Systematic Object Oriented Design, Parte 3
|
|
Dr. Carlo Pescio Systematic Object Oriented Design, Parte 3 |
Pubblicato su Computer Programming No. 87
Riprendiamo, dopo un mese di assenza, a parlare di Systematic OOD. In particolare, in questa puntata prenderemo in esame le tecniche di trasformazione associate ad una delle regole fondamentali, che si ispira direttamente ad alcuni grandi principi di progettazione e li rende verificabili in modo oggettivo.
Prima di entrare nei dettagli, vorrei ringraziare tutti i lettori che continuano a richiedermi una maggiore presenza sulle pagine di Computer Programming. Purtroppo negli ultimi mesi il tempo che riesco a dedicare alla scrittura di articoli è piuttosto limitato, ma con un po' di fortuna dovrei riuscire a ricavare uno spazio maggiore nei mesi a venire. Nel frattempo, invito come sempre chiunque volesse esprimere opinioni, dare suggerimenti, eccetera, a non esitare ad inviare qualche riga via email. Il vostro feedback è sempre essenziale per dare agli articoli le giuste direzioni, il taglio appropriato ed il livello di dettaglio più opportuno.
Dipendenze da classi concrete
Chi ha seguito sin dall'inizio questa miniserie ricorderà che il SysOOD consta di due elementi fondamentali: le regole di design (che devono specificare anche le conseguenze di una violazione) e le tecniche di trasformazione associate, che possono essere utilizzate per riportare il design entro i limiti segnati da ogni regola.
Nella presente puntata vedremo le tecniche di trasformazione associate alla seconda regola del SysOOD [Pes99a], che riprendiamo brevemente: se la classe A dipende dalla classe B, B dovrebbe essere una classe astratta. Ricordiamo che violare la regola significa ridurre la possibilità di riuso di A indipendentemente dalla classe concreta B, nonché la possibilità di estendere B a classi analoghe, mantenendo la capacità di A di interagire con tali classi. In molti casi concreti, le conseguenze della violazione non sono accettabili, ed intervengono quindi le diverse tecniche di trasformazione.
Notiamo che questa semplice regola di design non solo giustifica la grande importanza delle classi interfaccia nel design ad oggetti (si veda ad esempio [Pes97a]), ma razionalizza anche le possibilità di riuso ottenibili attraverso la programmazione generica, dove i parametri permettono, per l'appunto, di disaccoppiare le classi parametriche da specifici tipi concreti. Come vedremo, esistono anche altre tecniche (elementari o composte) che possono aiutarci a gestire le dipendenze da classi concrete.
Tra i principi di design che questa regola si pone l'obiettivo di rispettare troviamo sicuramente l'Open/Closed principle di Bertrand Meyer [Mey97]. Infatti, se la classe A dipende dalla classe B, per estenderla ad utilizzare i servizi di altre classi dovremo necessariamente "aprirla", un passo spiacevole con una serie di conseguenze negative, come re-testing, re-distribuzione, eccetera.
Come nella precedente puntata, per evidenti ragioni di spazio mi limiterò a trattare le diverse regole in base ad un esempio astratto, rappresentato dalla figura 1 (dove la classe A dipende dalla classe concreta B).
So bene che una discussione legata ad esempi tratti da programmi reali è più semplice da seguire (non a caso cerco sempre di utilizzare problemi real-world nei miei corsi), ma con una simile impostazione andremmo ben oltre gli spazi ragionevoli di una rivista. Credo comunque che chiunque sia interessato al design potrà seguire i contenuti dell'articolo senza sforzi eccessivi.
Interface Class
La prima tecnica che vedremo è anche la più semplice, e molti di voi l'avranno sicuramente utilizzata parecchie volte, magari a livello intuitivo. Se A dipende da B, ma vogliamo disaccoppiare A dalla classe concreta B, interponiamo una classe interfaccia, come da figura 2. La classe B2 è totalmente identica a B, tranne per la derivazione dall'interfaccia B*.
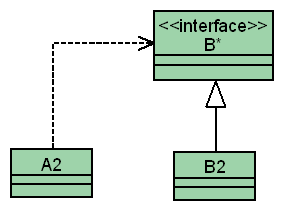
Quali sono i metodi nella classe B*? Una applicazione sistematica della regola porta a definire B* come il sottoinsieme delle operazioni di B utilizzate in A. In pratica, è sempre opportuno far seguire l'applicazione sistematica della regola da una fase di rifinitura, dove è indispensabile il buon senso del progettista. Ricordiamo infatti che ogni classe, interfacce comprese, dovrebbe essere "sensata": dovrebbe cioè corrispondere ad una astrazione significativa. Un buon indizio circa la significatività dell'interfaccia B* sta nella possibilità di trovarle un nome chiaro e rilevante all'interno del dominio del problema o della soluzione.
