Architettura di Sistemi Record-Oriented, Parte 1
|
|
Dr. Carlo Pescio Architettura di Sistemi Record-Oriented, Parte 1 |
Pubblicato su Computer Programming No. 78
Non basta nascondere i data member dietro l’interfaccia pubblica di una classe per ottenere un sistema ad oggetti. In questa serie di puntate prenderò in considerazione una categoria di sistemi (record-oriented) e ne discuterò alcune alternative architetturali, soprattutto in termini di estendibilità e manutenibilità.
Alcuni mesi fa ho dedicato tre puntate di "Principles&Techniques" alla discussione di una architettura che ho utilizzato con successo in molteplici situazioni per una ampia famiglia di sistemi, detti sistemi reattivi [Pes98a-c].
Molti lettori hanno apprezzato il trittico, ma non sono mancate alcune email critiche, a dire il vero non riguardo la soluzione presentata, ma riguardo l’intero paradigma ad oggetti. Tra queste, la maggior parte proveniva da programmatori impegnati in progetti di tipo business, o più in generale record-oriented. Molti sostenevano che, nel loro specifico settore, gli oggetti si comportano decisamente male, non mantenendo le solite promesse di estendibilità e riusabilità di cui spesso abbiamo parlato.
Ho quindi deciso di dedicare alcune puntate alla discussione, a livello architetturale, di un approccio alternativo alle soluzioni più diffuse nei sistemi record-oriented. Un approccio che trae reali benefici dagli oggetti e che ho usato con successo in diversi progetti, e ritrovato in alcuni dei suoi aspetti in altri ancora, quando il team di sviluppatori non era cascato nella trappola dello sviluppo rapido a spese della manutenzione, dell’estendibilità e del riuso.
Sistemi Record-Oriented
Con sistema record-oriented intenderò in queste puntate un sistema la cui funzione dominante sia di front-end, più o meno sofisticato, verso un database relazionale. Funzionalità tipiche di questa categoria di sistemi sono la visualizzazione (in forme diverse) del risultato di una query, o del dettaglio di un record, o la produzione di report, ma anche funzionalità di data entry, esportazione ed importazione di dati, e così via. Come nel caso dei sistemi reattivi, si tratta di una famiglia molto ampia, che ritroviamo nei settori più disparati dell’industria, dell’amministrazione pubblica, dei servizi, eccetera.
Recentemente è stato pubblicato un articolo molto interessante di Søren Lauesen [Lau98], in cui l’autore riporta la stessa opinione di fondo dei lettori di cui sopra (gli oggetti "non funzionano" nel settore business), giustificandola con un buon numero di case study, peraltro disponibili on-line (http://www.cbs.dk/~slauesen/OOcaseStudies/). Uno dei lati più interessanti dei succitati case study è proprio l’opinione dei vari progettisti, che spesso ritenevano di aver costruito un buon sistema orientato agli oggetti, almeno sino a quando i risultati non venivano valutati con atteggiamento critico da Lauesen.
Ed in effetti, le soluzioni prese in esame da Lauesen, così come quelle accennate dai lettori e così come quelle che spesso ritrovo su libri, articoli ed in molti progetti reali non sono "ad oggetti". Ovvero, non traggono significativi benefici dall’OOP, se confrontati ad esempio con i risultati ottenibili con i tradizionali sistemi strutturati. A riprova che non basta "incapsulare" qualche dato all’interno di una classe per realizzare un sistema "ad oggetti".
Esistono infatti alcune soluzioni "dominanti", nel senso di diffusione oggettiva delle implementazioni basate su di esse. In alcuni casi, queste soluzioni si comportano bene, e non è necessario cercare alternative più sofisticate. Uno degli obiettivi di questa breve serie è prendere in esame anche queste soluzioni più tradizionali e capire quando sono sufficienti, quali sono i loro vantaggi e quali i loro problemi. Lauesen identifica tre soluzioni classiche, che chiama rispettivamente "semplice", "complessa" e "tecnica". In effetti, al di là del nome non proprio chiaro, queste corrispondono alle architetture che più comunemente ho avuto modo di incontrare, sia nei testi che nei progetti reali. In questa prima puntata riprenderò le soluzioni classiche, cercando di evidenziarne anche i lati positivi, e darò qualche indicazione su come una soluzione migliore possa essere costruita. Nelle prossime scenderò nei dettagli di questa architettura alternativa. I lettori impazienti, che preferiscano vedere sin da subito il diagramma delle classi finale e magari pensarci un po’ su, possono richiederlo sin d’ora via email (come GIF, circa 25Kb).
