Design: Dominio del Problema e della Soluzione
|
|
Dr. Carlo Pescio Design: Dominio del Problema e della Soluzione |
Pubblicato su Computer Programming No. 41
Completiamo il design del dominio del problema, raffinando i
dettagli della struttura statica e definendo la struttura dinamica del
modello
Introduzione
Nel numero di settembre, prima della digressione della precedente puntata,
abbiamo identificato le componenti essenziali di un modello OO come segue:
Nel presente articolo ci occuperemo del dominio del problema, nell'ottica
del design, e discuteremo gli obiettivi della definizione della struttura
statica e dinamica del modello, nonché alcuni principi di architettura
dei sistemi.
Struttura statica
Il dominio del problema č stato in gran parte identificato durante il
processo di analisi, che ha evidenziato le classi rilevanti ai fini del
modello, le relazioni tra esse esistenti, gli scambi dei messaggi, e cosě
via. Perché dunque riconsiderarlo a proposito del design? Ricordiamo che
attraverso l'analisi abbiamo stabilito cosa debba fare il sistema;
č ora importante definire, all'interno del dominio del problema, come
tali compiti verranno svolti. Ciň comporterŕ, come vedremo, l'estensione
o la parziale revisione delle gerarchie di classi coinvolte, in quanto
dovremo necessariamente introdurre nuovi elementi appartenenti al dominio
della soluzione (o piů esattamente, di una possibile soluzione tra
le molteplici scelte possibili).
Passare da una descrizione del problema ad una definizione della soluzione,
nell'ambito di un modello object oriented, comporta i seguenti passi:
Vediamo ora nell'ordine i vari passi, iniziando dalla definizione degli algoritmi. Indipendentemente dal paradigma utilizzato, la soluzione di un problema comporta sempre la ricerca e l'utilizzo di un appropriato processo di calcolo o di manipolazione dell'informazione, ovvero un opportuno algoritmo. La formulazione concreta dell'algoritmo puň essere diversa, in funzione del paradigma ed anche delle potenzialitŕ del linguaggio target, ma una formulazione astratta dell'algoritmo stesso prescinde in gran parte dal formalismo utilizzato: quicksort resta comunque quicksort, sia esso realizzato attraverso una funzione che opera su array, da un predicato in programmazione logica, o con l'ausilio di una gerarchia di classi aventi una funzione virtuale per il calcolo del minore tra due elementi.
La conoscenza degli algoritmi e delle principali strutture dati (alberi, grafi, hash table, e cosě via) deve far parte del bagaglio culturale di ogni programmatore o progettista: naturalmente, conoscere una formulazione nell'ambito del paradigma object oriented puň essere piů vantaggioso, ma č spesso sufficiente una buona conoscenza anche di una formulazione "classica", basata su abstract data types o su una visione funzionale. Scegliere un algoritmo puň essere banale in alcuni casi, mentre puň diventare un vero e proprio progetto di ricerca, con lo studio e la definizione di nuovi procedimenti, qualora le esigenze siano particolarmente ardue da soddisfare; in ogni caso, avere a disposizione alcuni testi di base sugli algoritmi, come [1], [2] o [3] č una esigenza fondamentale per chiunque sia impegnato in progetti non banali.
Ricordiamo che la scelta di un algoritmo dipende sia da ragioni tecnologiche
che dalla singola applicazione. Le "ragioni tecnologiche" includono
ad esempio l'architettura hardware a disposizione: per citare un esempio
molto banale, spesso occorre decidere se un dato vada memorizzato o ricalcolato
ogni volta; il giusto trade-off non puň (in generale) essere scelto in
modo ottimale indipendentemente dalla piattaforma target. D'altra parte,
č l'applicazione stessa che determina la frequenza delle singole operazioni:
ciň che potrebbe essere conveniente con una determinata distribuzione della
frequenza delle operazioni, puň non esserlo con un'altra. Un albero perfettamente
bilanciato puň avere senso se le operazioni di ricerca sono molto piů frequenti
di quelle di inserimento/cancellazione, ma non viceversa.
