Design: Task e Thread
|
|
Dr. Carlo Pescio Design: Task e Thread |
Pubblicato su Computer Programming No. 43
Introduzione
I sistemi operativi multi-tasking sono ormai
molto diffusi, sia nelle forme preemptive che non-preemptive;
in molti casi, è anche disponibile una forma di "task
all'interno del task", chiamato normalmente thread
o lightweight process. Esistono anche librerie per lo sviluppo
di programmi multi-threaded su piattaforme single-task come l'ormai
vetusto MS-DOS. L'utilizzo di queste funzionalità del sistema
operativo prescinde in gran parte dal paradigma di sviluppo utilizzato;
tuttavia, se progettiamo un sistema che verrà ospitato
su una piattaforma che consente il multitasking e/o il multithreading,
possiamo ottenere la migliore architettura solo valutando con
attenzione i possibili vantaggi offerti dal sistema operativo
sottostante.
In questa puntata approfondiremo i principali fattori che influenzano
la progettazione orientata agli oggetti, quando la piattaforma
target disponga di funzionalità di multitasking o multithreading.
Nel fare questo, riprenderemo diversi concetti legati al modello
dinamico, che per sua natura è strettamente legato al modello
di tasking prescelto.
Per ragioni di spazio, non discuteremo in questa
sede i fondamenti della programmazione concorrente e parallela;
assumeremo pertanto una conoscenza, anche superficiale, dei concetti
di concorrenza e cooperazione, di protezione delle risorse, comunicazione
inter ed intra-task, e così via. Per chi volesse approfondire
queste tematiche, si consiglia un buon testo sulla programmazione
concorrente, ad esempio [1].
Oggetti, Task e Thread
La decisione più difficile da prendere
correttamente è in effetti il corretto partizionamento
degli oggetti, ovvero quali apparterranno ad un certo task e quali
ad un altro, quali oggetti apparterranno ad un thread (o viceversa),
e così via.
Vi sono al proposito diverse opzioni, nonché
diverse opinioni tra gli esperti: ad esempio, non pochi suggeriscono
di avere un thread per ogni oggetto. Da un punto di vista astratto,
in effetti, questa posizione è largamente condivisibile:
gli "oggetti" del mondo reale sono entità autonome,
ed ognuna "agisce" in modo sostanzialmente indipendente,
anche se talvolta in coordinazione e cooperazione con altri oggetti.
Vedere un oggetto come un thread sembra anche una naturale evoluzione
del concetto di monitor (un particolare metodo per l'accesso
alle risorse [2]), dove ogni oggetto diventa un monitor per le
proprie risorse interne. Gli "oggetti attivi" di questo
tipo vengono talvolta chiamati attori [3] ed esistono anche
linguaggi che supportano direttamente ed in modo trasparente questo
tipo di semantica per gli oggetti.
Ciò non significa che sia sempre la
scelta migliore: anzi, in molte occasioni è possibile arrivare
ad un design più efficiente, o più semplice da capire
e da mantenere, solo compiendo lo sforzo necessario per individuare
i livelli di task, thread, e gli oggetti che devono agire ai diversi
livelli. Pertanto, vedremo ora alcuni dei fattori che influenzano
la scelta, insieme ad alcune linee guida molto generali per la
progettazione del sistema; ovviamente, come in altri casi, è
impossibile restare completamente indipendenti dall'architettura
hardware/software su cui il sistema stesso verrà poi implementato:
ad esempio, esistono grandi differenze, sia a livello delle prestazioni
nelle diverse situazioni, sia a livello dei criteri da utilizzare
nel progetto, a seconda che il multitasking (o il multithreading)
sia di tipo cooperativo o preemptive.
overhead a run-time:
a meno che la piattaforma hardware sia di tipo multi-processore,
un programma multi-tasked o multi-threaded subirà un overhead
rispetto ad una versione mono-task e mono-thread, overhead motivato
in massima parte dal tempo di task/thread switching.
