Systematic Object Oriented Design, Parte 1
|
|
Dr. Carlo Pescio Systematic Object Oriented Design, Parte 1 |
Pubblicato su Computer Programming No. 81
Alcuni mesi fa ho presentato ai lettori di Computer Programming una panoramica su un approccio sistematico alla progettazione ad oggetti, che ho battezzato Systematic Object Oriented Design. In quell'occasione ho invitato chiunque fosse interessato ad alcune puntate di approfondimento ad inviarmi qualche riga via email. Come ho avuto modo di accennare nei numeri scorsi, il feedback è stato davvero notevole; inizia quindi in questo numero una miniserie dedicata al SysOOD, dove avrò modo di trattare in modo più organico ed esteso le tematiche relative.
Come molti di voi ricorderanno, il SysOOD è fondato su regole oggettive di design e su tecniche di trasformazione usate per garantire il rispetto di tali regole. Iniziamo quindi la miniserie prendendo in esame le quattro regole fondamentali del SysOOD, in modo da avere immediatamente una visione d'insieme delle casistiche coperte. Nelle prossime puntate vedremo, caso per caso, le tecniche di trasformazione principali; non credo che arriveremo a coprire tutto il SysOOD, ma ciò che vedremo sarà più che sufficiente per utilizzare concretamente le regole e le tecniche di trasformazione nel lavoro di ogni giorno.
1. Stratificazione
La prima regola che vedremo è già stata brevemente discussa nella puntata introduttiva [Pes99a], ma la riprenderò sia a beneficio di chi non ha letto l'articolo precedente, sia per discuterla più a fondo.
Il concetto di stratificazione del software è molto vecchio: significa strutturare un sistema "a livelli", in modo che ogni livello dipenda solo da quelli sottostanti. È tra l'altro interessante osservare che dove l'informatica è più consolidata, ad esempio nella costruzione di compilatori o di sistemi operativi, la struttura "a livelli" è ormai data praticamente per scontata.
I "livelli" di cui stiamo parlando, tuttavia, sono di norma macro-blocchi concettuali ("analizzatore lessicale", "analizzatore sintattico", "generatore di codice"), non elementi semplici ed elementari come le classi. Ha senso estendere lo stesso concetto anche ai moduli di granularità inferiore?
Per rispondere, prendiamo in considerazione uno tra i più importanti principi di design: "le astrazioni non devono dipendere dai dettagli". Si tratta di un principio di portata enorme, nel senso che gran parte delle problematiche di estendibilità, di riusabilità e di manutenibilità del software ricadono in modo piuttosto diretto sotto la sua influenza. Si tratta anche di un principio inerentemente ambiguo (cos'é una astrazione? Cos'é un dettaglio?) e privo di indicazioni concrete su come rispettarlo. Tentare di formulare in modo non ambiguo lo stesso principio è una impresa che si è sinora rivelata impossibile.
Tuttavia un buon sistema ad oggetti dovrebbe quasi sempre rispettare il principio in questione: se una astrazione (potenzialmente riusabile e potenzialmente stabile) si trova a dipendere da un aspetto specifico di una applicazione, difficilmente riusabile e probabilmente meno stabile, non riusciremo a riusare l'astrazione in altre applicazioni (perché "si porta dietro" parti specifiche di un altro contesto applicativo) e rischiamo anche di dover mettere mano all'astrazione se cambia l'interfaccia del dettaglio.
Stabilità e riusabilità sono quindi a rischio ogni volta che non rispettiamo il principio. Principio che tuttavia è definito in modo ambiguo e non verificabile in modo oggettivo! Ci troviamo in una situazione tipica dell'informatica contemporanea, che continua a rimanere ad uno stato alchemico anche perché alcune tra le guide principali sono impalpabilmente ambigue.