Quando definiamo o comunque decidiamo l'utilizzo di un determinato algoritmo,
facciamo spesso riferimento a strutture dati (ovvero, nel nostro contesto
di OOD, a classi) ben note e presenti in quasi ogni programma: liste, alberi,
tabelle, matrici, eccetera. Queste classi "base", che infatti
sono spesso contenute nelle librerie di base dei linguaggi, formano le
cosiddette classi di infrastruttura; notiamo che in alcuni casi
sarŕ necessario arrivare comunque al design dettagliato di classi di infrastruttura,
o fare riferimento ad una particolare implementazione: se la cancellazione
di elementi random di una lista č un'operazione frequente, un'implementazione
della lista con doppi puntatori sarŕ piů indicata di una con singoli puntatori.
In molti casi, tuttavia, possiamo introdurre nel dominio della soluzione
le necessarie classi di infrastruttura senza preoccuparci eccessivamente
dell'implementazione, ma definendo semplicemente opportuni vincoli che
verranno poi passati al programmatore. Ad esempio, potremmo richiedere
che la cancellazione di un elemento avvenga in un tempo costante, o per
essere piů precisi abbia complessitŕ computazionale O(1 ).
Oltre a queste classi "generiche", la nostra particolare soluzione potrŕ richiedere anche la definizione di nuove classi, non facenti parti a priori del dominio del problema, e che sono specializzate per la soluzione identificata. Riprendendo per un istante gli esempi visti nella precedente puntata, la classe "integratore" nell'approccio relativo non appartiene ovviamente all'infrastruttura (č infatti molto specializzata) e neppure al dominio del problema.
Notiamo che talvolta le classi specializzate sono ottenute partizionando
elementi presenti nella visione piů astratta fornita dall'analisi: un esempio
č stato dato, sempre nella scorsa puntata, nell'approccio basato su advise-sink,
dove sono state introdotte classi ausiliarie per rappresentare i dati associati
ad una modifica dello stato, che in fase di analisi era semplicemente rappresentata
come uno scambio di messaggi.
Tra le classi specializzate, un ruolo particolare č spesso riconosciuto
alle cosiddette classi di controllo, che interfacciano l'applicazione
con il mondo esterno, inteso sia come sistemi di I/O che come interfaccia
utente. Come giŕ accennato, nel paradigma model/view/controller, i "dati"
dell'applicazione e l'interfaccia utente non sono direttamente collegati,
ma l'interazione passa attraverso classi intermedie (controller); questo
approccio ha il vantaggio di diminuire l'accoppiamento con l'interfaccia
utente, al prezzo di una codifica piů complessa. Per questa ragione, molti
framework commerciali si basano su un paradigma model/view (con controller
fissato o embedded), piuttosto che sul model/view/controller.
Specificare le classi
Tutte le classi di cui sopra verranno aggiunte al nostro modello object oriented, arricchendo di conseguenza il risultato dell'analisi; il design non si ferma naturalmente qui, in quanto č ora necessario scendere nel dettaglio di ogni singola classe e definire gli elementi lasciati in sospeso durante la fase di analisi o i passi precedenti.
In particolare, il risultato finale del design deve comprendere:
Vale la pena di insistere sull'importanza di specificare i metodi che
non alterano lo stato dell'oggetto (normalmente detti const dalla
keyword utilizzata in C++) ed i metodi virtuali. Si tratta infatti di una
informazione estremamente importante dal punto di vista della completezza
del modello; notiamo che in alcuni linguaggi tutti i metodi sono
virtuali1 ed č quindi importante
specificare le assunzioni fatte al momento del design, in quanto potrebbe
essere necessario ricorrere ad un renaming in fase di codifica.
Infine, ricordiamo che il livello di dettaglio a cui potete arrivare
in fase di design č spesso arbitrario: in molti casi, una definizione dell'interfaccia
pubblica e una visione ad alto livello degli algoritmi sarŕ piů che sufficiente,
salvo i casi piů complessi in cui č necessario definire in modo piů preciso
le strutture dati coinvolte e formulare un algoritmo con maggiore precisione.