Occorre comunque capire a fondo la differenza
tra velocità e responsività di un sistema: se la
ricerca di una stringa in un testo avviene concorrentemente alla
compilazione di un programma, il tempo totale sarà probabilmente
superiore alla somma dei due tempi di sola ricerca e sola compilazione;
tuttavia, per l'utente il sistema sarà comunque più
responsivo, in quanto gli consentirà di eseguire un lavoro
(ricerca della stringa) concorrentemente ad un altro (compilazione).
Inoltre, in tutti i sistemi con una forte interazione con periferiche
lente rispetto alla CPU (stampanti, seriali, l'utente stesso)
il processore si trova spesso in stato di inattività: in
questi casi, la somma dei tempi di esecuzione sequenziale può
essere anche superiore al tempo di esecuzione concorrente, a tutto
vantaggio di quest'ultima.
Naturalmente, per ottenere questo vantaggio
occorre conoscere bene le prestazioni ottenibili dalla macchina
target: normalmente, oltre un certo numero di task le prestazioni
degradano in modo piuttosto brusco, a causa dell'overhead di task
switching; è normalmente possibile avere molti più
thread attivi che non task, prima di avere lo stesso fenomeno
di crollo delle prestazioni, proprio perché un thread-switching
è molto più "economico" di un task-switching.
fluidità dell'interazione: come accennato al punto precedente, uno degli scopi da perseguire è una maggiore fluidità dell'interazione con l'utente; pertanto, ogni volta che sia possibile isolare un insieme di attività che possono essere eseguite in modo concorrente, minimizzando così le attese dell'utente, queste costituiscono dei candidati per il partizionamento in task o thread, in funzione di criteri che vedremo più avanti. Esempi tipici sono la stampa, l'acquisizione dati da una periferica, attività "batch" come la compilazione o l'elaborazione di dati e immagini, e così via; ad esempio, in un programma di elaborazione digitale delle immagini potremmo allocare su un task (o un thread) diverso la stampa delle stesse, ed allocare un thread di elaborazione per ogni immagine, in modo che sia possibile eseguire una elaborazione lenta e complessa mentre si continua l'editing di una seconda immagine. Se conosciamo le prestazioni tipiche del sistema, possiamo anche prevenire il trashing imponendo un numero massimo di elaborazioni concorrenti.
uso di linguaggi diversi: in un sistema multi-tasking ben progettato, i vari task dovrebbero comunicare attraverso un protocollo ad alto livello (vedi oltre). Ciò ha anche il vantaggio di permettere la codifica di task diversi in linguaggi diversi; mentre per piccole applicazioni ciò è spesso controproducente, in quanto richiede sforzi "di adattamento" ai programmatori, su applicazioni medio/grandi può essere un'ottima opportunità per utilizzare il linguaggio più adatto ad ogni compito (ad esempio, un linguaggio pensato per lo sviluppo rapido per l'interfaccia utente, un linguaggio efficiente per un back-end di calcolo numerico), nonché una possibilità di impiegare programmatori con competenze e formazione diversa. Notiamo che ciò non avviene, naturalmente, a livello di thread, che normalmente hanno accoppiamento di comunicazione più alto, e vengono scritti nello stesso linguaggio del task che li ospita.
tempi di compilazione: come conseguenza delle considerazioni viste al punto precedente, anche se manteniamo lo stesso linguaggio di codifica, abbiamo un completo isolamento delle unità di compilazione per i diversi task. Nuovamente, su un grande sistema ciò può corrispondere a grandi risparmi nel tempo di sviluppo, proprio perché ogni task può essere modificato e ricompilato in una frazione del tempo necessario alla ricompilazione e soprattutto al linking dell'intero sistema. Nuovamente, questo vantaggio si applica solo ai task, non ai thread.
dimensione concettuale:
se i task sono debolmente accoppiati ed altamente coesivi, come
ci si aspetta che siano, e se la comunicazione avviene attraverso
un protocollo ad alto livello, è ragionevole aspettarsi
che gli sviluppatori (inclusi coloro che si occuperanno della
manutenzione) troveranno molto più semplice comprendere
nella sua interezza il task di cui si occupano. Viceversa, un
sistema monolitico, molto complesso, tende a superare le capacità
dei singoli sviluppatori di comprenderlo interamente. Anche se
la struttura object oriented contribuisce (soprattutto attraverso
l'incapsulazione) a semplificare la comprensione del sistema,
è comunque molto più semplice raggiungere un buon
grado di comprensione di un programma quasi-autonomo che di una
piccola parte di un software complesso sviluppato in un unico
task.