Una buona tecnica di pragmatica, quando ci si trova di fronte ad un problema troppo difficile, è di iniziare a risolverne una parte. Se abbiamo un minimo di fortuna, otterremo comunque un risultato di rilievo, e troveremo in seguito una soluzione per altre parti del problema stesso. Esiste ovviamente anche l'approccio opposto (cercare di risolvere un problema ancora più generale), che personalmente non sono riuscito ad applicare con successo al problema in questione.
Possiamo quindi tirare le fila: avere un diagramma delle classi strutturato a livelli (vedremo fra poco cosa significa esattamente) non solo estende a moduli di granularità più fine una tecnica ampiamente sperimentata per i macro moduli, ma è anche una condizione necessaria affinché le astrazioni non dipendano dai dettagli (per una qualunque definizione di astrazione e dettaglio!). Infatti, in un sistema non a livelli esisteranno delle dipendenze circolari tra gli elementi. Se pensiamo ad una gerarchia di astrazione, è evidente che in un sistema con dipendenze circolari avremo alcuni elementi che dipendono da altri elementi meno astratti.
Cosa significa esattamente avere un diagramma strutturato a livelli, o stratificato? Formalmente, significa che il grafo delle dipendenze associato al diagramma delle classi è aciclico. Ogni diagramma delle classi è infatti un iper-grafo etichettato, che può essere trasformato con estrema facilità in un grafo semplice diretto: basta trasformare ogni tipo di "freccia" (ereditarietà, aggregazione, associazione, ecc) in un unico tipo (ad esempio, nel caso di UML, nella dipendenza generica) e fondere le eventuali frecce multiple tra gli stessi nodi (che sono ovviamente le classi). La figura 1 mostra un semplice esempio, tratto da [Pes99b]: notiamo che va preso in considerazione un diagramma completo di tutte le relazioni, non il semplice grafo di ereditarietà a cui spesso si limita la documentazione delle librerie commerciali. È anche importante osservare, per chi pensa in termini di codice più che di diagrammi delle classi, che le relazioni di cui stiamo parlando sono proprio tutte le relazioni esistenti tra le classi, incluse quelle non visibili nella parte dichiarativa: ad esempio, una classe A che in suo metodo f() utilizzi una variabile di classe B avrà una dipendenza da B.
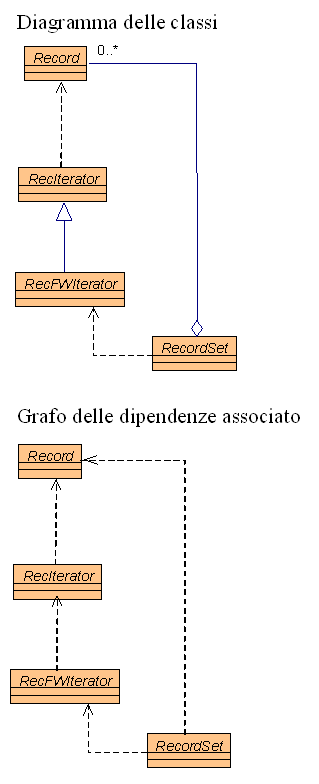
Al di là dell'aspetto formale, esiste comunque un aspetto intuitivo di estrema semplicità (nessuna dipendenza circolare), e la proprietà di stratificazione è sia verificabile in modo automatico (con un tool), sia verificabile "manualmente" semplicemente osservando un diagramma delle classi. In effetti è possibile verificarlo (sia in modo automatico che manuale) anche partendo dal codice, ma risulta un po' più complicato e, nel caso di verifica manuale, più facilmente soggetto ad errori. Viceversa, un buon diagramma delle classi permette una verifica a colpo d'occhio, in pochi istanti.
Cosa succede se non rispettiamo la regola? È molto importante chiarire questo aspetto, perché il processo di design deve tenere presenti molti fattori, e talvolta una soluzione sub-ottima è perfettamente accettabile: ad esempio, potremmo privilegiare una soluzione più semplice e più rapida da implementare rispetto ad una con maggiore riusabilità delle parti, se abbiamo scarso interesse a riusare quelle parti.
