Architettura di Sistemi Record-Oriented, Parte 2
|
|
Dr. Carlo Pescio Architettura di Sistemi Record-Oriented, Parte 2 |
Iniziamo a delineare la nuova architettura, analizzando sia lĺaccesso ai dati basato sullĺidea di reflection, sia il livello di presentazione, anche questo pensato per rendere il sistema immune dai problemi di manutenzione tipici delle soluzioni tradizionali.
Nello scorso numero abbiamo visto come le architetture pi¨
tradizionali per i sistemi record-oriented vadano facilmente
incontro ad alcuni problemi di manutenzione, legati ad esempio agli
eventi (piuttosto frequenti) di aggiunta o rimozione di campi dalle
tabelle relazionali. Ho anche accennato ad una possibile via di
uscita, basata sul concetto di reflection, ovvero sulla
capacitÓ di alcuni oggetti di "spiegare" al resto del sistema
la loro struttura interna.
In questa puntata vedremo come costruire intorno a tale idea una
architettura diversa da quelle pi¨ tradizionali, che risolve
molti dei problemi sollevati nella puntata precedente.
Dal recordset al campo
Il recordset rappresenta il punto di ingresso per le parti
applicative. Un recordset Ŕ il risultato di una query, ad
esempio di uno statement SQL del tipo SELECT <...> FROM
<...> WHERE <...>. Un recordset Ŕ composto da un
certo numero di record, ognuno dei quali Ŕ composto da un
certo numero di campi. Ogni campo ha un valore di un certo tipo
(intero, stringa, data/ora, ecc.). Il nostro primo obiettivo
Ŕ strutturare questi semplici concetti in una gerarchia di
classi che sia estendibile e che non ci richieda variazioni sul
lato applicativo se modifichiamo la struttura di una o pi¨
tabelle, o se cambiamo il motore di database. Per contro, il codice
applicativo deve poter navigare il recordset ed estrarre
informazioni sui singoli campi. Su questa gerarchia costruiremo poi
il resto del framework.
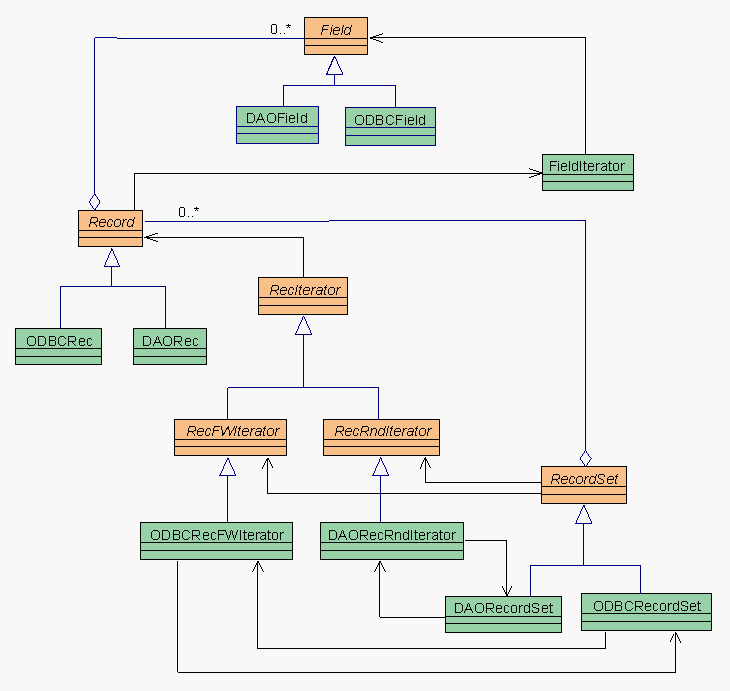
Una possibile soluzione Ŕ data in figura 1: la notazione
utilizzata Ŕ UML, con la sola variante dellĺuso dei
colori (si veda il riquadro 1). La classe RecordSet Ŕ
astratta, ma non necessariamente una interfaccia pura: di questo ci
renderemo conto meglio andando avanti nel design. Per ora,
RecordSet Ŕ un punto di estendibilitÓ
dellĺarchitettura, da cui derivare classi concrete che si
interfacciano a database reali: ad esempio, in figura 1 ho inserito
due classi che "parlano" con un DB tramite ODBC o tramite DAO.