Come sempre, č difficile dire "quando fermarsi", poiché dipende
molto dall'organizzazione: se chi esegue il design č anche incaricato di
implementare il codice relativo, puň trovare utile lasciare il design dettagliato
ad un livello piuttosto astratto, e passare all'implementazione. D'altra
parte, se il design e l'implementazione vengono eseguiti in tempi e/o da
persone differenti, non di rado č necessario fornire maggiori informazioni
in fase di progettazione, onde evitare errate interpretazioni. Non č insolito
che, nel caso del singolo sviluppatore incaricato di un progetto, il design
e l'implementazione si fondano in un processo unico, in cui č difficile
identificare dove termini uno e cominci l'altro; ciň non costituisce in
sé un problema, ammesso che esistano comunque dei "documenti di design"
cui fare riferimento, e non si debba invece estrarre e ricostruire tutta
la conoscenza dal codice. Molte scelte, non solo di livello architetturale,
ma anche riferite alle singole decisioni a livello di strutture utilizzate,
sono difficili o impossibili da ricostruire dal codice: non č quindi raro
che decisioni iniziali, mai documentate, vengano implicitamente mantenute
in future versioni, anche a fronte di modifiche dei requisiti, semplicemente
perché nessuno ne ricorda le motivazioni. Se le frequenze delle operazioni
cambiano, ad esempio, potrebbe avere senso riconsiderare le strutture dati
coinvolte: non di rado, tutttavia, non esiste traccia di come esse siano
state scelte nella prima implementazione. Se nel vostro processo di sviluppo
vi č poco spazio per il design, cercate almeno di motivare le scelte eseguite
come guida per chi dovrŕ comprendere e modificare in seguito il vostro
codice.
Stratificazione
Prima di proseguire con la descrizione della struttura dinamica del
modello, vorrei riportare l'attenzione su un fattore architetturale molto
importante, che non ha trovato un giusto spazio nelle puntate precedenti.
Si tratta infatti di un criterio semplice ma fondamentale per la corretta
strutturazione di un sistema.
Una delle caratteristiche di un buon design č infatti quella di separare elementi posti a diversi livelli di astrazione; questa caratteristica viene comunemente indicata come stratificazione, intendendo cosě che ogni sottosistema puň essere visto come un insieme di strati, di livello sempre piů astratto, ognuno dei quali utilizza, almeno in linea di principio, solo i servizi dello strato sottostante.
Un esempio ben noto di architettura stratificata, indicata in questo caso anche come "a cipolla", č quella di molti sistemi operativi: al piů basso livello di astrazione abbiamo l'hardware, al piů alto le applicazioni, ed in mezzo diversi strati che isolano dai dettagli dei livelli sottostanti: gestione dei task, della memoria, del file system, e cosě via.
La stratificazione mira a ridurre le dipendenze tra gli elementi del
sistema, e quindi il fenomeno delle modifiche a cascata; notiamo la differenza
tra stratificazione ed incapsulazione: in un sistema object oriented, l'incapsulazione
nasconde i dettagli implementativi della classe, mentre la stratificazione
riduce gli accoppiamenti sui messaggi. L'incapsulazione in sé non č sufficiente
a proteggere dalle modifiche a cascata, poiché modifiche all'interfaccia
di una classe (che possono comunque avvenire) richiedono necessariamente
un adattamento nelle classi client. L'interposizione di diversi livelli
di astrazione dovrebbe, se ben strutturata, smorzare la propagazione delle
modifiche verso i livelli successivi.
Come si applica il concetto di stratificazione a livello di design object oriented? In gran parte, osservando le connessioni di messaggio, a livello delle categorie di classi, ed all'interno di queste al livello dei singoli oggetti. Da tali connessioni possiamo determinare un grafo diretto, dove due nodi (classi o categorie di classi) sono connessi se e solo se esiste una connessione di messaggio tra un oggetto di una classe (o categoria di classi) e l'altra. Possiamo ora definire un sistema come stratificato se nel grafo delle connessioni associato č possibile assegnare un livello ad ogni classe, tale che tutte le classi di livello n siano connesse solo con classi di livello n-1. In realtŕ, raggiungere un tale livello di stratificazione č in genere arduo, a meno di non introdurre artificiosamente delle classi cuscinetto. In genere, č piů che accettabile se le classi di livello n sono connesse solo a classi di livello inferiore, ma non necessariamente n-1.
Notiamo che questa visione della stratificazione ha il pregio di essere
semi-formale, ma ha il difetto di non attribuire alcun significato agli
strati: una classe "scheduler", una classe "lista"
ed una classe "persona" potrebbero essere poste all'interno dello
stesso strato. Tuttavia, una visione piů completa, ma difficilmente formalizzabile,
imporrebbe di avere all'interno dello stesso strato solo classi in qualche
modo omogenee dal punto di vista concettuale. Solo in tal modo l'architettura
del sistema porterŕ i benefici di maneggevolezza concettuale e di futura
espandibilitŕ e mantenibilitŕ che vogliamo perseguire.
