionevolmente veloce) l’intero
processo di configurazione del sistema.
Conclusioni
In queste tre puntate abbiamo affrontato un problema non
banale, arrivando ad una architettura in grado di accomodare
esigenze diverse ed in parte anche contrastanti. Strada facendo
abbiamo dovuto prendere molte decisioni, che hanno condizionato non
poco la struttura finale. Prendere simili decisioni non č
facile, ed č il ruolo principale di un software architect, che
deve essere in grado di prevedere le conseguenze a lunga distanza
delle sue scelte. Naturalmente, in questi casi, l’esperienza
diretta č insostituibile. Possiamo perň imparare molto
anche dalle esperienze altrui. A chi voglia approfondire i temi di
progettazione di framework applicativi, posso sicuramente
consigliare l’intero numero di Ottobre 97 di Communications
of ACM, che riporta parecchi articoli interessanti. Sempre
meritevoli di una lettura sono anche i vari experience report e
case study reperibili in letteratura ([Bir93], [HRE95], [BKGZ96]),
senza dimenticare [Par76] che č a mio avviso l’archetipo
(stranamente ignorato da molti progettisti) dell’idea stessa
di framework applicativo.
Bibliografia
[Bir93] E. T. Birrer, "Frameworks in the financial engineering
domain", Proceedings of ECOOP ’93, Springer-Verlag.
[BKGZ96] D. Baumer, R. Knoll, G. Gryczan, H. Zullighoven,
"Large-scale object oriented software development in a banking
environment", Proceedings of ECOOP ’96,
Springer-Verlag.
[GoF95] Gamma ed altri, "Design Patterns", Addison-Wesley,
1995.
[HRE95] H. Hueni, R. Johnson, R. A. Engel, "A framework for network
protocol software", Proceedings of OOPSLA ’95, ACM
Press.
[Mes95] Gerard Meszaros, "Pattern: Half-object + Protocol", in
Coplien, Schmidt, "Pattern Languages of Program Design",
Addison-Wesley, 1995.
[Par76] D. L. Parnas, "On the Design and Development of Program
Families", IEEE Transactions on Software Engineering, March
1976.
[Pes95] Carlo Pescio, "Design: Dominio del Problema e della
Soluzione", Computer Programming No. 41.
[Pes96] Carlo Pescio, "Minimal Perfect Hashing", Dr. Dobb's
Journal, No. 249, July 1996.
[Pes98] Carlo Pescio, "Oggetti e Thread", Computer Programming No.
65.
Biografia
Carlo Pescio (pescio@eptacom.net) svolge attività di consulenza, progettazione e formazione in ambito internazionale. Ha svolto la funzione di Software Architect in grandi progetti per importanti aziende europee e statunitensi. È autore di numerosi articoli su temi di ingegneria del software, programmazione C++ e tecnologia ad oggetti, apparsi sui principali periodici statunitensi, nonché dei testi "C++ Manuale di Stile" ed "UML Manuale di Stile". Laureato in Scienze dell'Informazione, è membro dell'ACM, dell'IEEE e dell'IEEE Technical Council on Software Engineering.