Architettura di Sistemi Reattivi, Parte 1
|
|
Dr. Carlo Pescio Architettura di Sistemi Reattivi, Parte 1 |
Pubblicato su Computer Programming No. 68
Chi ha seguito la mia vecchia serie di articoli sulla tecnologia
ad oggetti (Computer Programming No. 34 - 45) sa bene che uno
dei passi fondamentali della progettazione è il
cosiddetto design architetturale. L'architettura del sistema determina
le sue possibilità di crescita e di evoluzione, e fornisce
una collocazione ideale per ogni elemento strutturale. Proprio
come in una struttura abitativa non avviene (normalmente) di trovare
una finestra nel pavimento, così un prodotto software fondato
su una architettura solida tenderà a crescere in
modo naturale ed omogeneo, anziché degenerare nel caos
delle soluzioni improvvisate.
Naturalmente, la progettazione architetturale non è semplice.
Oltre alla necessaria competenza, è necessario acquisire
un senso estetico che guidi verso una soluzione elegante, permeata
da quella qualità senza nome che tutti sappiamo
riconoscere ma che è così difficile introdurre in
un progetto.
Pensando ad alcuni articoli sul design architetturale, avrei voluto
discutere un sistema reale, scelto fra i progetti che ho contribuito
a portare a termine. Purtroppo, i soliti vincoli di riservatezza
non mi consentono di diffondere i dettagli di tali progetti. Ho
quindi deciso di affrontare il tema in senso più generale,
discutendo le scelte di progettazione comuni ad una grande classe
di sistemi, detti normalmente sistemi reattivi. Naturalmente,
ho integrato nell'articolo l'esperienza che deriva dall'aver progettato
sistemi simili in molti settori diversi. Il risultato sarà
il design di un sistema non banale, che seppure non reale
è comunque fortemente realistico.
Sistemi reattivi
Un sistema è detto reattivo quando il suo comportamento
è influenzato da eventi che hanno luogo nel mondo reale,
al di fuori dei computer che governano il sistema stesso. In risposta
a tali eventi, il sistema aggiorna il suo stato e risponde con
un feedback che nuovamente influenza il mondo esterno. Esempi
tipici di sistemi reattivi sono gli impianti di controllo industriale,
ma problematiche del tutto analoghe si riscontrano, ad esempio,
nel software di controllo della rete bancomat o delle centrali
telefoniche, in alcune apparecchiature biomediche, nei sistemi
di realtà virtuale, ed in molte altre situazioni. Una categoria
molto ampia di sistemi reattivi è rappresentata dai sistemi
embedded, che si stanno sempre più innestando nella vita
di ogni giorno: le automobili, gli elettrodomestici, i telefoni
(tanto per citare qualche esempio) sono sempre più ricchi
di "elettronica intelligente".
In genere un sistema reattivo ha una componente real-time, in
quanto gli stimoli esterni devono essere gestiti entro tempistiche
stabilite. Per la sua natura tipicamente mission-critical, un
sistema reattivo richiede inoltre una particolare attenzione al
design for testability: ad esempio, la possibilità
di operare in regime di simulazione deve spesso far parte delle
capacità intrinseche del sistema. Altre caratteristiche
tipiche di un buon sistema reattivo sono la high availability
(in teoria, dovrebbe essere sempre operativo, anche a fronte di
problemi interni od esterni) e la semplicità di estensione
ed adattamento a situazioni diverse (soprattutto per i sistemi
di controllo industriale, che si trovano ad operare in ambienti
estremamente eterogenei e soggetti a frequenti modifiche dei requisiti).