Va detto che non č semplice ottenere un modello stratificato di un sistema
complesso, neppure riferendosi alla versione piů debole di stratificazione;
in alcuni casi, la complessitŕ del sistema supera ogni tentativo di imbrigliarla
in una struttura gerarchica. Considerando ad esempio le varianti architetturali
viste nella puntata precedente, un sistema che richieda l'uso degli advise
sink sarŕ spesso non-stratificato, con connessioni complesse e dinamiche.
Sarŕ anche piů complesso da comprendere nella sua interezza e da modificare,
ma anche le migliori tecniche di ingegneria del software non possono ridurre
la complessitŕ dei sistemi al di sotto dei limiti fisiologici propri dei
sistemi stessi. Tuttavia, quando introducete nuove classi in un sistema,
come parte della attivitŕ di design, dovreste sempre cercare di identificarne
lo "strato" di appartenenza e di verificare che, nei limiti del
possibile, il design stesso non stia esplodendo verso una connettivitŕ
combinatoria dei diversi elementi.
Struttura dinamica
Una volta definite le interfacce delle classi ad un adeguato livello
di dettaglio, il che puň includere la definizione delle strutture dati
e degli algoritmi fondamentali che dovranno svolgere i compiti relativi,
abbiamo terminato il progetto della parte statica del sistema. Ovviamente
vi saranno in seguito dei raffinamenti, in quanto il processo di sviluppo
č per natura iterativo, ed č spesso necessario riconsiderare alcune scelte
mentre il sistema evolve.
D'altra parte, la definizione statica del sistema non č sufficiente
a caratterizzare il comportamento del sistema stesso: essa si concentra
troppo sulla singola classe, con un'enfasi particolare sulla visione esterna
della classe stessa, e non pone nel giusto rilievo le interazioni tra le
classi e gli eventuali vincoli temporali che esse comportano. Inoltre,
talvolta un oggetto puň trovarsi in diversi stati ben determinati,
che influenzano in modo molto forte il suo comportamento. In genere, č
difficile comprendere le transizioni di stato da una descrizione statica
del sistema, anche se con un adeguato livello di dettaglio č spesso possibile.
Si ricorre pertanto a descrizioni piů espressive, sia per le interazioni
tra oggetti che per la rappresentazione degli stati di un oggetto: queste
fanno parte del dominio della cosiddetta struttura dinamica del
sistema, che tuttavia non si limita a questo. Una parte della struttura
dinamica č rappresentata dalla gestione dei task, che vedremo in una puntata
futura.
Diagramma degli stati
Ad ogni istante, un oggetto si trova in uno stato ben determinato, definito dal valore delle sue variabili di istanza. In alcuni casi, il comportamento dell'oggetto dipende pesantemente dallo stato in cui si trova, o da alcune delle sue componenti. Ad esempio, un telefono si comporta in modo molto diverso se la cornetta č alzata o abbassata; per contro, alcune variabili di istanza influenzano il risultato delle operazioni, ma non il comportamento: il colore influenza il risultato di un metodo Plot() di una classe Linea, ma non ne influenza il comportamento, che č sempre quello di tracciare una linea. Notiamo che la distinzione tra risultato e comportamento puň essere molto sottile in alcuni casi, e dipende strettamente da come vengono definiti l'uno e l'altro. Nel contesto dell'articolo, lasceremo la distinzione ad un livello piuttosto intuitivo ed informale; chi desideri maggiori dettagli, puň consultare [6].
Quando un oggetto si comporta in modo molto diverso in funzione del
suo stato, lo stato diventa un elemento molto rilevante per comprendere
il funzionamento dell'oggetto, ed č in genere importante documentare in
modo preciso come avvengono le transizioni di stato, e quali conseguenze
tali transizioni abbiano sull'oggetto stesso e sul mondo esterno.
In tal caso si utilizza in genere un diagramma degli stati, ovvero un grafo diretto dove i nodi rappresentano gli stati e gli archi le possibili transizioni tra gli stati. Gli archi sono in genere etichettati per rappresentare lo stimolo che scatena la transizione (proveniente in genere dal mondo esterno, anche se talvolta ha senso considerare eventi interni al sistema).