La conseguenza inevitabile e più immediata è che l'unità di riuso diventa il ciclo, non la classe. Nessuna classe appartenente ad un ciclo è riusabile singolarmente. In alcune situazioni reali, questo non è un grande problema: ne abbiamo visto un caso in [Pes99b], dove i recordset ed i loro iteratori erano accoppiati in modo circolare, ma non eravamo interessati a riusarli singolarmente. In moltissime altre situazioni, si tratta invece di un problema importante che va risolto come parte dell'attività di progettazione.
Una conseguenza più sottile, e non sempre presente, è che l'incorporazione di nuove funzionalità nel sotto-sistema, sotto forma di un'altra classe, può comportare l'inserimento della classe stessa nell'anello. Questo comporta sia la modifica di classi preesistenti (qualcosa che non vorremmo fare) sia una ulteriore degenerazione del sistema (l'ampliamento di una situazione già a rischio). Vedremo meglio come riconoscere questa situazione nella prossima puntata, quando vedremo quali tecniche di trasformazione possiamo usare e le relative euristiche.
Riassumendo: la prima regola del SysOOD dice che ogni design dovrebbe sempre essere stratificato, ovvero privo di dipendenze circolari nel diagramma delle classi. Violare la regola significa ridurre le possibilità di riuso indipendente e di estensione di funzionalità senza modifiche alla classi esistenti. Se queste conseguenze non sono accettabili, dobbiamo porvi rimedio, attraverso una delle tecniche di trasformazione associate alla regola. Sinora ne ho identificate cinque (di cui quattro fondamentali ed una derivata), ma ne parleremo nella prossima puntata: per ora, vi invito a riflettere su come affrontate normalmente il problema.
2. Dipendenze da classi concrete
I lettori più fedeli ricorderanno forse il mio articolo "Oggetti ed Interfacce" [Pes97], in cui veniva mostrato il ruolo centrale delle classi interfaccia nel design ad oggetti. Una classe interfaccia può ricoprire due ruoli fondamentali: disaccoppiare da una classe concreta e fornire un punto di estendibilità. Cercando un esempio più recente, nello schema finale dell'architettura di sistemi record-oriented (si veda [Pes99c]) la classe CalculatedFieldConsumer ha principalmente un ruolo di disaccoppiamento, mentre molte altre (es. CalcFieldRule) hanno principalmente un ruolo di hot-point di estendibilità.
L'uso di una classe interfaccia è però semplicemente una tecnica per rispettare una regola. Regola che si può nuovamente definire in modo oggettivo, e la cui violazione comporta un insieme di conseguenze prevedibili. Ricordiamo infatti che nell'ottica del SysOOD la violazione di una regola è sicuramente permessa, purché si tratti di una decisione conscia del progettista (che ha opportunamente valutato il trade/off tra costi e benefici).
Per arrivare alla formulazione della regola possiamo semplicemente considerare il caso di una classe A che dipende da una classe concreta B. È evidente che per riusare la classe A dovremo necessariamente riusare anche la classe B. È altrettanto evidente che la classe A non ha di per sé alcuna possibilità di operare su classi "simili" a B, tranne i casi in cui tali classi siano derivate da B: non potrebbe ad esempio essere utilizzata con classi che siano logicamente "sorelle" di B in un grafo di ereditarietà, o la cui interfaccia sia conforme al sottoinsieme di B utilizzato in A.
Queste limitazioni sono talvolta accettabili: se un dialog box contiene un bottone, la sua classe concreta dipende dalla classe bottone. È ragionevole che non si voglia riusare il dialog box senza bottoni, e che non si voglia supportare un meccanismo di conferma alternativo. In altri casi le limitazioni sembrano accettabili, soprattutto se nessuno richiama la nostra attenzione sul problema: che dire dello stesso dialog box che utilizza una list box come meccanismo di selezione, ma che potremmo riusare in altri contesti se potessimo cambiare il meccanismo di selezione (preservando invece tutta la logica)? In altri casi ancora le conseguenze sono ovviamente inaccettabili, ed anche in questi casi è utile avere una guida oggettiva che evidenzi il problema: tornando all'esempio precedente, una classe SimpleInterpreter che "parla" direttamente con una classe Form è assai meno riusabile di una classe SimpleInterpreter che conosce solo una classe astratta CalculatedFieldConsumer.