L’architettura "semplice"
Iniziamo dalla soluzione forse più tradizionale e diffusa; così diffusa che molti ritengono sia la via canonica per implementare "ad oggetti" una applicazione record-oriented. La figura 1 identifica gli elementi principali: un insieme di tabelle su un DB relazionale; un insieme di classi, ognuna delle quali "oggettifica" una tabella; un insieme di classi GUI che permettono di visualizzare e modificare il contenuto delle tabelle.
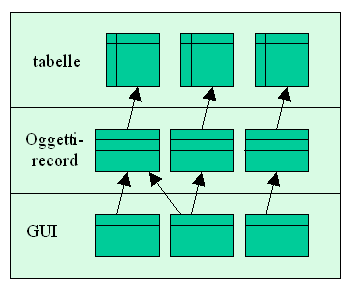
La soluzione "semplice" non impone alcuna regola circa la localizzazione del codice relativo, ad esempio, alla verifica dei vincoli o alla computazione dei campi calcolati. Potrebbe trovarsi nello strato intermedio o (come spesso accade, e come molti programmatori RAD tendono purtroppo a fare) nel livello GUI.
Tra i pregi della soluzione troviamo indubbiamente la semplicità. L’architettura è così banale che in buona parte può essere costruita in modo automatico da uno strumento (o da un insieme di Wizard), partendo dalle tabelle sottostanti. Viene però da chiedersi quali siano i vantaggi di questa soluzione rispetto ad una senza oggetti nello strato intermedio. Questi oggetti (almeno così spesso si dice) dovrebbero "incapsulare" le tabelle; tuttavia non è affatto chiaro cosa significhi, e quali vantaggi comporti.
Ricordiamo infatti che l’incapsulazione è solo una tecnica per realizzare l’information hiding, ovvero l’occultamento dietro una interfaccia resiliente delle caratteristiche soggette a cambiamenti. Proviamo quindi a considerare alcune possibili varianti che potranno emergere durante la vita del sistema, e vediamo quanto la soluzione "semplice" ne limita l’impatto sul codice risultante.
Se viene richiesta una modifica a livello di presentazione, possiamo mantenere inalterati i livelli sottostanti. Questo è un primo risultato positivo, ma non va certamente attribuito agli oggetti. Inoltre, se cambia il significato bit-wise di uno dei campi (ma non il suo tipo) potremmo essere in grado di isolare la variazione nello strato intermedio. Pensiamo al classico problema "anno 2000". Lo strato intermedio potrebbe implementare una qualunque tecnica per estendere il range delle date, senza modifiche alla sua interfaccia pubblica (verso la parte GUI, o di reporting, o di esportazione, ecc). Anche questo è un risultato positivo, che non avremmo se la parte GUI si interfacciasse direttamente sulle tabelle. Ma nuovamente, delle semplici funzioni intermedie ci darebbero in larga misura gli stessi risultati.
Se cambiano le cosiddette business rule, ovvero i vari criteri che comprendono, ad esempio, i vincoli di validità dei campi o le formule dei campi calcolati, potremmo riuscire a limitare l’impatto allo strato intermedio (se si trovano lì localizzate), senza impatto sulla GUI. Questo è un po’ il fondamento delle architetture three-tiered tanto di moda sino a poco tempo fa, giusto ora un po’ in declino. Da notare che potremmo anche non riuscirci, perché nell’architettura "semplice" abbiamo una classe per tabella, e molto spesso le regole sono cross-table. In questi casi, nell’architettura semplice le verifiche vengono spesso realizzate dallo strato GUI.
Vediamo ora qualche situazione meno rosea (ma non meno probabile). Se cambiamo la struttura di una tabella (aggiungiamo un campo, o togliamo un campo) dobbiamo modificare il database, lo strato intermedio e la GUI. Non vi è nulla nella soluzione semplice che sia progettato per assorbire l’impatto di queste modifiche. Analogamente, se cambiamo il tipo di un campo, ad esempio un campo "importo" che da intero (per le lire) diventa in virgola fissa (per l’euro), o un campo codice che da numerico diventa alfanumerico, dobbiamo cambiare il database, lo strato intermedio e lo strato GUI (che dipende dall’interfaccia instabile dello strato intermedio).