Possiamo naturalmente ipotizzare di derivare classi che
interagiscano tramite interfacce proprietarie. Le classi concrete
contengono la logica necessaria, ad esempio, ad ottenere una
connessione con il DB, lĺapertura delle tabelle coinvolte
nella query, lĺestrazione del risultato della query,
ecc.
Dobbiamo ora affrontare il primo problema, ovvero la navigazione
sul recordset. Il problema Ŕ meno ovvio di quanto sembri, in
quanto le diverse classi concrete potrebbero avere requisiti del
tutto differenti circa la navigazione. Impostare una interfaccia a
livello di RecordSet del tipo GetRecord( int i ) renderebbe
RecordSet troppo rigida nei casi in cui la navigazione possa essere
solo sequenziale, o lĺindice debba essere qualcosa di diverso
da un intero (ad es. una struttura Position nota solo alla classe
concreta). Per contro, non vogliamo certamente legare il lato
applicativo ai dettagli delle classi concrete. Ci troviamo in
classico caso in cui non si deve violare la legge di Demeter
([LH93], [Pes95]).
Fortunatamente, esistono diverse tecniche per risolvere il
problema. Due in particolare potrebbero essere adatte, e si
differenziano per il posizionamento dellĺiniziativa. La prima
(che per ora non vedremo, ma che potete pensare come ad una
interfaccia di enumerazione) lascerebbe tutta lĺiniziativa di
navigazione allĺinterno del recordset. La seconda, che ho
deciso di utilizzare nel diagramma di figura 1, lascia
lĺiniziativa al chiamante (tipicamente altre parti del
framework, o il lato applicativo). In effetti, la navigazione sul
recordset pu˛ essere complessa a piacere, e mi sembra
preferibile lasciarne lĺiniziativa fuori dalla classe
RecordSet.
La soluzione Ŕ lĺuso di un iteratore [GoF94], ovvero una
classe ausiliaria che ha il compito di muoversi sui singoli record
allĺinterno del recordset. Notiamo che ancora una volta il
RecIterator Ŕ una classe astratta, il cui compito principale
Ŕ di restituire il record "puntato" dallĺiteratore. Da
questa possiamo derivare classi astratte legate a particolari tipi
di accesso al database (es. RecFWIterator per lĺaccesso solo
"in avanti", o RecRndIterator per lĺaccesso random). Da
queste deriviamo finalmente le classi concrete, che sanno come
iterare su un singolo recordset. Le classi iteratore concrete
saranno tipicamente accoppiate in modo circolare con le classi
recordset concrete: il recordset crea lĺiteratore,
lĺiteratore si sposta sul recordset. Questo rende le due
classi non riusabili individualmente [Pes99], ma si tratta di un
caso in cui non ritengo che lĺimpossibilitÓ di riuso
separato costituisca un problema.
Lĺiteratore pu˛ essere internamente molto semplice (ad
es. pu˛ risolversi in una semplice chiamata ad una funzione di
libreria per spostarsi nel database), o essere piuttosto complesso
da realizzare (si veda poco oltre). Lĺimportante Ŕ che
rispetti la sua interfaccia e, nellĺinsegnamento di STL,
anche i suoi vincoli computazionali: ad esempio, dovremmo imporre
che il RecFWIterator si sposti sul prossimo in tempo costante, e
che il RecRndIterator si sposti in tempo costante o logaritmico.
Queste decisioni sono importanti per permettere a chi utilizza i
nostri iteratori di progettare una soluzione scalabile.