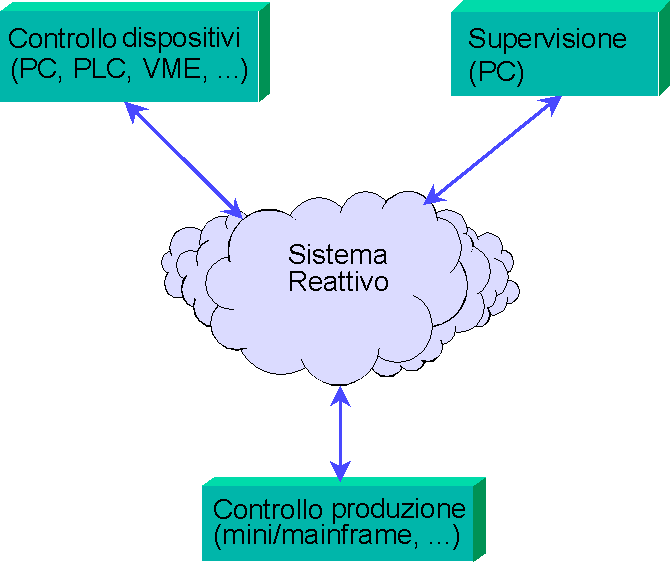
La struttura di massima che prenderò in esame sarà
quella di figura 1, orientata a problematiche di tipo CIM (Computer
Integrated Manufacturing). Possiamo vedere come diversi dispositivi
di I/O verso il mondo fisico (indicati con "controllo dispositivi")
si interfaccino con il sistema reattivo, informandolo degli eventi
e ricevendo comandi. I dispositivi che si incontrano più
frequentemente sul campo sono i PLC (Programmable Logic Controller),
tipicamente connessi tramite porte seriali, oppure dei PC con
schede di I/O programmabili. Non è comunque raro trovarsi
di fronte a box Unix/VME, o a dispositivi hardware custom con
uscite seriali: un buon sistema reattivo deve facilmente adattarsi
a ricevere input da sorgenti diverse.
Un ulteriore sistema, spesso rappresentato da un mini-computer
o da un mainframe, fornisce le informazioni relative alla produzione
e riceve gli aggiornamenti via via che il processo avanza. Spesso
la stessa macchina mantiene il database degli ordini, dei clienti,
ed altri aspetti contabili della produzione. La connessione varia
dalla rete ethernet ad una emulazione di terminale, ed anche in
questo caso il sistema reattivo deve essere sufficientemente flessibile
nell'interfacciarsi con il controllo di produzione. Infine, il
sistema reattivo fornisce una serie di informazioni di stato ad
una macchina di supervisione, molto spesso un personal con un
package di tipo SCADA (Supervisory Control And Data Acquisition).
In tempi più recenti, ho provato con un discreto successo
ad abbandonare gli SCADA in favore di una composizione on-the-fly
di pagine html accoppiata ad un browser sul lato supervisore.
Il sistema reattivo, rappresentato dalla nuvoletta centrale, non
deve necessariamente risiedere su un'unica macchina: anzi, non
di rado dovremo prevedere la possibilità di scalare il
sistema su più computer. Riassumiamo quindi le caratteristiche
che desideriamo per il nostro sistema reattivo:
Come vedremo, la tecnologia ad oggetti è uno strumento ideale per raggiungere questi obiettivi, attraverso la creazione di un framework misto black-box e white box [Pes98a].
Lo strato esterno
Iniziamo ora ad identificare i principali elementi del sistema
reattivo. Il primo punto di variabilità del sistema è
dovuto al grande numero di dispositivi esterni. Si tratta in gran
parte di elementi fuori dal nostro controllo, già insediati
negli impianti esistenti e pertanto praticamente impossibili da
standardizzare. Un obiettivo importante è quindi l'isolamento
di tale variabilità, che deve essere opportunamente nascosta
da una interfaccia resiliente.