Attenzione alle varie trappole tese da chi vuole sovrasemplificare il problema (tipicamente per spostare la vostra attenzione su fattori tecnologici anziché sulla buona progettazione). Aggiungere sistematicamente una I di fronte al nome di una classe concreta non è decisamente il modo migliore per trovare i nomi alle interfacce: nasconde infatti un possibile design discutibile dietro una apparente semplicità operativa. Analogamente, non sempre scegliere una funzione principale e trasformarla in aggettivo (Resize à
Resizeable) è il modo migliore di trovare il nome adatto ad una interfaccia: che fare quando abbiamo diverse funzioni, nessuna delle quali predomina sulle altre?
L'impossibilità di trovare un buon nome (e quindi la sottostante astrazione) per l'interfaccia B* può essere il sintomo di tre differenti problemi. Il primo è l'incompletezza di B*: talvolta, dopo il passo sistematico dobbiamo completare l'astrazione aggiungendo funzioni non utilizzate da A, ma significative e presumibilmente utili ad altre classi client. Il secondo è la disomogeneità di B*: talvolta il passo sistematico fonde in un'unica classe operazioni logicamente ascrivibili ad astrazioni differenti. In tal caso, pensate a partizionare B* in interfacce diverse, tutte implementate da B, ognuna delle quali sia significativa. Il terzo è l'inadeguatezza della tecnica di trasformazione in questione: possiamo quindi prendere in considerazione una delle tecniche alternative che seguiranno.
Un ottimo indizio circa l'idoneità di questa tecnica è invece la nascita di una classe interfaccia snella, chiaramente collocabile come astrazione significativa, e presumibilmente stabile e completa anche dal punto di vista di altre classi client. Per alcuni esempi real-world, e per una più ampia discussione della qualità di una interfaccia, vi rimando al mio precedente articolo [Pes97a], che vi ricordo essere disponibile (come molti altri) anche attraverso la mia web page, all'indirizzo www.eptacom.net.
Una nota importante, anche se apparentemente banale: l'interfaccia interposta svincola la classe A dalla classe concreta B soltanto nella misura in cui l'interfaccia ci consente realmente di astrarci da B. Vediamo un esempio concreto: se la nostra classe B è un recordset basato su una particolare tecnologia di database, interporre una interfaccia può consentirci di sostituire la tecnologia sottostante, ma soltanto se nessuna member function finisce per esporre, più o meno direttamente, dettagli legati ad una particolare tecnologia. Se invece il nostro obiettivo è sganciarci dalla struttura del recordset (in termini di campi) l'interfaccia dovrà essere ancora diversa.
Vedremo in una puntata futura che un'altra regola (la legge di Demeter) interviene in nostro aiuto, consentendoci di capire meglio quando ci troviamo in queste situazioni; e che le tecniche di trasformazione associate ci permettono di rimediare ad eventuali problemi.
Come ultimo punto, va ricordato che in alcuni linguaggi l'introduzione di una classe interfaccia ha conseguenze non banali sotto il profilo delle prestazioni, che il progettista deve attentamente valutare nella sua analisi di costi e benefici.
Prima di passare alla prossima tecnica di trasformazione, lascio un piccolo esercizio per i lettori più attenti. La tecnica di Interface Class per rompere una dipendenza da classe concreta ha molto in comune con l'Asymmetric Splitting visto nella puntata precedente. Sino a che punto è vera questa affermazione?
Generic Class
La tecnica di Generic Class (si veda la figura 3) è quasi una gemella della Interface Class: ha comunque delle implicazioni non banali, che meritano una discussione.
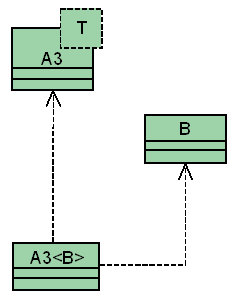
In questo caso non siamo costretti a modificare la classe B, ma l'intervento su A diventa più ampio: la classe A diventa infatti parametrica (un template per chi usa il C++), e viene disaccoppiata dalla classe concreta B proprio grazie al parametro T.
Nel nostro design apparirà poi una classe concreta A3<B>, istanza della classe parametrica A3 con parametro attuale B. Notiamo che, come già discusso per l'omonima tecnica nel numero precedente, A3<B> continua a violare la regola che stiamo discutendo. Questo non è tuttavia un problema reale, in quanto A3<B> non ha codice proprio da manutenere, ma è semplicemente una istanza della classe parametrica A3.