Una nota implementativa: realizzare un iteratore su un recordset
pu˛ non essere banale come sembra. Se il database sottostante
"fonde" i concetti di recordset e di cursore sul recordset,
mettendoli in relazione 1-1, chiedere un nuovo iteratore su un
recordset esistente significa aprire un nuovo recordset come
risultato della stessa query, ottenendo cosý un nuovo cursore,
e poi garantire la coerenza tra i record "visti" a livello
applicativo attraverso i diversi cursori. Ma proprio perchÚ
non Ŕ banale, il problema Ŕ un ottimo candidato ad essere
risolto una volta per tutte ed incorporato nel framework, piuttosto
che essere lasciato alla responsabilitÓ dei programmatori che
lavorano a livello applicativo.
Torniamo alla figura 1: dereferenziando un RecIterator otteniamo il
Record puntato. La classe Record Ŕ nuovamente astratta, in
quanto potrebbero esservi degli aspetti implementativi che vanno
lasciati alle classi derivate. Tipicamente, avremo quindi una
classe concreta derivata da Record per ogni classe concreta
derivata da RecordSet, e gli iteratori concreti, quando
dereferenziati, restituiranno istanze di classi Record concrete,
pur se viste attraverso la loro interfaccia astratta.
Un Record, a livello strutturale, non Ŕ molto diverso da un
RecordSet. In fondo, in entrambi i casi ci troviamo di fronte ad
una aggregazione di elementi pi¨ semplici, in questo caso i
campi (Field). Nuovamente, il lato applicativo avrÓ interesse
ad esaminare uno o pi¨ campi. Qui entra decisamente in gioco
il concetto di reflection: vogliamo evitare la comparsa di classi
del tipo RecordFornitore con funzioni del tipo Get/SetNome,
Get/SetIndirizzo, ecc, che come abbiamo giÓ visto non portano
ad una interfaccia stabile.
Ci˛ che Ŕ stabile Ŕ invece la capacitÓ del
Record di esporre il suo contenuto: di "rivelare" quanti campi ha e
come si chiamano, nonchÚ restituire il campo desiderato dato
il nome. Talvolta saremo interessati a compiere la stessa azione su
tutti i campi, e potrÓ quindi tornare utile un FieldIterator.
In questo caso ho previsto solo un iteratore del tipo forward, ed
in pratica ho visto che si riesce a realizzare in funzione della
parte stabile di Record, senza necessitÓ di avere classi
FieldIterator separate per ogni database concreto. Non Ŕ detto
che con particolari librerie non si debba arrivare a derivare nuove
classi da FieldIterator, ma del resto nulla nella struttura di
figura 1 lo impedirebbe.
Lĺinterfaccia precisa della classe Record dipende
inevitabilmente dal linguaggio utilizzato per
lĺimplementazione. Ad esempio, in C++ ho utilizzato con
soddisfazione lĺoverloading degli operatori, per poter
scrivere codice del tipo:
Record& r = .... r[ "campo1" ] = 1234 ; r[ "campo2" ] = "abc" ; date d = r[ "campo3" ] ;
Ovvero accedere ai campi di un record tramite indicizzazione sul
loro nome (visto come stringa, perchÚ la maggior parte dei
database reali memorizzano cosý il nome del campo). Notiamo
che il pregio di questo approccio rispetto alla soluzione
GetNome/GetIndirizzo/ecc Ŕ che i nomi dei campi non sono
hard-coded, ma si possono facilmente mantenere in un file esterno,
dove Ŕ facile cambiarli se cambia il database. Su questo punto
torneremo ancora pi¨ avanti.