Riassumendo: la seconda regola del SysOOD dice che se la classe A dipende dalla classe B, B dovrebbe essere una classe astratta. Violare la regola significa ridurre la possibilità di riuso di A indipendentemente dalla classe concreta B, nonché la possibilità di estendere B a classi analoghe, mantenendo la capacità di A di interagire con tali classi.
In questo caso ho identificato tre tecniche di trasformazione fondamentali, in grado di rompere una dipendenza da classe concreta. Nuovamente, vi invito a pensarci su in attesa della prossima puntata. I più interessati potranno anche riflettere sul rapporto tra la regola in questione e l'Open/Closed Principle di Meyer ("modules should be both open and closed", [Mey97]), mentre direi che risulta ovvio il legame con un altro famoso principio "astratto" della programmazione ad oggetti ("program to an interface, not an implementation", [GoF94]).
3. Dipendenze di creazione
Come molti di voi avranno immaginato, la tecnica più semplice che possiamo adottare per rispettare la regola introdotta al punto precedente è l'interposizione di una classe interfaccia tra le classi A e B, con tanto di derivazione di B dall'interfaccia aggiuntiva. Ciò è sufficiente a risolvere il problema in alcuni casi (ad es. quando l'unica forma di dipendenza tra A e B è quella dovuta ai parametri di member function di A), ma in altre situazioni sposta semplicemente il problema ad un altro livello.
Consideriamo ad esempio il caso in cui il codice della classe A originale istanzi un oggetto di classe B. A ben poco serve interporre la classe interfaccia tra A e B, poiché la classe A dovrà comunque creare un oggetto di classe concreta (ovvero B). Dopo la creazione potrà manipolarlo attraverso l'interfaccia astratta, ma l'atto di creazione non è risolvibile così semplicemente.
Il problema delle dipendenze di creazione è sentito in modo molto forte anche da chi utilizza un framework che non sia stato progettato con la necessaria attenzione al problema (ovvero, quasi tutti i framework commerciali). Se ad esempio il framework crea alcuni oggetti che poi passa (come parametri di funzione) alle parti applicative, ci troviamo di fronte ad una forte rigidità in fase di estensione: noi potremmo estendere la classe a cui tali oggetti appartengono, derivando semplicemente una nuova classe. Purtroppo il framework continuerà a creare oggetti della classe originale, quindi la nostra derivazione servirà a ben poco.
In generale, la creazione di una classe è un istante molto importante, perché è normalmente necessario cablare nel codice il nome della classe stessa: se voglio istanziare un nuovo oggetto di classe Pippo, dovrò scrivere nel codice sorgente "new Pippo". Questo genera una dipendenza di creazione che va opportunamente gestita, pena la vanificazione di molti tentativi di gestire le dipendenze da classi concrete.
Esiste comunque una importante eccezione: se la classe B (quella "creata") è final, ovvero non è permesso derivare da questa ulteriori classi tramite ereditarietà, la dipendenza di creazione non genera effetti collaterali rilevanti. Infatti, se B è final non avremo per definizione alcun altro tipo concreto, compatibile per ereditarietà, da creare in sua vece. Notiamo che il concetto di classe final, pur se presente come costrutto primitivo solo in alcuni linguaggi (come Java) è comunque un concetto di design generale, peraltro implementabile "a mano" in altri linguaggi che ne sono sprovvisti (come il C++).