Ricordando uno dei capisaldi della progettazione,
ovvero la stratificazione (puntata 8), possiamo osservare
che un buon design di un sistema multi-tasking è spesso
a sua volta stratificato, con task di "basso livello"
che eseguono compiti di back-end, come la lettura dei dati, la
stampa, il backup, e task via via più vicini alla visione
esterna del sistema. Comunque, di rado si va oltre i due o tre
strati di tasking.
protezione della memoria: per quanto ci si sforzi di rendere robusti i propri programmi, questi tenderanno comunque a contenere degli errori; ciò è sempre più probabile a mano a mano che le dimensioni del software aumentano. In una applicazione monotask (sia single-threaded che multi-threaded) un errore a run-time può compromettere l'integrità del task stesso, che viene così terminato. D'altra parte, task diversi hanno spazi di indirizzamento separati, e di norma gli errori non si propagano tra i task (a meno di carenze del sistema operativo); pertanto, la suddivisione in più task può essere un buon metodo per proteggere alcune parti critiche (ad esempio, la lettura e lo storage dei dati) da altre meno critiche, ma più interattive, complesse, o soggette ad errori run-time. In questo modo, ci si garantisce che i compiti fondamentali del sistema non vengano interrotti da errori nei moduli secondari del sistema stesso.
scalabilità: si tratta di un attributo molto importante in alcune classi di sistemi, che tuttavia non deriva in modo immediato da una struttura multi-threaded o multi-tasked. Con scalabilità intendiamo la capacità del sistema di sostenere carichi aggiuntivi di lavoro tramite il potenziamento delle risorse; un programma multi-tasked è potenzialmente scalabile su una architettura multi-processore, tuttavia è necessario valutare in modo accurato le esigenze di comunicazione tra i task, per evitare che l'overhead di comunicazione superi il guadagno sui tempi di calcolo. È spesso necessario fare riferimento a specifiche topologie di collegamento e comunicazione dei processori, nonché a diversi altri fattori, per poter determinare il range di scalabilità di un algoritmo o di un intero sistema.
overhead di design: un buon programma multi-tasked o multi-threaded è significativamente più complesso da progettare di uno single-tasked e single-threaded; nel caso del multi-threading, può essere anche più complesso da implementare. I fattori che contribuiscono ad aumentare lo sforzo sono diversi, ma principalmente possiamo identificare i seguenti: la necessità di definire un buon protocollo di comunicazione inter-task, e le problematiche di sincronizzazione per task e thread. Infatti, per ottenere i pieni vantaggi della suddivisione in task, è necessario definire un protocollo ad alto livello, flessibile e facilmente estendibile e comprensibile; per la comunicazione fra thread, può bastare il meccanismo di dispatching del linguaggio utilizzato. Ciò significa che un buon sistema multi-tasking richiede più tempo di progetto di uno mono-task. Analogamente, avere molti thread che competono per l'acquisizione delle stesse risorse (ad esempio, più thread che eseguono I/O) implica un dettagliato progetto della sincronizzazione, aumentando così il tempo di design. Questo fattore va accuratamente vagliato al momento delle stime dei tempi di sviluppo.
granularità: sui diversi sistemi, esiste una granularità ideale per task e thread. Spesso, un task coincide con l'idea di un "sottosistema ampio" dell'applicazione, ed un thread con un singolo oggetto o metodo. Tuttavia, tenete sempre presenti i limiti e le particolarità del sistema su cui lavorate: vi sono sistemi multitasking che degradano fortemente dopo soli 5-6 task attivi, ed altri che ne possono reggere centinaia. Lo stesso dicasi dei thread: talvolta, una migliore progettazione event-driven dell'applicazione permette di avere un throughput maggiore rispetto ad un approccio basato sul multithreading.
dipendenze dal sistema:
non è semplice progettare un sistema multitasking che operi
al meglio su diverse piattaforme. Oltre alle considerazioni precedenti,
la piattaforma influenza direttamente anche le forme di comunicazione
e sincronizzazione privilegiate. Ad esempio, in alcuni casi la
comunicazione più rapida avviene attraverso il message-passing
esplicito, in altri casi attraverso la memoria condivisa. Anche
se esistono linguaggi che permettono di lavorare ad un più
alto livello di astrazione, è probabile che sia il progettista
che il programmatore si scontrino con scelte di questo tipo: ogni
volta che sia possibile, utilizzate il meccanismo di incapsulazione
per nascondere le assunzioni su una particolare piattaforma all'interno
di un insieme di classi, che offrano invece una visione più
astratta del processo di comunicazione.