Vediamo finalmente la classe Field. Anche in questo caso esistono
diverse possibilitÓ realizzative, e quella che vi presento
Ŕ solo una che ho utilizzato e che ho visto funzionare a
dovere. Esistono alternative pi¨ complesse che a mio avviso
non ripagano, ma che potrebbero risultare pi¨ adatte in altri
contesti. Probabilmente vi servirÓ una classe concreta per
ogni tipo di database. Dico "probabilmente" perchÚ molto
dipende da come deciderete di implementare la classe Record, e da
come deciderete di partizionare lĺintelligenza tra Record e
Field. Ad esempio, se volessimo lasciare a Field lĺiniziativa
di estrarre il valore dal Record concreto (ancora in formato nativo
del DB) e di effettuare on-demand la conversione ai tipi stabili
che vogliamo esporre (esempio concreto: da una data memorizzata in
un qualunque formato ad una classe standard Date), seguendo un
criterio di lazy evaluation che eviti la conversione inutile dei
campi a cui non si accede, avremmo classi Field concrete derivate
da Field. Ma se decidessimo di posizionare tutta la logica di
conversione dentro le classi Record concrete, potremmo avere una
sola classe Field che ridirige le richieste su uno o pi¨
metodi di Record.
Di norma, io preferisco lasciare le conversioni al Field,
perchÚ in questo caso aggiungere il supporto per un nuovo tipo
di campo significa modificare la sola gerarchia dei Field lasciando
immutata la gerarchia dei Record. Ma nuovamente, si tratta di
decisioni di design di livello piuttosto dettagliato, che potrete
prendere caso per caso se decideste di mettere in pratica una
architettura simile a quella che stiamo discutendo.
Riassumendo, quale risultato abbiamo raggiunto sinora? Possiamo
creare un RecordSet in base ad una query, i cui elementi essenziali
possono facilmente essere resi esterni al programma (nei casi
pi¨ semplici, basterÓ spostare la stringa SQL in un file
di testo). Potremo poi muoverci sui record, secondo un criterio
arbitrario. Per ogni record, potremo spostarci sui campi in modo
uniforme (con un iteratore), indipendentemente dalla struttura del
record stesso, oppure indicizzare i diversi campi, nuovamente
attraverso un indice che possiamo facilmente spostare fuori dal
codice. Rimane ancora un poĺ scoperto il trattamento (ad
esempio a livello di presentazione) dei valori dei singoli campi,
che sono di tipo diverso. Questo sarÓ lĺargomento del
prossimo paragrafo.
Campi e presentazione
Per comprendere al meglio il supporto alle funzionalitÓ di
presentazione credo sia opportuno fare riferimento ad un semplice
esempio concreto: una griglia di visualizzazione del recordset,
naturalmente in grado di adattarsi alla visualizzazione di un
recordset qualunque, con formattazioni differenti nelle varie
situazioni, senza necessitÓ di modificare il codice della
classe Grid stessa. La classe Grid, che rispetto al nostro
framework appartiene giÓ al livello applicativo, Ŕ solo
un caso di presentazione di un intero recordset.
Situazioni analoghe possono essere rappresentate da un semplice
report (tabulato), da un file che esporta i dati di un intero
recordset, eccetera. Osserviamo che per ora non intervengono le
problematiche di modifica dei dati, di cui parler˛
nella prossima (e conclusiva) puntata.