Quanto sono probabili questi scenari negativi? Purtroppo sono estremamente probabili. Per quanto il sogno dell’approccio data-modeling sia di ottenere un modello molto stabile dei dati, e di lasciare l’instabilità nel processing di tali dati, in pratica il dominio tende a cambiare anche a livello degli attributi di ogni entità.
La soluzione "semplice" ha anche altri problemi, di natura più tecnologica, che vengono affrontati dalla soluzione "complessa", che tuttavia lascia comunque scoperti i punti deboli di cui sopra.
L’architettura "complessa"
Il secondo schema architetturale (figura 2) cerca di risolvere due problemi ulteriori: la separazione della GUI dalle operazioni cross-table, e la coerenza tra viste multiple sullo stesso insieme di dati.
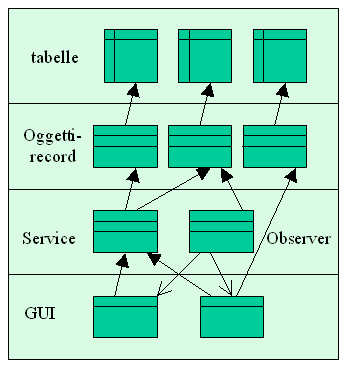
Notiamo infatti la presenza di "service object" che hanno il ruolo di coordinare le operazioni su tabelle multiple: ad esempio, un oggetto "acquisto" potrebbe modificare una tabella degli ordini, una dei prodotti a magazzino, una della posizione del cliente, ecc. Questi oggetti "di servizio" sono molto vicini ai business object introdotti dalla prossima soluzione; la differenza principale è che in questo caso, ci troviamo molto spesso di fronte ad oggetti degeneri, privi di stato ed operanti in pratica solo sui propri parametri.
L’altro ingrediente essenziale della soluzione "complessa" è l’observer (si veda il pattern omonimo in [GoF94]), che ha il ruolo di mantenere coerenti eventuali viste multiple sui dati. In realtà il problema dell’observer è molto più grande di quanto possa apparire a prima vista, soprattutto a chi è abituato ad una soluzione analoga, in applicazioni record-oriented, basata sul modello document/view di MFC.
In MFC, è prassi comune mettere il recordset nel documento, garantirsi che ogni vista acceda al recordset solo in momenti molto controllati (pena avanzamenti random del cursore), quindi tipicamente con viste multiple modali o single-record, e usare il meccanismo built-in del document-view per ottenere una coerenza tra le diverse viste.
Nell’architettura di figura due ogni elemento GUI usa le classi intermedie in modo autonomo, senza dover fare riferimento ad un documento comune e quindi senza avere particolari restrizioni sugli accessi (che peraltro renderebbero molto problematiche delle vere implementazioni multi-thread). In questa situazione, è necessario che ogni classe intermedia cooperi per mantenere coerenti le viste sui propri record. Ciò può essere realizzato in diversi modi, ad esempio tenendo traccia delle istanze attive in modo da rilasciare lo stesso oggetto se viene richiesto lo stesso record.
Tuttavia, le cose si complicano parecchio quando intervengono query complesse, che coinvolgono più tabelle. Nell’approccio "MFC" (che chiamo così più che altro perché l’ho osservato con molta frequenza in tale ambiente), avremmo oggetti intermedi per l’intera query. Se due query hanno campi in comune sulle tabelle, può facilmente succedere che uno dei record venga modificato tramite una vista su una query e le viste sull’altra non vengano aggiornate di conseguenza, essendo basate su un altro recordset anche se con campi in comune.
Per contro, nel modello di figura due il join all’interno della query va realizzato a livello applicativo, perché gli oggetti intermedi sono associati ad una sola tabella. Mantenere funzionante l’idea dell’observer ed evitare il join manuale richiede un livello di complessità ulteriore, che discuterò più avanti come parte della soluzione "alternativa" proposta.
Vediamo invece i vantaggi dell’architettura complessa. Fondamentalmente, ha il pregio più volte citato di incapsulare alcune operazioni cross-table (assorbendo quindi l’impatto di alcuni spostamenti di campo e/o alcune modifiche alle relazioni sul database) e di consentire di aggiungere/rimuovere viste sul database con semplicità grazie all’observer. Rimangono invariati i problemi di manutenzione a fronte di aggiunte/rimozione di campi e di modifiche ai tipi di dato associati.