Analogamente, la sincronizzazione tra thread
può essere profondamente influenzata dall'architettura
sottostante. Di norma è opportuno che i thread si sospendano
in attesa di essere risvegliati al verificarsi delle condizioni
di sincronizzazione; in alcuni casi, tuttavia, potrebbe essere
addirittura meglio attendere all'interno di un idle-loop. Nuovamente,
incapsulate questi dettagli ogni volta che sia possibile farlo.
librerie di sistema: occorre prestare grande attenzione nell'uso del multi-threading se vengono utilizzare librerie di sistema o di terze parti, in quanto vi è la possibilità (se non sono di recente sviluppo) che queste non siano thread-safe; un esempio molto semplice può essere la funzione printf del C: se la sua implementazione non è thread-safe, il buffer statico interno può essere sovrascritto da una seconda invocazione prima che la precedente sia terminata. Di norma, è possibile comunque ricavare delle primitive thread-safe interponendo delle funzioni sincrone basate su semafori, o in alcuni casi sostituendo la funzione con una classe che gestisca una coda di richieste; si tratta comunque di un problema molto serio, da tenere in opportuna considerazione prima di definire una struttura del sistema multi-threaded.
Quale tipo di Task?
Anche se dal punto di vista del sistema operativo
possiamo avere un solo tipo di task, è spesso utile usare
una classificazione più fine: ciò aiuta la comprensione
del sistema e permette di valutare al meglio l'impatto che avrà
l'introduzione di nuovi task all'interno di esso.
Tra le caratteristiche che possiamo associare
ad un task abbiamo:
Attivazione: il task può essere attivato da eventi interni (generati da altri task), da eventi esterni (interazione con l'utente, dispositivi di input) o dal timer di sistema. In funzione del modello di attivazione, siamo interessati ad informazioni di tipo diverso (quali task possono attivarlo se è ad attivazione interna, i requisiti di timing se è attivato dal timer, e così via).
Priorità: su molti sistemi, i task sono gestiti secondo una politica di scheduling basata sulla priorità degli stessi. È molto importante assegnare la giusta priorità ai diversi task, pena un degrado delle prestazioni dell'intero sistema.
Comunicazione: un task può comunicare con altri attraverso la memoria condivisa, message passing esplicito, monitor, mailbox, semafori; in genere, sarebbe opportuno limitare il numero di metodi di comunicazione utilizzati, e possibilmente utilizzarne uno solo all'interno di un task, o alternativamente utilizzarne due, come il message passing esplicito per le comunicazioni "leggere" e la memoria condivisa per gli interscambi "intensivi" di dati. La coerenza concettuale del sistema aiuta la comprensione ed è spesso un indice di buona estendibilità.
Specifica del sistema
Come possiamo definire la struttura concorrente
del nostro design? Vi sono diverse opzioni, e la scelta è
influenzata dalla metodologia di sviluppo utilizzata, dal grado
di formalismo prescelto, dal tipo di linguaggio target.
Una possibilità è quella di rappresentare
i task ed i thread direttamente nel diagramma delle classi, facendo
derivare gli oggetti attivi, che corrispondono ad un task o ad
un thread, da una classe Task o Thread. Tuttavia, tranne in casi
estremamente semplici, questa tecnica non è sufficiente:
quali oggetti appartengono allo stesso task? Quali metodi di un
oggetto creano un nuovo thread? Queste informazioni non sono immediatamente
discernibili dal diagramma delle classi.