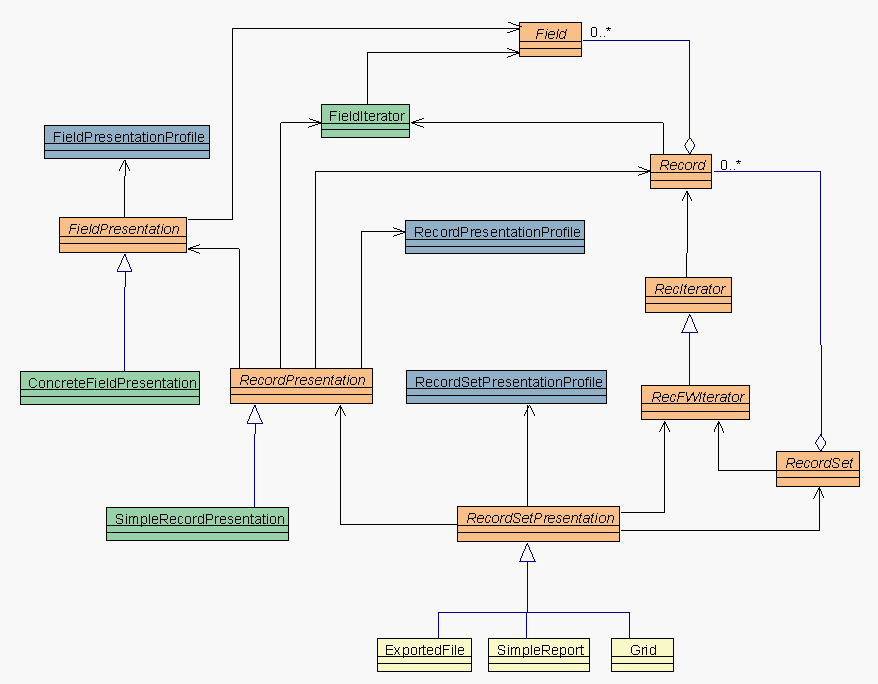
Il supporto alla presentazione Ŕ visibile in figura 2. Notiamo
che alcune classi (Field, Record, ecc) provengono dal diagramma di
figura 1. Ho evitato la notazione "from ..." per mantenere il
diagramma pi¨ compatto; non credo emergano comunque problemi
di comprensione.
Partiamo dal basso: la Grid, cosý come ExportedFile,
SimpleReport, ecc, altro non Ŕ che un RecordSetPresentation.
Questa Ŕ una classe astratta (ma non interfaccia), che
contiene logica sufficiente a ricevere un RecordSet, ottenere un
forward iterator su di esso, e iterare su tutti i record
processandoli secondo alcuni criteri. Criteri che ancora una volta
vanno possibilmente estratti dal codice, e spostati invece in un
supporto esterno (ancora una volta, ipotizziamo il classico file di
testo). Osserviamo infatti che un RecordSetPresentation fa
riferimento al proprio profilo, dove troveremo alcune parti custom
(tipiche del RecordSetPresentation concreto, ad esempio
lĺheader da utilizzare nel caso di un report) ed altre
standard, che possono essere processate dalla classe base. Tra
queste informazioni standard troviamo sicuramente il nome della
classe concreta da utilizzare per la presentazione di ogni singolo
Record, e del profilo da passare a tale classe. Nel caso di una
griglia, il RecordSetPresentationProfile potrebbe riferirsi ad un
file che, nellĺipotesi pi¨ semplice, contiene solo le
informazioni standard.
RecordSetPresentation deve quindi essere in grado di ottenere, dato
il nome della classe concreta (es. "SimpleRecordPresentation"), una
istanza di tale classe vista attraverso la sua base
RecordPresentation. Il modo in cui questa istanza viene ottenuta
Ŕ del tutto irrilevante. In Java, potremmo usare
forname/newinstance; in Windows, potremmo usare LoadLibrary per
caricare una DLL; e cosý via. In futuro vedremo che anche in
questo caso si utilizza una tecnica di trasformazione tipica del
SysOOD (Indexed Creation); per ora potete fare riferimento al
pattern da questa generato (Product Trader, si veda
[PloPD3]).
La classe RecordPresentation (e le sue classi derivate) contengono
la logica per realizzare la formattazione di un singolo record, in
base ad un profilo che possiamo nuovamente ipotizzare di mantenere
in un file di testo separato, ed a cui accediamo tramite la classe
RecordPresentationProfile. Tra le informazioni fondamentali, oltre
ad eventuali parametri custom utilizzati dalla classe concreta di
presentazione del record, troviamo sicuramente una lista di
specifiche di formattazione per ogni campo, ovvero qualcosa del
tipo:
Field1, ConcreteFieldPresentation1, profile1
Field2, ConcreteFieldPresentation2, profile2
Field3, ConcreteFieldPresentation1, profile2
(notiamo che righe diverse possono condividere la stessa classe
di presentazione del campo, e/o lo stesso profilo).