Vale ora sicuramente la pena di far notare alcuni punti interessanti. Il primo, che ho già affrontato a lungo in altri articoli (si veda ad es. [Pes97b]) riguarda il rapporto tra OOP e programmazione generica. In particolare, la tecnica Interface Class consente la riusabilità di A e l'estendibilità tramite polimorfismo a run-time di B. La tecnica Generic Class si preoccupa solo della riusabilità di A.
Un secondo punto importante è la possibilità di adottare la Generic Class senza modificare la classe B. Questo è sicuramente vero in molti casi, ma in un buon numero di situazioni può essere vantaggioso rivedere nomi e parametri delle funzioni di B utilizzate da A, in modo da rendere il template A3 più facilmente istanziabile su classi diverse da B. Viceversa, potremmo ottenere un disaccoppiamento teorico ma non sostanziale.
Un terzo punto riguarda le prestazioni: in molti linguaggi, l'uso della programmazione generica evita l'overhead introdotto da tecniche ad oggetti come l'ereditarietà, e può quindi essere preferibile nei casi in cui si vogliano limare i cicli di clock.
Un ultimo punto interessante, ma più legato ai dettagli dei linguaggi, riguarda la necessità o meno di definire le funzioni richieste al tipo T. Ho già accennato nel succitato [Pes97b] alla possibilità, in alcuni linguaggi come il C++, di lasciare questa informazione a livello implicito, evitandoci così la responsabilità (ma anche i benefici di verifica) di definire l'equivalente dell'interfaccia B*. Vi suggerisco comunque di fare lo sforzo di definire chiaramente cosa la classe A3 richieda al suo parametro T, e di verificare l'interfaccia di T (esplicita o implicita che sia) secondo gli stessi criteri visti al paragrafo precedente.
Abstract Wrapper
Torniamo momentaneamente alla prima tecnica presentata. Come abbiamo visto, è necessario modificare la classe B, derivandola da una nuova interfaccia. Non sempre questo è possibile: pensate a classi di libreria. Inoltre, potremmo trovarci in una situazione in cui allo stesso comportamento astratto (es. disegnarsi sul video) corrispondono, in classi diverse già esistenti, funzioni con nomi o parametri differenti.
Se queste classi sono fuori dal nostro controllo, applicare la tecnica di Interface Class non è possibile. Se i nomi delle funzioni coincidono, potremmo tentare di utilizzare la tecnica di Generic Class, ammesso che non ci interessi il polimorfismo ad oggetti.
Del resto, anche se le classi sono sotto il nostro controllo, o semplicemente sotto la nostra influenza (es. classi sviluppate internamente all'azienda) potrebbe non essere sensato derivarle da una ulteriore interfaccia: abbiamo visto che la tecnica di Interface Class andrebbe adottata quando l'interfaccia emergente risulta significativa nel dominio del problema o della soluzione cui la classe B appartiene.
Come fare, quindi, nei casi restanti? Una buona tecnica è quella presentata in figura 4, ovvero: creare un wrapper W per la classe B, che resta immutata. Il wrapper ha il compito di uniformare i nomi, e quando necessario (e possibile) i parametri delle funzioni di B rispetto ad una visione più astratta, che possa potenzialmente accomunare altre classi. La classe interfaccia W* disaccoppia la classe A dai wrapper concreti.
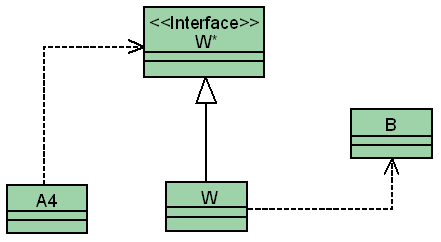
Sono sicuramente utili alcune precisazioni. La prima è che il singolo wrapper W è, di solito, decisamente specializzato: chiama un sottoinsieme di funzioni di B che sono utili ad A. È peraltro tipicamente una classe piccola, che non ci interessa riusare fuori dal contesto in cui appaiono sia B che A. Ed infatti non sarà riusabile: va contro alla stessa regola che la tecnica che stiamo discutendo si prefigge di far rispettare!
Proprio qui sta uno dei punti centrali del SysOOD: noi non applichiamo le tecniche, o cerchiamo di rispettare le regole, in nome di qualche virtù astratta. Le usiamo per ottenere benefici concreti: in questo caso, la riusabilità di A indipendentemente dalla classe concreta B. È più che lecito introdurre, per ottenere questo obiettivo, degli elementi minori non riusabili come la classe W. Capire questo punto è essenziale per entrare nel modus operandi del SysOOD.