Nel paradigma ad oggetti, questo è facilmente ottenibile
attraverso una classe interfaccia [Pes97] che definisce solo le
funzionalità di più alto livello (configurazione,
lettura, scrittura, verifica di eventuali errori, reset della
periferica), demandando l'intera implementazione alle classi derivate
(figura 2). Le classi derivate permettono di dialogare con un
dispositivo collegato tramite porta seriale, o su rete con comunicazione
tramite socket, o con netbios, o con named pipe, e così
via. Se confrontiamo le varie classi derivate con i livelli ISO/OSI,
esse risultano di norma eterogenee: non sempre la pratica riflette
i modelli proposti dalla teoria, ed il nostro sistema è
modellato per risolvere i problemi reali di interfacciamento a
periferiche diverse, dalla schedina a microprocessore al mainframe.
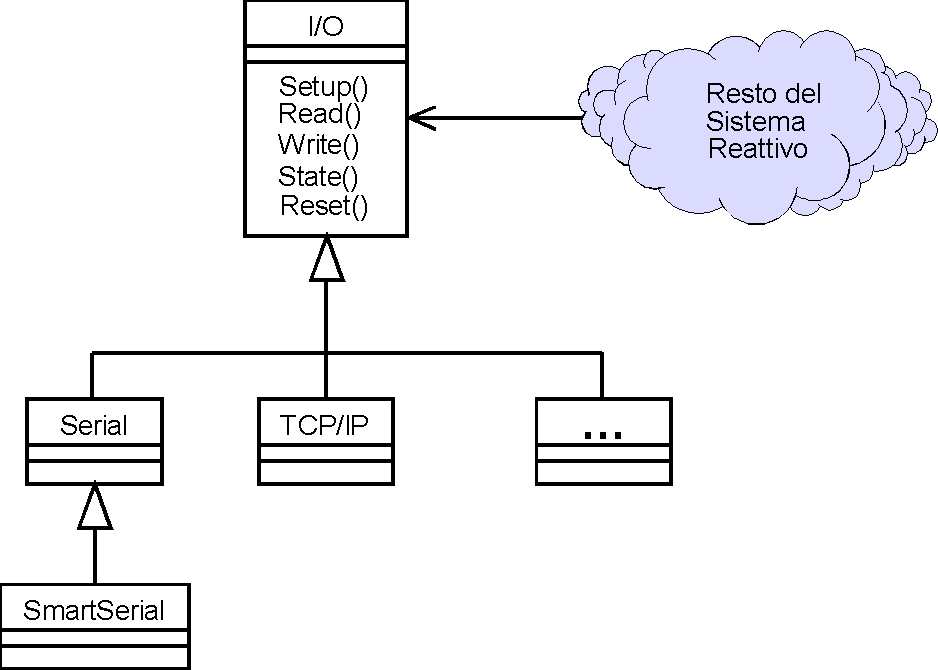
La struttura di figura 2 è totalmente estendibile, anche
se dobbiamo ancora risolvere qualche problema di realizzabilità
(che vedremo in dettaglio nelle prossime puntate). Idealmente,
ogni classe concreta sarà contenuta in una libreria a caricamento
dinamico (DLL), che verrà specificata in un file di configurazione.
In questo modo, possiamo cambiare il tipo di comunicazione con
un dispositivo semplicemente aggiornando un file esterno: ad esempio,
se passiamo da un PLC collegato via seriale ad uno collegato su
rete ethernet, in teoria dovremmo essere in grado di adattare
il sistema attraverso qualche modifica alla configurazione.
Naturalmente, la realtà non è così semplice.
Occorre stabilire con precisione cosa significano "lettura"
e "scrittura" a livello della classe I/O. Fondamentalmente
abbiamo due scelte: la classe I/O conosce la struttura dei messaggi
da/verso il dispositivo, oppure la classe I/O conosce solo i dettagli
del protocollo di dialogo con il dispositivo (es. RS 232) ma non
i contenuti.