La soluzione "tecnica"
Sotto questo nome un po’ inusuale utilizzato da Lauesen si nasconde un’altra architettura piuttosto nota, basata su domain object o business object che dir si voglia. L’idea di fondo non è molto diversa da quella della "soluzione complessa", e ciò che cambia è principalmente il punto di vista con cui realizziamo lo strato intermedio. Infatti, se in figura 2 abbiamo lo strato GUI che accede agli oggetti intermedi (che a loro volta accedono al DB), ed eventualmente fa uso di oggetti di servizio per operazioni cross-table, in una soluzione a business object gli oggetti intermedi e quelli di servizio vengono fusi e "nobilitati". Ovvero, vengono impostati come veri e propri oggetti (fornitori di servizi) e non come degli ammassi di Get/Set o come oggetti degeneri come accade nelle soluzioni precedenti. I servizi da esporre (in teoria) vanno ricercati ad un livello di astrazione sufficientemente alto da risultare relativamente indipendenti dalla struttura del database sottostante.
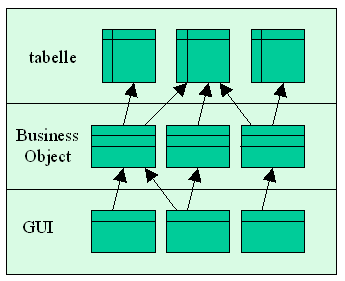
Vediamo un semplice esempio: un business object "Cliente" potrebbe avere tra i suoi servizi "Calcola sconto"; la procedura relativa può essere semplice (in base ad una tipologia) o complessa a piacere (in base al totale ordinato nell’anno precedente, indicizzato in una tabella, ecc). Il servizio resta comunque stabile, nella sua interfaccia, indipendentemente dalla politica di calcolo e dalle navigazioni necessarie sulla struttura del database sottostante. Lo stesso avviene a fronte di riorganizzazioni nella struttura delle tabelle (ad es. a seguito di normalizzazioni o denormalizzazioni), purché l’informazione rimanga la stessa al di là della provenienza dei vari campi.
Ovviamente la differenza a livello implementativo tra la soluzione "tecnica" e quella "semplice" o "complessa" non è molto significativa: come dicevo, cambia più che altro l’ottica di progettazione dei singoli oggetti. Lo sforzo di identificare i servizi stabili può ampiamente ripagare in termini di stabilità nell’interfaccia del business object, o per meglio dire, di parte di essa.
Resta infatti invariato il problema del link alla GUI. Anche se il business object incorpora parti di logica che in altre situazioni sarebbero state inserite nella GUI (es. i campi calcolati, la validazione dei campi, ecc), non può fare molto contro modifiche al numero di campi da visualizzare, che nella visione "tradizionale" richiedono una modifica alla sua interfaccia.
Rimane anche il problema delle modifiche cross-table: un business object può modificare tabelle che vengono usate anche da altri business object, e si rende quindi indispensabile una gestione complessa degli aggiornamenti. Questa gestione può essere semplificata scrivendo ogni volta un codice custom (che conosce le tabelle sottostanti ai diversi business object), ma questo significa inficiare il livello di information hiding raggiunto. Anche l’approccio a business object, che in qualche modo è l’unico minimamente "object oriented" tra quelli visti sinora, e che è spesso proposto come soluzione vincente, soffre quindi di una carenza di stabilità molto forte.
Verso una soluzione
Non a caso al punto precedente ho parlato di una "visione tradizionale". L’errore di fondo di questa visione sta proprio nel creare degli oggetti inerentemente instabili: se, come avviene in pratica, il numero ed il tipo dei campi tende a variare, allora una qualunque interfaccia che abbia dei metodi di accesso per ogni campo non realizzerà il nostro obiettivo di information hiding. In termini di Systematic Object Oriented Design [Pes99], questo è uno dei casi in cui violare la legge di Demeter ([LH93], [Pes95]) è decisamente non accettabile.
Il primo punto da risolvere diventa ora la ricerca di alcuni elementi stabili nel problema: in mancanza di qualunque stabilità, non possiamo trovare interfacce resilienti. Ora, secondo la mia esperienza e quella di molti altri, uno degli elementi decisamente più stabili nelle applicazioni record-oriented è l’insieme dei tipi utilizzabili per i singoli campi. Molto spesso questi si riducono ai pochi tipi supportati in modo nativo dalla maggior parte dei DB relazionali, ad es. interi, stringhe, date, ecc. Sicuramente vi saranno casi in cui l’insieme dei tipi primitivi viene esteso (ad es. per supportare campi "sonori"), ma si tratta di un evento di gran lunga più raro rispetto, ad esempio, all’aggiunta di un campo ad una tabella.