Un ulteriore punto interessante è che la tecnica dell'Abstract Wrapper è derivata, non primitiva. Potete pensare alla sua derivazione come segue: inizialmente A delega ad un classe intermedia W il colloquio con B. La classe A rimane non riusabile, quindi usiamo la tecnica di Interface Class tra A e W. Otteniamo così la struttura dell'Abstract Wrapper, dove W e B restano legate, ma B rimane immutata e W non ci interessa sotto il profilo della riusabilità.
Notiamo che Abstract Wrapper richiede la scrittura di una piccola classe ulteriore, ma ha vantaggi piuttosto interessanti: non dobbiamo modificare B, ma otteniamo riusabilità lato A ed estendibilità con polimorfismo ad oggetti lato B. Ha tuttavia l'overhead maggiore tra le tecniche qui presentate: come sempre, flessibilità ed efficienza sono in contrasto, ma il costo in termini computazionali va attentamente misurato, quindi né sopravvalutato sin dall'inizio né ignorato sino all'ultimo.
La tecnica dell'Abstract Wrapper è alla base di diversi design pattern, come Command [GoF94] o External Polymorphism [CSH98]; come sempre le analogie fra pattern che "sembrano" simili nella struttura si rivelano piuttosto ovvie una volta evidenziata la regola di design e la tecnica di trasformazione sottostanti.
Conclusioni
Una puntata breve ma non per questo meno importante. Più volte negli ultimi anni ho sottolineato come l'uso mirato di classi interfaccia possa fare la differenza tra un design eccessivamente rigido ed uno con le giuste caratteristiche di flessibilità. Come abbiamo visto, però, esistono tecniche alternative alla semplice interposizione di una classe interfaccia, che portano allo stesso risultato di disaccoppiamento. L'euristica associata ad ogni tecnica dovrebbe guidarvi piuttosto facilmente alla selezione della soluzione migliore nei diversi contesti in cui vi troverete ad applicarla. In altri casi sarà il linguaggio stesso a porre dei vincoli: inutile prendere in considerazione la tecnica di Generic Class se il nostro design dovrà essere implementato in Visual Basic o in Java, che non prevedono un supporto per la programmazione generica.
L'ultima tecnica vista richiama anche una lezione che è importante tenere sempre a mente: violare una regola di design è perfettamente lecito, purché sia una decisione conscia e magari documentata come parte dei diagrammi del progetto. Questo è vero sia per il design delle applicazioni che per le tecniche di trasformazione derivate.
Vi lascio anticipando il tema portante della prossima puntata: se la classe A, modificata attraverso una delle tecniche sopra esposte, dipende ora da una classe astratta, chi crea le istanze di classe concreta che A dovrà comunque utilizzare? Anche in questo caso, probabilmente avete dovuto affrontare il problema in passato, e vi invito a pensare a quali tecniche avete normalmente adottato per risolverlo. Provare ad esprimere queste tecniche come trasformazioni in stile SysOOD potrebbe essere un ottimo spunto di riflessione.
Bibliografia
[GoF94] Gamma ed altri, "Design Patterns", Addison-Wesley, 1994.
[CSH98] Chris Cleeland, Douglas C. Schmidt, Tim Harrison, "External Polymorphism", in Pattern Languages of Program Design Vol. 3, Addison-Wesley, 1998.
[Mey97] Bertrand Meyer, "Object Oriented Software Construction, 2nd Edition", Prentice-Hall, 1997.
[Pes97a] Carlo Pescio, "Oggetti ed Interfacce", Computer Programming No. 63.
[Pes97b] Carlo Pescio, " Programmazione ad Oggetti e Programmazione Generica ", Computer Programming No. 62.
[Pes99a] Carlo Pescio, "Systematic Object Oriented Design, Parte 1", Computer Programming No. 81.
Biografia
Biografia
Carlo Pescio svolge attivitŕ di consulenza e formazione in ambito internazionale nel campo delle tecnologie Object Oriented. Ha svolto la funzione di Software Architect in grandi progetti per importanti aziende europee e statunitensi. Č l'ideatore del metodo di design ad oggetti SysOOD (Systematic Object Oriented Design), ed autore di numerosi articoli su temi di ingegneria del software, programmazione C++ e tecnologia ad oggetti, apparsi sui principali periodici statunitensi. Laureato in Scienze dell'Informazione, č membro dell'ACM e dell'IEEE.