Evidentemente, se vogliamo ottenere la massima riusabilità
delle classi concrete di I/O e la massima configurabilità
del sistema, ogni classe I/O deve occuparsi solo del trasferimento
dei dati in formato raw, senza alcuna conoscenza della
struttura dei messaggi. In caso contrario, non potremmo usare
la stessa classe SerialIO per comunicare con due dispositivi connessi
a porte seriali, ma con formato dei messaggi diverso.
Questo significa però rinunciare ad una parte di conoscenza
sul sistema: ad esempio, se sappiamo che un dispositivo manderà
sempre sequenze di 512 byte in modalità burst, ed
arrivano invece 200 byte seguiti da un silenzio di (es.) tre secondi,
dovremmo considerare il messaggio come "perso". La gestione
dei ritardi sarebbe molto semplice all'interno della classe I/O,
ma se disaccoppiamo l'I/O raw dalla gestione dei messaggi
(tipicamente tramite una coda implementata come buffer circolare)
rischiamo seriamente di perdere questo tipo di controllo.
Le soluzioni sono apparentemente due: o riusciamo ad utilizzare
la struttura dei messaggi per "ricostruirli" a partire
dal contenuto della coda, senza fare riferimento a ritardi et
similia, o dobbiamo arricchire l'interfaccia di I/O per consentire
un maggiore controllo. In genere, io prediligo il primo approccio
(con una variante che vedremo tra breve). Infatti, se vogliamo
realmente essere indipendenti dal tipo di connessione, non possiamo
legare il riconoscimento dei messaggi alle tempistiche: una rete
o una porta seriale si comportano in modo molto diverso. Quando
questo non è possibile (ad es. alcuni vecchi protocolli
usano necessariamente i ritardi intercarattere) la soluzione ideale
è comunque un'altra: aggiungere una ulteriore specializzazione
della classe di I/O concreta. Ad esempio, se il nostro protocollo
prevede una comunicazione seriale, e richiede l'analisi dei tempi
per separare i messaggi, anziché complicare l'interfaccia
di I/O, ed anziché legare le parti interne del sistema
reattivo a dettagli soggetti a variazione, creiamo una classe
derivata da SerialI/O che conosce (in parte) il formato dei messaggi.
Questa SmartSerialI/O (si veda sempre la figura 2) verrà
vista dal sistema reattivo come una I/O qualsiasi, ma non metterà
messaggi parziali nella coda: userà invece la sua conoscenza
per riconoscere i messaggi errati, ed inserirà nella coda
solo messaggi completi. Se cambiamo il tipo di connessione, mantenendo
il formato dei messaggi ma cambiando i dettagli di tempistica,
dobbiamo comunque cambiare solo un componente esterno.
Chi ha seguito il mio corso di Systematic Object Oriented Design
potrà riconoscere l'applicazione di una delle tecniche
di trasformazioni elementari (PushDown Completo) per evitare di
esporre dettagli interni di I/O. Se avessimo scelto la strada
"ovvia", ovvero l'arricchimento dell'interfaccia della
classe I/O e la conseguente esposizione di più dettagli
interni, nelle stesse condizioni avremmo dovuto cambiare un modulo
interno (almeno nella struttura attuale), ovvero il riconoscitore
dei messaggi.
Lo strato esterno di I/O ha anche una ulteriore, importante funzione:
la separazione tra hard e soft real-time. Una delle domande più
frequenti che mi viene rivolta da chi inizia a strutturare un
sistema reattivo secondo il modello ad oggetti è: "Come
faccio ad associare una member function ad un interrupt?".
La risposta giusta è quasi sempre: "non farlo".
Normalmente, una classe concreta di I/O si appoggia su un driver,
che gestisce l'hardware di collegamento vero e proprio. All'interno
del driver gestiamo gli interrupt e risolviamo tutte le problematiche
di hard real-time. L'interfaccia tra driver e classe concreta
di I/O è tipicamente un buffer, eventualmente con un semaforo
per la notifica. Fuori dalla classe concreta di I/O, i tempi di
reazione sono normalmente più lunghi: per rispondere ad
un interrupt vogliamo sprecare pochi nanosecondi, ma per rispondere
ad un intero messaggio da un dispositivo abbiamo in genere diversi
millisecondi.