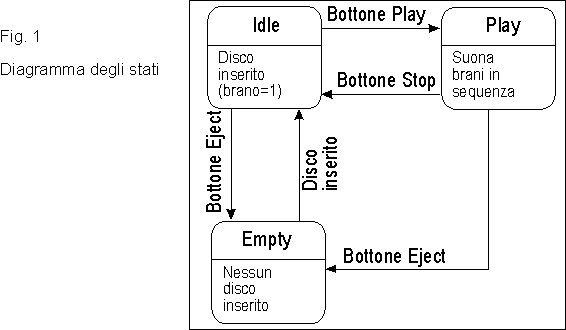
Un semplice esempio di diagramma degli stati č dato in figura 1, dove
viene rappresentata una versione molto semplificata di un lettore di compact
disc, con tre stati significativi (vuoto, disco inserito, play), e le relative
transizioni. Notiamo che ad ogni stato č associato un nome ed eventualmente
i valori o i range che alcune variabili di istanza devono assumere. Č sempre
bene verificare che gli stati siano (un sottoinsieme di) una precondizione
di una operazione, e che siano una postcondizione di un'altra; uno stato
puň anche essere definito attraverso un'espressione invariante che lo caratterizza.
Un buon esercizio potrebbe essere il completamento del modello, per
tenere conto di funzionalitŕ piů estese del lettore, oppure (ad esempio)
la definizione di un diagramma degli stati di una macchinetta distributrice
di bevande: i modelli piů sofisticati, con tanto di display e tastierino,
hanno un diagramma abbastanza complesso da essere interessante ma comunque
sufficientemente semplice da costituire un breve esercizio.
Vale la pena di insistere sul fatto che un diagramma degli stati modella un oggetto e le sue transizioni; gli altri oggetti non sono presenti nel diagramma, se non implicitamente come sorgente degli stimoli. Vedremo tra breve come rappresentare invece le interazioni tra oggetti.
In ogni caso, di norma non modelleremo tutti gli oggetti attraverso
un diagramma degli stati; solo i componenti che interagiscono con l'esterno,
o nei quali č possibile evidenziare stati significativi che risultino in
un diverso comportamento dell'oggetto nei confronti del sistema, richiedono
una specifica di questo tipo. Tornando all'esempio dell'oggetto Linea,
in genere non avremo necessitŕ di definire un diagramma degli stati; anche
se l'oggetto avesse uno stato visibile/non_visibile che influisce sul suo
comportamento, di norma una specifica informale o in pseudocodice sarŕ
sufficiente per i casi elementari. Il diagramma deve aiutare a comprendere
il funzionamento del sistema, sia in fase di progettazione e discussione
del design che in fase di implementazione o manutenzione. Non deve invece
diventare un lavoro aggiuntivo del progettista nei casi banali.
Quando un oggetto ha comportamenti significativamente diversi in funzione
dei suoi stati, puň avere senso implementare l'oggetto stesso come una
macchina a stati, o automa finito. Chi desidera approfondire questo argomento
puň consultare un buon testo di informatica generale, oppure qualche riferimento
classico, come [7]. Esistono, nel paradigma object oriented, alternative
interessanti alle macchine a stati: ad esempio, una possibilitŕ č quella
di far coincidere, a livello di implementazione, ogni stato con una classe
derivata da una virtual base class, ed utilizzare un membro di tipo puntatore
all'interno della classe che puo' assumere i diversi stati. In questo modo,
modificando il puntatore modifichiamo di fatto il comportamento della classe;
questo schema č ancora piu' adatto ai linguaggi basati su delegation, ma
č facilmente implementabile anche nei linguaggi piů comuni, attraverso
un semplice forwarding delle funzioni. Una simile implementazione č di
fatto un ottimo esempio di raffinamento del dominio del problema, attraverso
l'introduzione di classi accessorie che hanno il solo fine di ridurre la
complessitŕ concettuale del design e dell'implementazione.
Diagramma degli eventi
Il diagramma degli stati č utilizzato per specificare le transizione interne di un singolo oggetto, in risposta agli stimoli provenienti dal mondo esterno o da altri oggetti. Non rivela, tuttavia, le interazioni a livello di sistema, il parallelismo e la concorrenza del sistema stesso, né i vincoli temporali (sia come successione che come temporizzazioni).