RecordPresentation, nella sua versione pi¨ semplice,
otterrÓ dal Record un iteratore sui campi, e li
processerÓ in sequenza in base alla lista di cui sopra.
Ovvero, otterrÓ in modo del tutto simile a RecordPresentation
una istanza alla classe concreta per la presentazione del campo, e
richiederÓ il processing del campo in base al profilo
specificato.
Ci spostiamo quindi a livello di presentazione del singolo campo.
In moltissimi casi reali, come quello della griglia, avremo una
sola classe concreta (ConcreteFieldPresentation) adatta a tutti i
campi, o al pi¨ un piccolo insieme di classi. Tuttavia,
lĺintroduzione di nuovi tipi di campo (immagini, suoni,
filmati, ecc) potrebbe richiedere lĺintroduzione di nuove
classi derivate; lo stesso potrebbe accadere se vogliamo introdurre
alcune nuove funzionalitÓ di formattazione, magari solo in
certe versioni custom del prodotto. Come sempre, lĺimportante
Ŕ che il framework preveda gli opportuni punti di
estendibilitÓ.
Cosa deve saper fare la classe concreta di presentazione del campo?
Fondamentalmente, leggere il profilo, accedere al campo, ottenere
il valore, formattarlo secondo il profilo e restituirlo. Possiamo
quindi ipotizzare di avere una classe "di libreria" (ovvero
concreta ma generalmente utile agli utilizzatori del framework) che
sia in grado di formattare i campi dei tipi primitivi secondo gli
schemi pi¨ comuni (valuta, data nei vari formati specificabili
nel profilo del campo, ecc). Ma come accennavo poco sopra, nulla
impedisce di introdurre nuove classi in grado, ad esempio, di
"formattare" un campo importo secondo una particolare regola di
arrotondamento inventata al momento da qualche analista. Il tutto
senza dover modificare una riga del codice esistente, ma
aggiungendo una classe (che se la piattaforma/linguaggio lo
consentono sarÓ opportuno separare come componente a livello
binario) e modificando il profilo, che avevamo spostato apposta
fuori dal codice.
Considerazioni
Prima di concludere la puntata, vi sono almeno due argomenti
che vorrei sollevare. Il primo, che tuttavia discuter˛ nel
prossimo numero, riguarda la complessitÓ strutturale della
soluzione che stiamo impostando. ╚ evidente che si tratta di
qualcosa piuttosto lontano dalla "classe base RecordSet da cui
deriviamo i recordset concreti" tipica degli approcci pi¨
tradizionali, e sicuramente la struttura Ŕ pi¨ ricca e
pi¨ complessa da capire. Sui vantaggi e svantaggi che questo
comporta mi soffermer˛ pi¨ a lungo nel prossimo
numero.
Un argomento sui cui vorrei invece spendere sin dĺora alcune
parole Ŕ lĺefficienza della soluzione. Quando, durante
il mio lavoro di consulente, mi capita di osservare alcune
soluzioni particolarmente rigide e poco manutenibili, la
seconda risposta (in ordine di frequenza) che ricevo Ŕ
"lĺabbiamo fatto cosý per ragioni di efficienza"; per i
curiosi, la prima Ŕ ovviamente "lĺabbiamo fatto
cosý perchÚ non cĺera tempo per farlo meglio". In
realtÓ lĺefficienza delle soluzioni ben strutturate non
ha nulla da invidiare a quella delle soluzioni custom: occorre
semplicemente aggiungere, dietro la stabilitÓ delle
interfacce, una maggiore intelligenza alle classi coinvolte. I
lettori pi¨ fedeli ricorderanno simili argomentazioni a
proposito della soluzione proposta nella miniserie sui sistemi
reattivi.