Riassumendo: la terza regola del SysOOD dice che se la classe A crea oggetti di classe B, la classe B dovrebbe essere final, oppure l'operazione di creazione deve essere ridefinibile (almeno nelle sottoclassi di A). La possibile restrizione alle sole sottoclassi di A è una concessione alla più semplice tra le soluzioni, che vedremo insieme alle altre tre tecniche di trasformazione fondamentali ed a quelle derivate in una prossima puntata. Le conseguenze di una violazione della regola sono piuttosto semplici: se estendiamo A, le classi derivate non potranno fare uso di versioni estese di B; se estendiamo soltanto B, la classe A non potrà utilizzare le versioni estese senza modifiche al proprio codice (con tanti saluti alla famosa "estendibilità del design ad oggetti").
Notiamo che le conseguenze della violazione sono talvolta accettabili: in genere, lo sono nelle situazioni in cui anche le conseguenze della violazione della regola 2 sono accettabili. Di norma, se ci troviamo in una situazione in cui si ha una violazione della regola 2 e della regola 3, rimediare alla violazione della 2 senza rimediare anche alla violazione della 3 è utile solo ai fini della semplicità di manutenzione ma non della reale estendibilità del design.
4. Legge di Demeter
A differenza delle regole precedenti, a cui ho attribuito un nome in quanto non erano già state classificate da altri, in questo caso ho semplicemente incorporato nel SysOOD una regola esistente che ritenevo fondamentale. La legge di Demeter [LH93] ha diverse formulazioni, ma la più semplice è la seguente: "Ogni metodo M di una classe C dovrebbe usare solo i suoi argomenti, i sotto-oggetti immediati di C, oppure oggetti creati localmente ad M od oggetti globali".
Apparentemente la legge di Demeter esclude ben pochi casi, ma in effetti essa impedisce al metodo di utilizzare i sotto-oggetti di un altro oggetto. Pur lasciando ampi spazi, si tratta quindi di una legge che viene violata con estrema frequenza: una dei casi più comuni è l'utilizzo da parte di M di un sotto-oggetto di un sotto-oggetto di C, in pratica scendendo di uno o più livelli all'interno della struttura di un oggetto complesso.
Pensate a righe del tipo data1.data2.f(), oppure data1->data2->f(), ma anche alle ovvie varianti dove gli accessi ai dati sono mascherati da funzioni di Get(): queste sono tutte violazioni della legge di Demeter. Nella sua apparente permissività, la legge di Demeter è invece la più restrittiva del SysOOD, e molto spesso anche la più complessa da rispettare nella sostanza.
Quali sono dunque le motivazioni dietro la legge di Demeter? Ricordiamo che uno dei cardini dell'ingegneria del software è il principio di Information Hiding, che non significa semplice incapsulazione (che è solo una tecnica) ma bensì l'intrapposizione mirata di una interfaccia resiliente tra gli utilizzatori di una astrazione ed i suoi dettagli soggetti a cambiamento.
Come sempre avviene, i grandi principi di design sono informali, difficili da applicare e difficili da verificare. La legge di Demeter si preoccupa di coprire una causa frequente di violazione di questo principio, che scatena una propagazione all'indietro delle modifiche ai dettagli implementativi: l'esposizione di dettagli circa la struttura interna di un oggetto. Struttura interna che molto spesso è instabile, e che se esposta comporta una violazione del principio di Information Hiding.
Secondo gli autori che hanno formulato la legge, questa dovrebbe sempre essere rispettata; nell'ottica del SysOOD le leggi non sono inviolabili: dobbiamo però chiarire meglio quali siano le conseguenze di una violazione della legge di Demeter.
La conseguenza di una violazione è che l'oggetto M lega la sua stabilità a quella di tutti i sotto-oggetti di altri oggetti a cui accede direttamente. Questo è particolarmente negativo se l'instabilità in questione viene propagata anche ai client di M, con un potenziale effetto a cascata ad ogni modifica.
Vi sono alcune situazioni (poche come numero, abbastanza frequenti come occorrenza) in cui violare la legge di Demeter non comporta grandi problemi. Un caso semplice è un pool di risorse, che permetta al chiamante di accedere ai propri sotto-oggetti (le risorse stesse), meglio se attraverso una classe interfaccia. In questo caso non esiste instabilità nel numero dei sotto-oggetti (mascherato dall'astrazione Pool) né nella loro natura (mascherata dall'interfaccia restituita).