Questo tipo di sistemi è basato su un pattern noto come
"Half-Synch/Half-Async" [SC96]. Lo "strato esterno"
e quindi a sua volta composto da due strati, uno di basso livello
ed implementato tipicamente come driver di sistema, ed uno di
alto livello implementato come classe (tipicamente in un linguaggio
ad elevate prestazioni come il C++).
Notiamo che lo strato esterno, che viene spesso detto (impropriamente,
ma espressivamente) "livello fisico", isola anche il
resto del sistema reattivo dalla comunicazione con i vari elementi
del mondo reale. L'isolamento è per ora solo apparente,
in quanto le restanti parti del sistema reattivo devono comunque
conoscere il formato dei messaggi, la logica di gestione di ogni
messaggio, eccetera. Si tratta nuovamente di elementi di variabilità
che dovremo gestire opportunamente.
Infine, notiamo che attraverso la virtualizzazione dei dettagli
"fisici" del mondo esterno abbiamo anche ottenuto una
migliore testabilità del sistema. Possiamo usare una classe
concreta di I/O "file" per pilotare in modo batch il
sistema reattivo e verificarne il comportamento. Possiamo anche
usare un "simulatore software" più complesso
ed interattivo, connesso tramite una classe concreta di I/O "pipe",
per testare più a fondo il sistema. Questo tipo di strumenti
si rivela utile anche in fase di installazione, come ausilio per
risolvere eventuali malfunzionamenti: diventa più facile
capire se si tratta di un problema di comunicazione a basso livello
(quindi delle classi di I/O concrete) o localizzata nel resto
del sistema reattivo.
Un'ultima, importante nota prima di proseguire nella progettazione:
il diagramma di figura 2 rappresenta (come tutti i diagrammi
delle classi) una visione statica del sistema. Può trarre
in inganno chi non è abituato a leggere i diagrammi UML,
e suggerire che vi sia un unico oggetto I/O nell'intero
sistema reattivo. Naturalmente non è così: vi saranno
molti oggetti di classe derivata da I/O, tipicamente uno per ogni
dispositivo esterno. Questo andrà sempre tenuto presente
via via che proseguiremo con la progettazione.
Verso l'interno
Scendiamo ora ulteriormente all'interno della nuvoletta, cercando
di fornire uno strato estendibile per la gestione dei messaggi.
Ci preoccuperemo del versante opposto (la scrittura da parte del
sistema reattivo verso il mondo esterno) nelle prossime puntate.
Se le classi concrete di I/O ci forniscono un trasferimento raw
dei dati inviati dai dispositivi esterni, il primo compito da
svolgere al livello successivo è di trasformare questa
sequenza di byte in messaggi completi, pronti per essere gestiti
dal sistema. A questo punto incontriamo diversi elementi di variabilità.
Sicuramente, passando da un sistema ad un altro, capiterà
di dover riconoscere diversi tipi di messaggio: i dispositivi
esterni cambiano molto frequentemente. Può anche capitare
che un messaggio logicamente equivalente (ad es. "pezzo scartato"
proveniente da una macchina a controllo numerico) sia rappresentato
da sequenze di byte diverse tra un sistema e l'altro. Infine,
può facilmente capitare che lo stesso messaggio logico
debba essere gestito in modo diverso tra un impianto e l'altro.
Non sorprende quindi la tendenza piuttosto diffusa a considerare
ogni impianto CIM come "unico nel suo genere", ed a
costruirlo quasi da zero, oppure "cannibalizzando" progetti
precedenti alla ricerca di un riuso Copy&Paste. È proprio
qui che interviene l'importanza di una buona architettura.