Una alternativa è ricorrere ad una tabella,
dove riportare (per ogni task/thread):
- il nome del task, cui fare riferimento ad es. per le sincronizzazioni
- una descrizione ad alto livello del compito svolto
- gli oggetti istanziati ed i metodi chiamati
- la priorità, gli eventuali requisiti di timing
- una descrizione della logica di sincronizzazione
- una descrizione delle comunicazioni con altri task
Osserviamo che tale descrizione non è
specializzata per il paradigma object-oriented, ed in effetti
questo può essere un vantaggio se diversi task sono scritti
in linguaggi diversi; il difetto maggiore è che si tratta
di una descrizione molto prolissa ed informale, in cui è
facile trascurare dei dettagli.
Un'ulteriore possibilità è quella
di usare un linguaggio per la specifica dei sistemi concorrenti
(come il CSP o il CCS cui ho accennato nella puntata 8), o addirittura
il linguaggio target, quando questo sia sufficientemente espressivo.
Ad esempio, proprio al fine di permettere la specifica e l'implementazione
dei sistemi concorrenti rimanendo nel paradigma orientato agli
oggetti, sono state definite delle estensioni di linguaggi come
il C++ [4] [5], ed anche Ada 9x può essere utilizzato come
linguaggio di specifica.
Possiamo a questo proposito vedere un semplice
esempio di programma in Real-Time-C++ [6], una estensione del
C++ per la scrittura di applicazioni di real-time; l'RTC++ arricchisce
il linguaggio con nuove parole chiave, specializzate per il suo
dominio di applicazione, tra cui:
Le nuove keyword mettono a disposizione una
maggiore espressività, tanto da poter spesso utilizzare
il linguaggio anche per la specifica del sistema; il seguente
listato illustra l'utilizzo delle nuove parole chiave:
active class C
{
public:
int m( char* data, int size )
bound( 0t30m )
// massimo periodo di
// esecuzione 30 msec
timeout( C_abort ) ;
// se avviene un timeout
// viene chiamato il gestore
// di eccezione C_abort
activity:
slave m( char*, int ) ;
// dedica un thread separato
// all'esecuzione del metodo m
} ;
active class Main
{
activity :
master main()
// thread principale
cycle( 0; 0; 0t200; 0t200 ) ;
// nessun tempo di inizio
// nessun tempo di fine,
// periodo 200 msec
// deadline 200 msec
} ;
Anche se utilizziamo un linguaggio formale, è comunque importante avere a disposizione una rappresentazione più immediata, sotto forma di tabella o grafico, delle attività che vengono svolte da ogni task e di quali task sono attivi nelle diverse fasi di elaborazione; quest'ultima informazione viene spesso rappresentata tramite un diagramma degli stati (vedere puntata 8), in cui ai singoli oggetti viene sostituito l'intero task o thread, ed un diagramma degli eventi (sempre puntata 8) cui ad ogni oggetto viene sostituito l'intero task o thread. In tal modo, abbiamo a disposizione sia una specifica più formale, utilizzabile anche in fase di codifica, sia una visione di più alto livello dell'intero sistema.
Verifica dei Timing:
In applicazioni real-time, e dovunque esistano
requisiti sui tempi massimi di esecuzione di un processo di calcolo,
è necessario imporre vincoli precisi sulla durata dei singoli
metodi coinvolti nel processo stesso: un esempio è stato
dato nella puntata 8, dove il diagramma degli eventi veniva utilizzato
anche per fornire una specifica dei tempi massimi di esecuzione.
Tuttavia, il diagramma degli eventi non è
direttamente correlato all'insieme dei metodi che vengono eseguiti
in risposta all'evento stesso, poiché questi non sono noti
sino ad una fase di design dettagliato o di codifica; pertanto,
ci si trova spesso nella situazione di dover specificare dei tempi
massimi di esecuzione per ogni metodo (o insieme di metodi) al
momento del design, e di poterne valutare la consistenza solo
durante o dopo la codifica. Ovviamente, le restrizioni documentate
durante il design devono guidare la codifica, ma altrettanto
ovviamente, ogni fase dello sviluppo può introdurre degli
errori; pertanto, è sempre opportuno verificare che le
temporizzazioni richieste vengano soddisfatte dalla particolare
implementazione.