In moltissimi altri casi, violare la legge di Demeter rende interi sotto-sistemi fragili: gran parte dell'architettura per sistemi record-oriented che abbiamo visto nelle scorse puntate ruota intorno all'idea di non creare instabilità dovute alla violazione della legge di Demeter. Vi invito peraltro a rivedere il diagramma finale (in [Pes99c]) nell'ottica delle regole del SysOOD.
È sempre possibile rispettare la legge di Demeter (esiste un teorema in proposito). So anche dell'esistenza di un tool che cerca di modificare il codice in modo da rispettare la legge: in un certo senso, questa è l'applicazione estrema delle tecniche del SysOOD. Purtroppo il tool in questione è basato su poche "tecniche di trasformazione" (tra virgolette in quanto il tool è più vecchio del SysOOD) ed il risultato è spesso peggio del codice originale.
Nell'ottica del SysOOD, la selezione della migliore tecnica di trasformazione, e la sua applicazione, sono passi importanti che non si possono delegare ad un tool (che potrebbe segnalare le violazioni ed eventualmente suggerire una trasformazione) ma fanno parte della attività del progettista.
Sinora ho identificato cinque tecniche di trasformazione associate alla legge di Demeter. Di nuovo, vi invito sia a pensare al problema che alle sue connessioni, non solo con il principio di Information Hiding, ma anche con l'onnipresente Open/Closed Principle.
Conclusioni
Le quattro regole fondamentali del SysOOD sono semplici, verificabili in modo oggettivo, e prive delle ambiguità dei grandi principi di design. Ciò nonostante, catturano un grande insieme di casistiche, ed un design che le rispetta ha una buona probabilità di garantire quelle famose proprietà di estendibilità, riusabilità, manutenibilità di cui sempre si parla a proposito degli oggetti.
Rispettare tutte le quattro regole del SysOOD, in tutte le occasioni, non è comunque semplice. È importante capire che non è neppure sempre necessario: è compito nostro (come progettisti) valutare quando le conseguenze di una violazione sono accettabili, soprattutto se comparate con lo sforzo necessario a ricondurre il design nel pieno rispetto delle regole. Operazione che coinvolge le tecniche di trasformazione associate ad ogni regola, che inizieremo a prendere in esame dalla prossima puntata.
Bibliografia
[GoF94] Gamma ed altri, "Design Patterns", Addison-Wesley, 1994.
[LH93] Karl Lieberherr, Ian Holland, "Assuring Good Style for Object-Oriented Programs", Technical Report, Northeastern University, 1993.
[Mey97] Bertrand Meyer, "Object Oriented Software Construction, 2nd Edition", Prentice-Hall, 1997.
[Pes97] Carlo Pescio, " Oggetti ed Interfacce ", Computer Programming No. 63
[Pes99a] Carlo Pescio, "Systematic Object Oriented Design", Computer Programming No. 76.
[Pes99b] Carlo Pescio, "Architettura di Sistemi Record Oriented, parte 2", Computer Programming No. 78.
[Pes99c] Carlo Pescio, "Architettura di Sistemi Record Oriented, parte 3", Computer Programming No. 79.
Biografia
Biografia
Carlo Pescio svolge attivitŕ di consulenza e formazione in ambito internazionale nel campo delle tecnologie Object Oriented. Ha svolto la funzione di Software Architect in grandi progetti per importanti aziende europee e statunitensi. Č l'ideatore del metodo di design ad oggetti SysOOD (Systematic Object Oriented Design), ed autore di numerosi articoli su temi di ingegneria del software, programmazione C++ e tecnologia ad oggetti, apparsi sui principali periodici statunitensi. Laureato in Scienze dell'Informazione, č membro dell'ACM e dell'IEEE.