Iniziamo con l'introdurre una classe astratta Parser, da cui vengono
derivate le classi concrete che riconoscono i messaggi per ogni
dispositivo esterno (figura 3). L'importanza di Parser verrà
chiarita tra poco: per ora, pensiamo che serva al sistema come
astrazione di un elemento di variabilità. I vari DeviceDependentParser
saranno probabilmente implementati come macchine a stati. Nei
casi più semplici (ad esempio, messaggi a lunghezza fissa),
la macchina ha solo tre stati: messaggio completo e riconosciuto,
messaggio incompleto, messaggio errato. Nei casi più complessi,
esistono molti stati e il riconoscimento dei messaggi dipende
dallo stato in cui ci si trova. Vediamo un semplice esempio: se
i messaggi hanno un header standard e lunghezza variabile, riconosciuto
l'header si entra in uno stato diverso, in cui anche i caratteri
che di norma compongono l'header vengono riconosciuti come parte
del corpo, sino a quando non si raggiunge la fine del messaggio
e si torna allo stato iniziale.
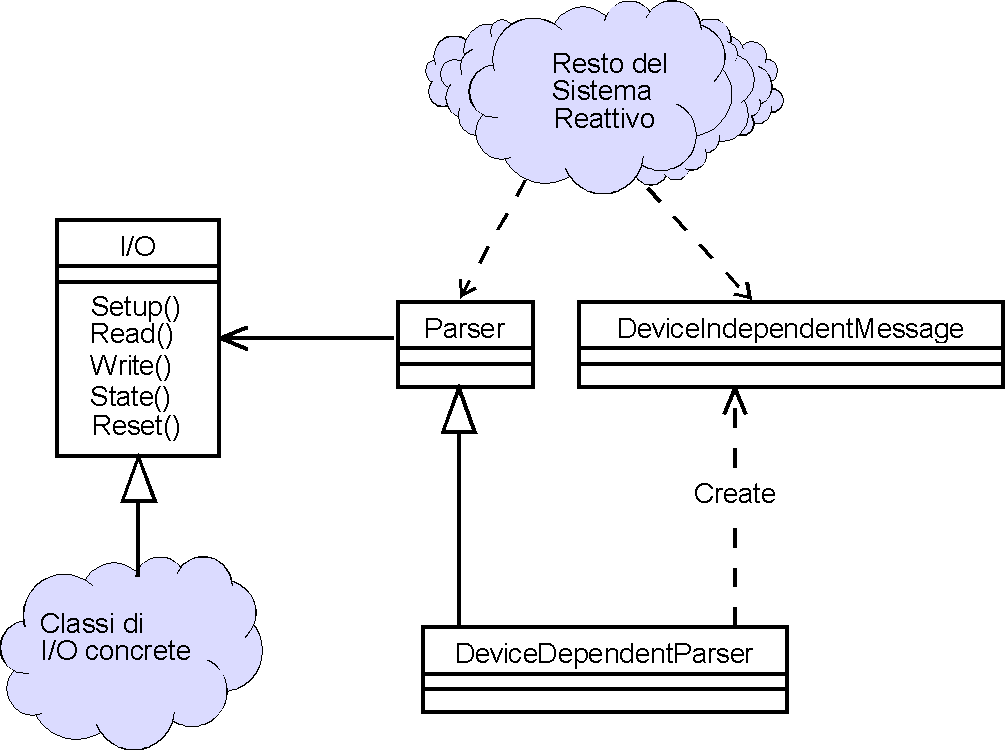
L'implementazione delle macchine a stati non verrà presa
in considerazione in questa serie di articoli. Esistono molte
alternative interessanti nel paradigma ad oggetti, dal semplice
pattern State [GoF95] alle macchine a stati a tre livelli [Mar95],
sino a macchine a stati componibili [SC95]. Molto spesso, esigenze
di performance finiscono per far pendere la bilancia in favore
degli approcci più semplici ed hard-coded: nella nostra
struttura, non si tratta di un grande problema, in quanto il parser
dei messaggi è comunque una classe isolata, possibilmente
implementata in una libreria a caricamento dinamico. Questo riporta
immediatamente all'utilità della classe astratta Parser:
se i parser device-dependent sono in librerie a caricamento dinamico,
il resto del sistema non può neppure conoscere i
nomi delle classi in esse contenute. È allora indispensabile
(e lo vedremo ancora meglio fra breve) che al di fuori delle DLL
tali classi vengano viste attraverso una interfaccia stabile,
rappresentata dalla classe astratta Parser.