Il metodo più semplice per verificare
il rispetto dei timing è il seguente:
- per ogni classe c, indichiamo con Sm(c) l'insieme dei suoi metodi
- per ogni metodo m della classe c, indichiamo con C(m,c) il tempo massimo di esecuzione (non contando il tempo di idle) del metodo stesso. Se non esistono restrizioni, assumiamo un valore infinito.
- per ogni metodo m della classe c, indichiamo con Ms(m,c) il multiset (ovvero l'insieme con ripetizioni) dei metodi chiamati dal metodo m.
Con le precedenti assunzioni, dobbiamo allora
verificare che il tempo massimo di esecuzione specificato per
un metodo non sia inferiore alla somma dei tempi massimi di esecuzione
per tutti i metodi chiamati; viceversa, l'implementazione del
metodo potrebbe violare i requisiti di design. Questo vincolo
è facilmente espresso come segue:
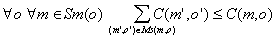
Osserviamo che, proprio per la semplicità
della tecnica, alcuni casi non possono essere trattati adeguatamente,
ad esempio i metodi ricorsivi: in questo caso è necessario
considerare anche il valore dei parametri all'interno della definizione
di C, e dimostrare (normalmente per induzione) che i requisiti
di timing vengano rispettati.
Note architetturali
In alcuni casi, la logica di sincronizzazione
per i diversi thread o task non appartiene a nessuna delle classi
coinvolte, ma è solo motivata da una particolare politica
di gestione del sistema. Se ricordate le considerazioni relative
alle relazioni tra oggetti (puntata precedente), potrete notare
la stretta analogia: inserire la logica di sincronizzazione all'interno
delle classi riduce il potenziale riutilizzo in un diverso sistema,
esattamente come inserire le relazioni come membri delle classi
riduce la riusabilità delle stesse. Ciò non dovrebbe
stupire, se consideriamo che la sincronizzazione è un accoppiamento
tra le classi, e che l'accoppiamento riduce la possibilità
di riuso.
A questo proposito, esistono in effetti due
soluzioni, profondamente differenti nell'implementazione:
1) Da ogni classe, priva della logica di sincronizzazione, derivare una classe che implementi tale logica per la specifica applicazione; le classi base possono allora divenire astratte (ovvero non istanziabili) qualora la sincronizzazione giochi un ruolo vitale nell'economia della classe.
2) Spostare la logica di sincronizzazione per tutti gli oggetti coinvolti all'interno di una classe separata, normalmente detta Classe di Controllo o semplicemente Coordinatore. In alcuni casi, il coordinatore può essere un task separato, a cui le varie classi faranno riferimento quando è richiesta una azione di sincronizzazione (notare l'analogia strutturale con l'architettura basata su integratore, vista nella puntata 7).
Entrambe le soluzioni hanno pregi e difetti;
ad esempio, spesso è difficile concentrare tutta la logica
di controllo in un'unica classe, che soffre degli stessi problemi
di scalabilità dell'integratore; per contro, si ha il vantaggio
di avere in un'unico punto tutto il controllo, con conseguente
semplicità di manutenzione e modifica. Aggiungere una classe
specializzata per ogni classe coinvolta nella sincronizzazione
può essere tedioso, ma d'altra parte si risparmia un task
(il che, in certi sistemi, è un vantaggio non indifferente).
Come sempre, non esiste la soluzione magica
a tutti i problemi; le diverse alternative vanno valutate sulla
singola istanza, e la soluzione più adeguata deve spesso
tenere conto delle possibili evoluzioni del sistema, e mediare
tra necessità presenti e future.
Classi Task e Classi Thread
A livello di design dettagliato, ha senso chiedersi
se debbano esistere una classe "Task" ed una classe
Thread, ad esempio come classi astratte da cui derivare le classi
concrete che implementano un task o un thread.
In effetti la questione non è banale
come può sembrare: innanzitutto, un task corrisponde spesso
ad una attività complessa, che coinvolge molti oggetti,
ed un thread è invece spesso creato sulla base di un singolo
metodo - non di un intero oggetto. Sembra quindi che esista un
problema di impedenza tra oggetti, task e thread, ovvero che il
task comprenda molti oggetti ed un oggetto molti thread, e che
non sia quindi così naturale definire una classe task ed
una classe thread.