Come sfruttare questa stabilità? Il primo passo è costruirvi intorno una architettura basata sul concetto di reflection [Bus96] (termine che i programmatori Java conoscono come introspection), ovvero sulla capacità di un oggetto di descrivere la propria struttura. Un fattore interessante è che i database relazionali, nonché le principali interfacce standard verso i database (come ODBC), forniscono in modo nativo questo tipo di supporto.
Possiamo quindi pensare ad un RecordSet in grado di enumerare i propri elementi (Record), e ad un Record in grado di enumerare i propri elementi (Field). Siccome abbiamo un numero limitato (e ragionevolmente stabile) di tipi primitivi per i Field, possiamo costruire su di essi dei meccanismi estendibili di presentazione, di validazione, di calcolo, eccetera. Notiamo infatti che il numero di tipi è stabile, ma le formattazioni e le regole di validità non lo sono affatto.
L’idea di passare a meta-livello si applica anche ad altre situazioni: ad esempio, un meccanismo di sincronizzazione delle viste potrebbe facilmente analizzare i campi dei vari RecordSet e capire quando due RecordSet hanno in comune alcuni campi provenienti dalla stessa tabella. Analogamente, un insieme molto grande di regole di validazione può essere supportato con un interprete molto semplice di espressioni (simile a quello di uno spreadsheet), spostando nuovamente una buona parte di variabilità fuori dal codice (e dentro ad uno script, che non richiede ricompilazioni di sorta). La solita legge di Pareto, che possiamo sfruttare a nostro favore.
Naturalmente non è tutto così semplice: esisteranno ad esempio regole troppo complesse per essere valutate da un semplice linguaggio di script, e non sempre potenziare il linguaggio sarà la risposta più efficace. Una buona soluzione deve permettere al programmatore di scegliere tra regole scripted e regole hard-coded, in base alla propria percezione della difficoltà e della stabilità. Anche il livello di sincronizzazione tra viste può essere reso più o meno efficiente, in base allo sforzo che vogliamo spendere nella sua realizzazione.
Conclusioni
Uno dei miei obiettivi, durante la stesura di un articolo, è di comunicare qualcosa che ritengo interessante; un altro obiettivo, a mio avviso altrettanto importante, è di stimolare chi legge a pensare e a progettare per conto proprio. Invito quindi chiunque sia interessato all’argomento a riprendere i suggerimenti dell’ultimo paragrafo ed a stendere una propria soluzione. Rinnovo l’invito a chiunque voglia esaminare sin d’ora il diagramma delle classi che discuterò nelle prossime puntate a richiederlo via email. E come sempre, se avete qualche commento, idea o proposta sull’argomento, non esitate a farvi sentire.
Biografia
Carlo Pescio svolge attivitŕ di consulenza e formazione in ambito internazionale nel
campo delle tecnologie Object Oriented. Ha svolto la funzione di Software Architect in
grandi progetti per importanti aziende europee e statunitensi. Č l’ideatore del metodo
di design ad oggetti SysOOD (Systematic Object Oriented Design), ed autore di numerosi
articoli su temi di ingegneria del software, programmazione C++ e tecnologia ad oggetti,
apparsi sui principali periodici statunitensi. Laureato in Scienze dell’Informazione,
č membro dell’ACM e dell’IEEE.
Bibliografia
[Bus96] Frank Buschmann ed altri, "Pattern-Oriented Software Architecture", John Wiley & Sons, 1996.
[GoF94] Gamma ed altri, "Design Patterns", Addison-Wesley, 1994.
[Lau98] Søren Lauesen, "Real-Life Object-Oriented Systems", IEEE Software, March-April 1998.
[LH93] Karl Lieberherr, Ian Holland, "Assuring Good Style for Object-Oriented Programs", Technical Report, Northeastern University, 1993.
[Pes95] Carlo Pescio, "C++ Manuale di Stile", Edizioni Infomedia, 1995.
[Pes98a-c] Carlo Pescio, "Architettura di Sistemi Reattivi", Computer Programming No. 68,69,70.
[Pes99] Carlo Pescio, "Systematic Object Oriented Design", Computer Programming No. 76.