Tali interazioni sono indubbiamente una delle parti piů complesse da
comprendere in assenza di una adeguata documentazione in fase di design:
la difficoltŕ maggiore nella comprensione di programmi object oriented
č infatti quasi sempre dovuta ad interazioni non ovvie tra gli oggetti
presenti nel sistema [8]. La presenza del parallelismo rende un diagramma
degli eventi indispensabile per una adeguata comprensione del sistema.
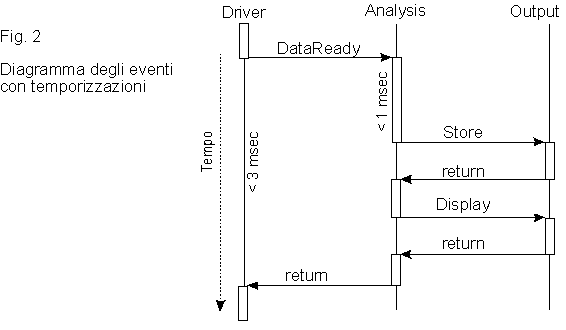
In un diagramma degli eventi (vedere fig. 2), il tempo č rappresentato sull'asse verticale, ed ogni oggetto coinvolto nello scenario in esame viene indicato con una linea verticale. Lo stato dell'oggetto ad ogni istante (attivo o bloccato) viene rappresentato dallo spessore della linea associata, o trasformando la linea in un rettangolo quando l'oggetto č attivo. Linee orizzontali sono associate agli eventi del sistema, e corrispondono normalmente a transizioni da attivo a bloccato (o viceversa) per alcuni degli oggetti coinvolti. Questa non č una condizione necessaria: esistono sistemi in cui tutti gli oggetti sono sempre attivi; si tratta comunque di un'esigua minoranza.
Nell'esempio di figura 2, possiamo vedere un sistema (molto semplificato) dove un driver legge dati da una periferica, li passa ad un oggetto che esegue alcune analisi e trasformazioni su di essi, il quale a sua volta li passa ad un ulteriore oggetto responsabile per la memorizzazione e visualizzazione. Possiamo vedere che č possiblie indicare con semplicitŕ ed immediatezza di lettura alcuni vincoli di temporizzazione, ad esempio che l'intero processo di analisi, visualizzazione e memorizzazione richieda al massimo 3 millisecondi.
Nell'esempio dato, le linee orizzontali (eventi) sono sostanzialmente
chiamate di metodi da parte degli oggetti; in altri casi potrebbero essere
eventi provenienti dal mondo esterno, nel caso non sia stato modellato
come un oggetto esso stesso. Un oggetto puň generare piů eventi allo stesso
istante, ma ricordate che non ha molto senso, sia dal punto di vista probabilistico
che implementativo, considerare la ricezione simultanea di piů eventi.
Simili problemi di sincronizzazione vanno sempre risolti utilizzando degli
appositi oggetti, come semafori, mailbox, eccetera, il cui scopo č appunto
di fornire primitive di sincronizzazione all'intero sistema.
Naturalmente, cosě come non č normalmente richiesto di rappresentare ogni possibile transizione di stato in un diagramma degli stati, non rappresenteremo ogni possibile scenario di interazione in un diagramma degli eventi: solo gli scenari piů significativi per il sistema verranno definiti e documentati graficamente. Ovviamente, la definizione di "significativo" č volutamente ambigua: nel progetto di un distributore di bevande potremo limitarci a definire le interazioni "lecite", lasciando le altre non specificate (non a caso, i distributori di bevande hanno spesso combinazioni non documentate, e piuttosto casuali), mentre in un sistema di controllo di un impianto chimico, ma anche in un bancomat, sarŕ spesso necessario documentare adeguatamente ogni possibile interazione.
Spesso, utilizziamo un diverso diagramma degli eventi per ogni "scenario"
di alto livello; un oggetto puň partecipare (in modo diverso) a piů scenari,
nel qual caso possiamo avere piů diagrammi. Attenzione in questi casi a
rendere sempre espliciti gli eventuali problemi di concorrenza e competizione
per le risorse.
In progetti con requisiti di correttezza e verificabilitŕ piů stringenti, normalmente non ci si puň limitare ad uno o piů diagrammi degli eventi, ma č necessario dare una specifica formale delle interazioni concorrenti interne al sistema.