Anche in questo caso, non esiste la scelta
migliore in assoluto; se un thread ha una dignità di classe,
è sicuramente vantaggioso avere una classe thread da cui
derivarlo, in quanto ci consentirà di incapsulare i dati
locali al thread e di averne una visione astratta; d'altra parte,
se un metodo deve essere forzato in una classe solo per giustificare
la presenza di una classe thread, è probabilmente meglio
utilizzare direttamente le primitive del sistema operativo.
Lo stesso dicasi per il task: se il protocollo
di comunicazione prevede uno scambio di dati tra una applicazione
ed un'altra tramite messaggi, ha spesso molto senso avere una
classe task, che si occupa dello smistamento dei messaggi stessi,
e probabilmente di altre attività connesse. L'errore peggiore
che si possa commettere è di definire una classe Task per
scopi implementativi, ovvero con il solo fine di inserirvi un
ampio insieme di variabili, rese accessibili ad ogni oggetto dell'applicazione;
per quanto possa sembrare un miglioramento rispetto all'uso delle
variabili globali, questa struttura tende a far degenerare piuttosto
rapidamente l'incapsulazione: diventa troppo semplice aggiungere
un nuovo membro alla classe task, con l'illusione di seguire comunque
i canoni della programmazione ad oggetti.
Infine, occorre tenere presenti i dettagli
delle singole soluzioni: alcune librerie per la programmazione
multi-threading in ambiente mono-task richiedono che ogni thread
sia un oggetto, per poter gestire opportunamente lo scheduling
dei thread stessi; naturalmente, in questi casi ha ben poco senso
perdersi in disquisizioni sulla necessità o meno di modellare
un thread come classe, dal momento che la libreria lo impone.
Molti framework commerciali per lo sviluppo di applicazioni hanno
infine una classe "Application", che ha forti analogie
con una classe Task, per quanto raramente vi siano primitive di
comunicazione inter-task all'interno delle classi Application;
è quindi possibile che dobbiate potenziare il framework
a vostra disposizione, nel qual caso un linguaggio che consenta
l'ereditarietà multipla è spesso il più indicato,
a meno che non vogliate intervenire sul sorgente del framework
stesso, o rinunciare parzialmente al riuso del codice tra applicazioni
diverse.
Conclusioni
Anche "Lezioni di Object Oriented Technology"
si avvicina alla sua conclusione: nella prossima ed ultima puntata
parleremo del componente di interazione con l'utente, e di alcuni
possibili percorsi di approfondimento dopo questo ciclo di introduzione
al paradigma orientato agli oggetti.
Bibliografia
[1] M. Ben-Ari: "Principi di programmazione
concorrente e distribuita", Prentice-Hall/Jackson, 1992.
[2] C.A.R. Hoare: "Monitors: an operating system structuring
concept", Communication of ACM, ottobre 1974.
[3] William Douglas Clinger: "Foundations of Actor Semantics",
MIT AI Lab Technical Report, 1981.
[4] Jacov Seizovic: "Introduction to C+-", Caltech Computer
Science Technical Report, 1993.
[5] Andrew Grimshaw: "Easy-to-Use Object-Oriented Parallel
Processing with Mentat", IEEE Computer, Maggio 1993.
[6] Ishikawa, Tokuda, Mercer: "An Object-Oriented Real-Time
Programming Language", IEEE Computer, Ottobre 1992.
[7] Dan Ford: "Event-Driven Threads in C++", Dr Dobb's
Journal, Giugno 1995.
Biografia
Carlo Pescio (pescio@acm.org) svolge attivitŕ di consulenza in ambito internazionale nel campo
delle tecnologie Object Oriented. Ha svolto la funzione di Software Architect in grandi progetti per
importanti aziende europee e statunitensi. Č incaricato della valutazione dei progetti dal
Direttorato Generale della Comunitŕ Europea come Esperto nei settori di Telematica e Biomedicina.
Č laureato in Scienze dell'Informazione ed č membro dell'ACM, dell'IEEE e della New York Academy
of Sciences.