Il parser device-dependent genera un messaggio device-independent.
È importante capire bene il ruolo di questo passaggio:
molte volte eventi del tutto simili (completamento di un pezzo,
scarti, passaggio ad una fase successiva) vengono comunicati dai
diversi dispositivi in modo diverso. Il ruolo delle tre nuove
classi che abbiamo introdotto in figura 3 è di disaccoppiare
il messaggio logico dai dettagli dipendenti dalla periferica.
Possiamo dire che, mentre la classe I/O serve a fornire un'astrazione
dell'interfaccia verso il device, le classi Parser e DeviceIndependentMessage
servono a fornire un'astrazione del device stesso.
Naturalmente, non siamo costretti ad implementare tale
strato di astrazione per ogni device: se siamo sicuri che
un certo tipo di dispositivo sia fisso per tutti i nostri impianti,
possiamo tranquillamente lavorare in termini di messaggi device-dependent.
In genere, questo tipo di semplificazione torna indietro a perseguitarci
nei progetti successivi, ma qui si introducono una serie di valutazioni
sui rischi del progetto che è meglio rimandare ad altra
sede.
Abbiamo per ora raggiunto due degli obiettivi di cui sopra: possiamo
facilmente cambiare il riconoscitore dei messaggi per adattarci
a nuovi dispositivi, e possiamo continuare a vedere messaggi di
più alto livello all'interno del sistema. Dobbiamo ancora
pensare alla gestione di tali messaggi, compreso il feedback
verso la sorgente, che come abbiamo visto costituisce un ulteriore
punto di variabilità. Di questo ci occuperemo nella prossima
puntata, in quanto dobbiamo ancora soffermarci su un elemento
centrale del progetto.
Modelli di concorrenza
Il diagramma di figura 3 è un po' anomalo perché
non compare alcun oggetto attivo. Non compare neanche la tipica
classe Thread, pressoché indispensabile in un sistema reattivo
implementato con linguaggi ad oggetti "classici" dal
punto di vista della concorrenza [Pes98b].
La mancanza è voluta, perché dobbiamo ora compiere
una importante scelta architetturale. Possiamo rendere ogni parser
un oggetto attivo (un thread), che rimane in attesa di input dalla
classe di I/O a lui associata, crea un messaggio device-independent,
e lo gestisce nel suo contesto di esecuzione. In questo modo non
possiamo leggere/creare nuovi messaggi sino a quando non abbiamo
completato la gestione del messaggio corrente.
Alternativamente, possiamo avere un unico thread di lettura per
tutti gli oggetti di I/O, fermo in attesa di dati da uno
qualunque di essi. Quando arrivano i dati, esegue il codice del
parser associato nel proprio contesto di esecuzione, ma fa partire
un nuovo thread per gestire i messaggi completi. In questo modo
la sola fase bloccante è il parsing di un messaggio, ma
non la sua gestione (che si suppone più lunga); questa
soluzione è fondamentalmente basata sul pattern Reactor
[Sch95]. Notiamo che in questo caso l'importanza della classe
astratta Parser diviene ancora più chiara, in quanto il
thread di lettura si interfaccia con i vari parser concreti (che
non conosce) proprio attraverso questa interfaccia.