In tal caso, si utilizzano spesso dei linguaggi per la specifica di
sistemi concorrenti, come il CSP (Communicating Sequential Processes, vedi
[9]) o il CCS (Calculus of Communicating Systems); esistono anche delle
estensioni orientate agli oggetti di tali linguaggi, cosě come tentativi
autonomi di definire formalismi analoghi nel paradigma object oriented,
che tuttavia rimangono, al momento, prevalentemente a livello di ricerca
[10].
Conclusioni
Nella prossima puntata focalizzaremo il discorso sulla gestione dei dati, dando una panoramica dei diversi metodi per la persistenza degli oggetti, ma anche recuperando quanto di meglio esiste nell'approccio relazionale.
Alcuni lettori mi hanno scritto chiedendo di trattare degli esempi completi,
dalla specifica informale all'analisi, al design architetturale e di dettaglio;
purtroppo, mentre da un lato potrebbe essere molto interessante, dall'altro
il tempo e lo spazio richiesto sarebbero ben al di lŕ delle possibilitŕ
di una serie di articoli. Posso comunque suggerire un paio di testi, facilmente
reperibili, orientati agli esempi: in [11], l'autore sviluppa un progetto
piuttosto semplice dalla fase di analisi sino al design dettagliato, pur
con poca enfasi sulla progettazione architetturale, usando il metodo di
Booch; in pratica, l'intero libro č sviluppato intorno all'esemplificazione
di un caso. In [12], l'autore propone diversi esempi di progettazione,
usando tuttavia un approccio inusuale: anziché utilizzare sin dalle prime
fasi un approccio object oriented, utilizza metodi misti di data flow analysis
e functional decomposition, recuperando quindi strumenti piů datati, e
ponendo di conseguenza l'accento su aspetti molto diversi da quelli considerati
in questa rubrica (ad esempio, viene data grande enfasi alle dipendenze
temporali sin dalla fase di analisi). Potrebbe quindi essere indicato per
chi voglia passare al paradigma object oriented, proveniendo ad esempio
da un ambiente data flow, in modo piů graduale ed incrementale, ovviamente
con le dovute cautele.
1ad esempio Smalltalk. Notiamo che anche
se alcuni confondono la programmazione OO "pura" con Smalltalk,
l'assenza di metodi non-virtuali non solo non riflette il comportamento
di alcuni oggetti nel mondo reale, ma impedisce anche di prevenire alcuni
problemi, discussi in un altro articolo su questo stesso numero.
Bibliografia
[1] D. E. Knuth: "The art of computer programming", Vol 1,
2, 3, Addison-Wesley, 1969-1981.
[2] Niklaus Wirth, "Algoritmi + Strutture Dati = Programmi",
Tecniche Nuove, 1987.
[3] Aho, Hopcroft, Ullman: "Data Structures and Algorithms",
1983.
[4] H. Jarvinen: "Object-oriented modeling of reactive systems",
Proceedings ACM Conference on Software Engineering, 1990.
[5] J. Rumbaugh: "Object-Oriented Modeling and Design", Prentice
Hall, 1991.
[6] Ebert, Engels: "Observable or Invocable Behaviour - You Have
to Choose", Technical Reports, Leiden University, 1994.
[7] Hopcroft, Ullman: "Introduction to Automata Theory, Languages
and Computation", Addison-Wesley, 1979.
[8] Wilde, Chapman, Matthews, Huitt: "Describing Object Oriented
Software: What Maintainers Need to Know", Technical Report, University
of West Florida, 1992.
[9] C. A. R. Hoare: "Communicating Sequential Processes",
Prentice Hall, 1985.
[10] O. Nierstrasz: "Toward an Object Calculus", Proceedings
ECOOP'91 Workshop on Object-Based Concurrent Computing, Springer-Verlag.
[11] Iseult White: "Using the Booch Method: a Rational Approach",
Benjamin/Cummings, 1994.
[12] Darrel Ince: "Programmazione ad oggetti in C++, Metodi di
Ingegneria del Software", McGraw-Hill, 1992.
Biografia
Carlo Pescio svolge attività di consulenza in ambito internazionale
sulle metodologie di sviluppo Object Oriented e di programmazione
in ambiente Windows. È laureato in Scienze dell'Informazione,
membro dell'Institute of Electrical and Electronics Engineers
Computer Society, dei Comitati Tecnici IEEE su Linguaggi Formali,
Software Engineering e Medicina Computazionale, dell'ACM e dell'Academy
of Sciences di New York. Può essere contattato tramite
la redazione o su Internet come
pescio@programmers.net