Vediamo un esempio concreto: se devo visualizzare (o pi¨
ragionevolmente esportare) 500.000 record, con una decina di campi
ciascuno, la struttura di figura 2 sembra introdurre un notevole
rallentamento, dovuto al continuo ripetersi di alcuni passi, come
la creazione di un RecordPresentation concreto per ogni record, ed
addirittura di un FieldPresentation per ogni campo. Questo
ovviamente nel caso in cui lĺimplementazione sia
particolarmente banale, e crei/distrugga gli oggetti dopo ogni
singola chiamata. Di fatto implementare un meccanismo di cache
efficiente per un piccolo numero di oggetti (in fondo, quanti
formattatori concreti avremo in un caso reale?) Ŕ
ragionevolmente semplice, e questo ci consente di ottenere il
nostro oggetto concreto (dopo la prima creazione) in pochi cicli di
clock. Una implementazione con hash table ben fatta pu˛
ridurre ad una ventina di cicli di clock il costo del lookup, ma
supponiamo che siano cento. Moltiplichiamo per 500.000 record, e
per i dieci campi, ottenendo 550 milioni di cicli di clock. Ovvero
un paio di secondi di una CPU moderna, su un processo che
durerÓ diversi minuti (estrarre 500.000 record da un DB non
Ŕ proprio questione di secondi).
Vediamo peraltro cosa succede nella situazione in cui si voglia
esportare solo 5 campi. Se usiamo ad es. i recordset di MFC, questi
faranno comunque le conversioni da "formato db" a "formato C++" per
ogni campo. I field "lazy" di figura 1 no. Questo, da solo,
pu˛ comportare un risparmio di tempo superiore ai pochi
secondi di cui sopra.
Ma soprattutto, pensiamo ad un caso reale, in cui il programma
esiste giÓ, nasce lĺesigenza di supportare un nuovo
campo e di rendere nuovamente operativo, il prima possibile, il
processo di esportazione. Se il tipo del campo Ŕ giÓ
supportato dalla classe Field e dai nostri formattatori (un evento
che mi sento di definire alquanto probabile), dobbiamo aggiornare
gli script dei profili e basta. Se quello che conta
realmente Ŕ il throughput del programma, dobbiamo considerare
anche i tempi di fermo dovuti a manutenzione: a questo punto,
facendo bene i calcoli, Ŕ facile concludere che minimi
rallentamenti come quello di cui sopra sono del tutto trascurabili
rispetto ai vantaggi complessivi di una soluzione che non richiede
modifiche al codice in un numero molto frequente di situazioni.
Cosa manca
Non avendo discusso la parte di modifica, manca anche ogni
supporto alla coerenza tra viste diverse. Manca inoltre una
discussione pi¨ approfondita di un altro tipo di presentazione
molto comune (la form), con tanto di campi calcolati, validazione e
pi¨ in generale di business rule. Di tutto questo parleremo
nella prossima, conclusiva puntata della miniserie. Nel frattempo,
se avete commenti, suggerimenti, eccetera, non esitate a mandarmi
qualche riga via email.
Bibliografia
[GoF94] Gamma ed altri, "Design Patterns", Addison-Wesley,
1994.
[LH93] Karl Lieberherr, Ian Holland, "Assuring Good Style for
Object-Oriented Programs", Technical Report, Northeastern
University, 1993.
[Pes95] Carlo Pescio, "C++ Manuale di Stile", Edizioni Infomedia,
1995.
[Pes99] Carlo Pescio, "Systematic Object Oriented Design", Computer
Programming No. 76.
[PloPD3] Autori vari, "Pattern Languages of Program Design, Vol.
3", Addison-Wesley, 1998.
Biografia
Carlo Pescio (pescio@eptacom.net) svolge attività di consulenza, progettazione e formazione in ambito internazionale. Ha svolto la funzione di Software Architect in grandi progetti per importanti aziende europee e statunitensi. È autore di numerosi articoli su temi di ingegneria del software, programmazione C++ e tecnologia ad oggetti, apparsi sui principali periodici statunitensi, nonché dei testi "C++ Manuale di Stile" ed "UML Manuale di Stile". Laureato in Scienze dell'Informazione, è membro dell'ACM, dell'IEEE e dell'IEEE Technical Council on Software Engineering.