Infine possiamo scegliere la soluzione a maggior parallelismo
interno: ogni parser viene associato ad un thread, e la gestione
di ogni messaggio riconosciuto viene a sua volta associata ad
un nuovo thread, eventualmente con un pooling. Nuovamente, la
classe Parser si rivela importante: è attraverso di essa
che i parser concreti ereditano lo status di oggetto attivo.
La scelta fra le tre alternative non è semplice, né
può essere facilmente fattorizzata al di fuori del framework
applicativo che stiamo costruendo. In genere, la prima soluzione
funziona bene solo quando i dispositivi collegati si basano su
un protocollo mono-direzionale, nel qual caso è decisamente
la più efficiente. La seconda è particolarmente
adatta ai casi in cui la frequenza con cui ogni dispositivo dialoga
con il sistema è bassa: a quel punto, evitiamo di avere
molti thread sospesi usandone uno solo per tutti i dispositivi.
In tutti gli altri casi, la terza soluzione è la migliore,
anche se richiede una attenzione maggiore alla sincronizzazione
tra i vari thread. Peraltro, se la associamo ad una tecnica di
pooling dei thread, possiamo comunque effettuare un tuning adeguato
per l'hardware su cui deve girare il sistema.
Conclusioni
Dovendo prendere una decisione generale, indipendente dalle caratteristiche
peculiari dei vari sistemi, baserò il framework sulla terza
soluzione (a parallelismo massimo con pooling). Nella prossima
puntata, completeremo il diagramma delle classi specificando gli
oggetti attivi, il pool dei thread, e vedremo come gestire in
modo estendibile ed allo stesso tempo con il massimo di riusabilità
i messaggi device-independent. Riprenderemo anche le problematiche
di design for testability, che abbiamo solo accennato in questa
puntata. Più avanti completeremo il ciclo, fornendo il
necessario feedback al mondo esterno, e scenderemo in alcuni importanti
particolari di design (come le responsabilità di istanziazione),
fondamentali per creare un sistema che sia non solo elegante ma
anche effettivamente realizzabile.
Biografia
Carlo Pescio svolge attivitŕ di consulenza e formazione in ambito internazionale nel
campo delle tecnologie Object Oriented. Ha svolto la funzione di Software Architect in
grandi progetti per importanti aziende europee e statunitensi. Č l’ideatore del metodo
di design ad oggetti SysOOD (Systematic Object Oriented Design), ed autore di numerosi
articoli su temi di ingegneria del software, programmazione C++ e tecnologia ad oggetti,
apparsi sui principali periodici statunitensi. Laureato in Scienze dell’Informazione,
č membro dell’ACM e dell’IEEE.
Bibliografia
[GoF95] Gamma ed altri, "Design Patterns", Addison-Wesley,
1995.
[Mar95] Robert Martin, "Three Level FSM", in Pattern
Languages of Program Design Vol. 1, Addison-Wesley, 1995.
[Pes97] Carlo Pescio, "Oggetti ed Interfacce", Computer
Programming No. 63.
[Pes98a] Carlo Pescio, "Oggetti e Componenti COM", Computer
Programming No. 67.
[Pes98b] Carlo Pescio, "Oggetti e Thread", Computer
Programming No. 65.
[SC95] Aamod Sane, Roy Campbell, "Object-Oriented State Machines:
Subclassing, Composition, Delegation, and Genericity", Proceedings
of ACM OOPSLA '95.
[SC96] Douglas C. Schmidt, Charles D. Cranor: "Half-Sync/Half-Async:
An Architectural Pattern for Efficient and Well-Structured Concurrent
I/O", in Pattern Languages of Program Design Vol. 2, Addison-Wesley,
1996.
[Sch95] Douglas C. Schmidt, "Reactor: An Object Behavioral
Pattern for Concurrent Event Demultiplexing and Event Handler
Dispatching", in Pattern Languages of Program Design Vol.
1, Addison-Wesley, 1995.